
Publications
Incremental Object Discovery in Time-Varying Image Collections
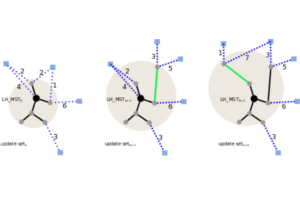
In this paper, we address the problem of object discovery in time-varying, large-scale image collections. A core part of our approach is a novel Limited Horizon Minimum Spanning Tree (LH-MST) structure that closely approximates the Minimum Spanning Tree at a small fraction of the latter’s computational cost. Our proposed tree structure can be created in a local neighborhood of the matching graph during image retrieval and can be efficiently updated whenever the image database is extended. We show how the LH-MST can be used within both single-link hierarchical agglomerative clustering and the Iconoid Shift framework for object discovery in image collections, resulting in significant efficiency gains and making both approaches capable of incremental clustering with online updates. We evaluate our approach on a dataset of 500k images from the city of Paris and compare its results to the batch version of both clustering algorithms.
Non-Linear Shape Optimization Using Local Subspace Projections
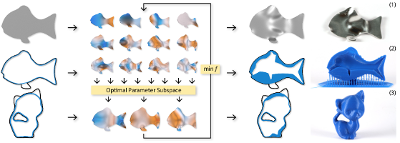
In this paper we present a novel method for non-linear shape opti- mization of 3d objects given by their surface representation. Our method takes advantage of the fact that various shape properties of interest give rise to underdetermined design spaces implying the existence of many good solutions. Our algorithm exploits this by performing iterative projections of the problem to local subspaces where it can be solved much more efficiently using standard numer- ical routines. We demonstrate how this approach can be utilized for various shape optimization tasks using different shape parameteri- zations. In particular, we show how to efficiently optimize natural frequencies, mass properties, as well as the structural yield strength of a solid body. Our method is flexible, easy to implement, and very fast.
@article{Musialski:2016:ShapeOpt,
author = "Musialski, Przemyslaw and Hafner, Christian and Rist, Florian and Birsak, Michael and Wimmer, Michael and Kobbelt, Leif",
title = "Non-Linear Shape Optimization Using Local Subspace Projections",
journal = "ACM Transactions on Graphics",
volume = 35,
number = 4,
year = 2016
}
HexEx: Robust Hexahedral Mesh Extraction

State-of-the-art hex meshing algorithms consist of three steps: Frame-field design, parametrization generation, and mesh extraction. However, while the first two steps are usually discussed in detail, the last step is often not well studied. In this paper, we fully concentrate on reliable mesh extraction.
Parametrization methods employ computationally expensive countermeasures to avoid mapping input tetrahedra to degenerate or flipped tetrahedra in the parameter domain because such a parametrization does not define a proper hexahedral mesh. Nevertheless, there is no known technique that can guarantee the complete absence of such artifacts.
We tackle this problem from the other side by developing a mesh extraction algorithm which is extremely robust against typical imperfections in the parametrization. First, a sanitization process cleans up numerical inconsistencies of the parameter values caused by limited precision solvers and floating-point number representation. On the sanitized parametrization, we extract vertices and so-called darts based on intersections of the integer grid with the parametric image of the tetrahedral mesh. The darts are reliably interconnected by tracing within the parametrization and thus define the topology of the hexahedral mesh. In a postprocessing step, we let certain pairs of darts cancel each other, counteracting the effect of flipped regions of the parametrization. With this strategy, our algorithm is able to robustly extract hexahedral meshes from imperfect parametrizations which previously would have been considered defective. The algorithm will be published as an open source library.
@article{Lyon:2016:HexEx,
author = "Lyon, Max and Bommes, David and Kobbelt, Leif",
title = "HexEx: Robust Hexahedral Mesh Extraction",
journal = "ACM Transactions on Graphics",
volume = 35,
number = 4,
year = 2016
}
Interactively Controlled Quad Remeshing of High Resolution 3D Models

Parametrization based methods have recently become very popular for the generation of high quality quad meshes. In contrast to previous approaches, they allow for intuitive user control in order to accommodate all kinds of application driven constraints and design intentions. A major obstacle in practice, however, are the relatively long computations that lead to response times of several minutes already for input models of moderate complexity. In this paper we introduce a novel strategy to handle highly complex input meshes with up to several millions of triangles such that quad meshes can still be created and edited within an interactive workflow. Our method is based on representing the input model on different levels of resolution with a mechanism to propagate parametrizations from coarser to finer levels. The major challenge is to guarantee consistent parametrizations even in the presence of charts, transition functions, and singularities. Moreover, the remaining degrees of freedom on coarser levels of resolution have to be chosen carefully in order to still achieve low distortion parametrizations. We demonstrate a prototypic system where the user can interactively edit quad meshes with powerful high-level operations such as guiding constraints, singularity repositioning, and singularity connections.
@article{esck2016,
author = {Ebke, Hans-Christian and Schmidt, Patrick and Campen, Marcel and Kobbelt, Leif},
title = {Interactively Controlled Quad Remeshing of High Resolution 3D Models},
journal = {ACM Trans. Graph.},
issue_date = {November 2016},
volume = {35},
number = {6},
month = nov,
year = {2016},
issn = {0730-0301},
pages = {218:1--218:13},
articleno = {218},
url = {http://doi.acm.org/10.1145/2980179.2982413},
doi = {10.1145/2980179.2982413},
acmid = {2982413},
publisher = {ACM},
address = {New York, NY, USA},
}
Error-Bounded and Feature Preserving Surface Remeshing with Minimal Angle Improvement

The typical goal of surface remeshing consists in finding a mesh that is (1) geometrically faithful to the original geometry, (2) as coarse as possible to obtain a low-complexity representation and (3) free of bad elements that would hamper the desired application. In this paper, we design an algorithm to address all three optimization goals simultaneously. The user specifies desired bounds on approximation error (delta), minimal interior angle (theta) and maximum mesh complexity N (number of vertices). Since such a desired mesh might not even exist, our optimization framework treats only the approximation error bound (delta) as a hard constraint and the other two criteria as optimization goals. More specifically, we iteratively perform carefully prioritized local operators, whenever they do not violate the approximation error bound and improve the mesh otherwise. Our optimization framework greedily searches for the coarsest mesh with minimal interior angle above (theta) and approximation error bounded by (delta). Fast runtime is enabled by a local approximation error estimation, while implicit feature preservation is obtained by specifically designed vertex relocation operators. Experiments show that our approach delivers high-quality meshes with implicitly preserved features and better balances between geometric fidelity, mesh complexity and element quality than the state-of-the-art.
@article{hu2016error,
title={Error-Bounded and Feature Preserving Surface Remeshing with Minimal Angle Improvement.},
author={Hu, K and Yan, DM and Bommes, D and Alliez, P and Benes, B},
journal={IEEE transactions on visualization and computer graphics},
year={2016}
}
Directional Field Synthesis, Design, and Processing
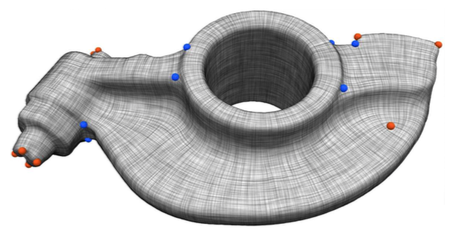
Direction fields and vector fields play an increasingly important role in computer graphics and geometry processing. The synthesis of directional fields on surfaces, or other spatial domains, is a fundamental step in numerous applications, such as mesh generation, deformation, texture mapping, and many more. The wide range of applications resulted in definitions for many types of directional fields: from vector and tensor fields, over line and cross fields, to frame and vector-set fields. Depending on the application at hand, researchers have used various notions of objectives and constraints to synthesize such fields. These notions are defined in terms of fairness, feature alignment, symmetry, or field topology, to mention just a few. To facilitate these objectives, various representations, discretizations, and optimization strategies have been developed. These choices come with varying strengths and weaknesses. This report provides a systematic overview of directional field synthesis for graphics applications, the challenges it poses, and the methods developed in recent years to address these challenges.
PatchIt: Self-supervised Network Weight Initialization for Fine-grained Recognition
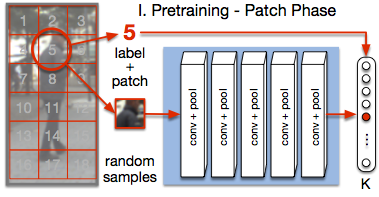
ConvNet training is highly sensitive to initialization of the weights. A widespread approach is to initialize the network with weights trained for a different task, an auxiliary task. The ImageNet-based ILSVRC classification task is a very popular choice for this, as it has shown to produce powerful feature representations applicable to a wide variety of tasks. However, this creates a significant entry barrier to exploring non-standard architectures. In this paper, we propose a self-supervised pretraining, the PatchTask, to obtain weight initializations for fine-grained recognition problems, such as person attribute recognition, pose estimation, or action recognition. Our pretraining allows us to leverage additional unlabeled data from the same source, which is often readily available, such as detection bounding boxes. We experimentally show that our method outperforms a standard random initialization by a considerable margin and closely matches the ImageNet-based initialization.
@InProceedings{Sudowe16BMVC,
author = {Patrick Sudowe and Bastian Leibe},
title = {{PatchIt: Self-Supervised Network Weight Initialization for Fine-grained Recognition}},
booktitle = BMVC,
year = {2016}
}
Unsupervised Learning of Shape-Motion Patterns for Objects in Urban Street Scenes
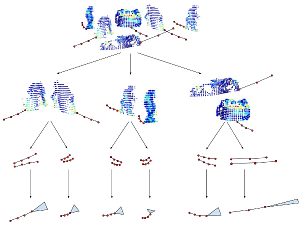
Tracking in urban street scenes is predominantly based on pretrained object-specific detectors and Kalman filter based tracking. More recently, methods have been proposed that track objects by modelling their shape, as well as ones that predict the motion of ob- jects using learned trajectory models. In this paper, we combine these ideas and propose shape-motion patterns (SMPs) that incorporate shape as well as motion to model a vari- ety of objects in an unsupervised way. By using shape, our method can learn trajectory models that distinguish object categories with distinct behaviour. We develop methods to classify objects into SMPs and to predict future motion. In experiments, we analyze our learned categorization and demonstrate superior performance of our motion predictions compared to a Kalman filter and a learned pure trajectory model. We also demonstrate how SMPs can indicate potentially harmful situations in traffic scenarios.
@inproceedings{klostermann2016_smps,
title = {Unsupervised Learning of Shape-Motion Patterns for Objects in Urban Street Scenes},
author = {Dirk Klostermann and Aljosa Osep and J\"org St\"uckler and Bastian Leibe},
booktitle = {Proc. of the British Machine Vision Conference (BMVC)},
year = {2016}, note = {to appear}
}
Scene Flow Propagation for Semantic Mapping and Object Discovery in Dynamic Street Scenes

Scene understanding is an important prerequisite for vehicles and robots that operate autonomously in dynamic urban street scenes. For navigation and high-level behavior planning, the robots not only require a persistent 3D model of the static surroundings - equally important, they need to perceive and keep track of dynamic objects. In this paper, we propose a method that incrementally fuses stereo frame observations into temporally consistent semantic 3D maps. In contrast to previous work, our approach uses scene flow to propagate dynamic objects within the map. Our method provides a persistent 3D occupancy as well as semantic belief on static as well as moving objects. This allows for advanced reasoning on objects despite noisy single-frame observations and occlusions. We develop a novel approach to discover object instances based on the temporally consistent shape, appearance, motion, and semantic cues in our maps. We evaluate our approaches to dynamic semantic mapping and object discovery on the popular KITTI benchmark and demonstrate improved results compared to single-frame methods.
@inproceedings{kochanov2016_sceneflowprop,
title = {Scene Flow Propagation for Semantic Mapping and Object Discovery in Dynamic Street Scenes},
author = {Deyvid Kochanov and Aljosa Osep and J\"org St\"uckler and Bastian Leibe},
booktitle = {Proc. of the IEEE Int. Conf. on Intelligent Robots and Systems (IROS)}, year = {2016},
note = {to appear}
}
Joint Object Pose Estimation and Shape Reconstruction in Urban Street Scenes Using 3D Shape Priors

Estimating the pose and 3D shape of a large variety of instances within an object class from stereo images is a challenging problem, especially in realistic conditions such as urban street scenes. We propose a novel approach for using compact shape manifolds of the shape within an object class for object segmentation, pose and shape estimation. Our method first detects objects and estimates their pose coarsely in the stereo images using a state-of-the-art 3D object detection method. An energy minimization method then aligns shape and pose concurrently with the stereo reconstruction of the object. In experiments, we evaluate our approach for detection, pose and shape estimation of cars in real stereo images of urban street scenes. We demonstrate that our shape manifold alignment method yields improved results over the initial stereo reconstruction and object detection method in depth and pose accuracy.
@inproceedings{EngelmannGCPR16_shapepriors,
title = {Joint Object Pose Estimation and Shape Reconstruction in Urban Street Scenes Using {3D} Shape Priors},
author = {Francis Engelmann and J\"org St\"uckler and Bastian Leibe},
booktitle = {Proc. of the German Conference on Pattern Recognition (GCPR)},
year = {2016}}
Multi-Scale Object Candidates for Generic Object Tracking in Street Scenes

Most vision based systems for object tracking in urban environments focus on a limited number of important object categories such as cars or pedestrians, for which powerful detectors are available. However, practical driving scenarios contain many additional objects of interest, for which suitable detectors either do not yet exist or would be cumbersome to obtain. In this paper we propose a more general tracking approach which does not follow the often used tracking-by- detection principle. Instead, we investigate how far we can get by tracking unknown, generic objects in challenging street scenes. As such, we do not restrict ourselves to only tracking the most common categories, but are able to handle a large variety of static and moving objects. We evaluate our approach on the KITTI dataset and show competitive results for the annotated classes, even though we are not restricted to them.
@inproceedings{Osep16ICRA,
title={Multi-Scale Object Candidates for Generic Object Tracking in Street
Scenes},
author={O\v{s}ep, Aljo\v{s}a and Hermans, Alexander and Engelmann, Francis and Klostermann, Dirk and and Mathias, Markus and Leibe, Bastian},
booktitle={ICRA},
year={2016}
}
Adapting Feature Curve Networks to a Prescribed Scale

Feature curves on surface meshes are usually defined solely based on local shape properties such as dihedral angles and principal curvatures. From the application perspective, however, the meaningfulness of a network of feature curves also depends on a global scale parameter that takes the distance between feature curves into account, i.e., on a coarse scale, nearby feature curves should be merged or suppressed if the surface region between them is not representable at the given scale/resolution. In this paper, we propose a computational approach to the intuitive notion of scale conforming feature curve networks where the density of feature curves on the surface adapts to a global scale parameter. We present a constrained global optimization algorithm that computes scale conforming feature curve networks by eliminating curve segments that represent surface features, which are not compatible to the prescribed scale. To demonstrate the usefulness of our approach we apply isotropic and anisotropic remeshing schemes that take our feature curve networks as input. For a number of example meshes, we thus generate high quality shape approximations at various levels of detail.
@inproceedings{gehre2016adapting,
title={Adapting Feature Curve Networks to a Prescribed Scale},
author={Gehre, Anne and Lim, Isaak and Kobbelt, Leif},
booktitle={Computer Graphics Forum},
volume={35},
number={2},
pages={319--330},
year={2016},
organization={Wiley Online Library}
}
Improved Surface Quality in 3D Printing by Optimizing the Printing Direction

We present a pipeline of algorithms that decomposes a given polygon model into parts such that each part can be 3D printed with high (outer) surface quality. For this we exploit the fact that most 3D printing technologies have an anisotropic resolution and hence the surface smoothness varies significantly with the orientation of the surface. Our pipeline starts by segmenting the input surface into patches such that their normals can be aligned perpendicularly to the printing direction. A 3D Voronoi diagram is computed such that the intersections of the Voronoi cells with the surface approximate these surface patches. The intersections of the Voronoi cells with the input model's volume then provide an initial decomposition. We further present an algorithm to compute an assembly order for the parts and generate connectors between them. A post processing step further optimizes the seams between segments to improve the visual quality. We run our pipeline on a wide range of 3D models and experimentally evaluate the obtained improvements in terms of numerical, visual, and haptic quality.
CPA-SLAM: Consistent Plane-Model Alignment for Direct RGB-D SLAM
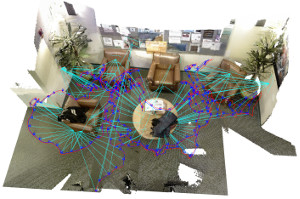
Planes are predominant features of man-made environments which have been exploited in many mapping approaches. In this paper, we propose a real-time capable RGB-D SLAM system that consistently integrates frame-to-keyframe and frame-to-plane alignment. Our method models the environment with a global plane model and – besides direct image alignment – it uses the planes for tracking and global graph optimization. This way, our method makes use of the dense image information available in keyframes for accurate short-term tracking. At the same time it uses a global model to reduce drift. Both components are integrated consistently in an expectation-maximization framework. In experiments, we demonstrate the benefits our approach and its state-of-the-art accuracy on challenging benchmarks.
@InProceedings{lingni16icra,
author = "L. Ma and C. Kerl and J. Stueckler and D. Cremers",
title = "CPA-SLAM: Consistent Plane-Model Alignment for Direct RGB-D SLAM",
booktitle = "Int. Conf. on Robotics and Automation",
year = "2016",
month = "May",
}
Direct Visual-Inertial Odometry with Stereo Cameras
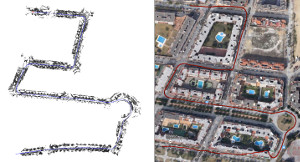
We propose a novel direct visual-inertial odometry method for stereo cameras. Camera pose, velocity and IMU biases are simultaneously estimated by minimizing a combined photometric and inertial energy functional. This allows us to exploit the complementary nature of vision and inertial data. At the same time, and in contrast to all existing visual-inertial methods, our approach is fully direct: geometry is estimated in the form of semi-dense depth maps instead of manually designed sparse keypoints. Depth information is obtained both from static stereo – relating the fixed-baseline images of the stereo camera – and temporal stereo – relating images from the same camera, taken at different points in time. We show that our method outperforms not only vision-only or loosely coupled approaches, but also can achieve more accurate results than state-of-the-art keypoint-based methods on different datasets, including rapid motion and significant illumination changes. In addition, our method provides high-fidelity semi-dense, metric reconstructions of the environment, and runs in real-time on a CPU.
@InProceedings{usenko16icra,
title = "Direct Visual-Inertial Odometry with Stereo Cameras",
author = "V. Usenko and J. Engel and J. Stueckler and D. Cremers",
booktitle = {Int. Conf. on Robotics and Automation},
year = "2016",
}
Position and Orientation Based Cosserat Rods

We present a novel method to simulate bending and torsion of elastic rods within the position-based dynamics (PBD) framework. The main challenge is that torsion effects of Cosserat rods are described in terms of material frames which are attached to the centerline of the rod. But frames or orientations do not fit into the classical position-based dynamics formulation. To solve this problem we introduce new types of constraints to couple orientations which are represented by unit quaternions. For constraint projection quaternions are treated in the exact same way as positions. Unit length is enforced with an additional constraint. This allows us to use the strain measures form Cosserat theory directly as constraints in PBD. It leads to very simple algebraic expressions for the correction displacements which only contain quaternion products and additions. Our results show that our method is very robust and accurately produces the complex bending and torsion effects of rods. Due to its simplicity our method is very efficient and more than one order of magnitude faster than existing position-based rod simulation methods. It even achieves the same performance as position-based simulations without torsion effects.
@INPROCEEDINGS{Kugelstadt2016,
author = {Tassilo Kugelstadt and Elmar Schoemer},
title = {Position and Orientation Based Cosserat Rods},
booktitle = {Proceedings of the 2016 ACM SIGGRAPH/Eurographics Symposium on Computer
Animation},
year = {2016},
publisher = {Eurographics Association},
location = {Zurich, Switzerland}
}
Mobile Manipulation, Tool Use, and Intuitive Interaction for Cognitive Service Robot Cosero

Cognitive service robots that shall assist persons in need of performing their activities of daily living have recently received much attention in robotics research. Such robots require a vast set of control and perception capabilities to provide useful assistance through mobile manipulation and human–robot interaction. In this article, we present hardware design, perception, and control methods for our cognitive service robot Cosero. We complement autonomous capabilities with handheld teleoperation interfaces on three levels of autonomy. The robot demonstrated various advanced skills, including the use of tools. With our robot, we participated in the annual international RoboCup@Home competitions, winning them three times in a row.
@ARTICLE{stueckler2016_cosero,
AUTHOR={St\"uckler, J\"org and Schwarz, Max and Behnke, Sven},
TITLE={Mobile Manipulation, Tool Use, and Intuitive Interaction for Cognitive Service Robot Cosero},
JOURNAL={Frontiers in Robotics and AI},
VOLUME={3},
PAGES={58},
YEAR={2016},
URL={http://journal.frontiersin.org/article/10.3389/frobt.2016.00058},
DOI={10.3389/frobt.2016.00058},
}
MobileVideoTiles: Video Display on Multiple Mobile Devices

Modern mobile phones can capture and process high quality videos, which makes them a very popular tool to create and watch video content. However when watching a video together with a group, it is not convenient to watch on one mobile display due to its small form factor. One idea is to combine multiple mobile displays together to create a larger interactive surface for sharing visual content. However so far a practical framework supporting synchronous video playback on multiple mobile displays is still missing. We present the design of “MobileVideoTiles”, a mobile application that enables users to watch local or online videos on a big virtual screen composed of multiple mobile displays. We focus on improving video quality and usability of the tiled virtual screen. The major technical contributions include: mobile peer-to-peer video streaming, playback synchronization, and accessibility of video resources. The prototype application has got several thousand downloads since release and re ceived very positive feedback from users.
Hierarchical hp-Adaptive Signed Distance Fields

In this paper we propose a novel method to construct hierarchical $hp$-adaptive Signed Distance Fields (SDFs). We discretize the signed distance function of an input mesh using piecewise polynomials on an axis-aligned hexahedral grid. Besides spatial refinement based on octree subdivision to refine the cell size (h), we hierarchically increase each cell's polynomial degree (p) in order to construct a very accurate but memory-efficient representation. Presenting a novel criterion to decide whether to apply h- or p-refinement, we demonstrate that our method is able to construct more accurate SDFs at significantly lower memory consumption than previous approaches. Finally, we demonstrate the usage of our representation as collision detector for geometrically highly complex solid objects in the application area of physically-based simulation.
@INPROCEEDINGS{Koschier2016,
author = {Dan Koschier and Crispin Deul and Jan Bender},
title = {Hierarchical hp-Adaptive Signed Distance Fields},
booktitle = {Proceedings of the 2016 ACM SIGGRAPH/Eurographics Symposium on Computer
Animation},
year = {2016},
publisher = {Eurographics Association},
location = {Zurich, Switzerland}
}
Scale-Invariant Directional Alignment of Surface Parametrizations

Various applications of global surface parametrization benefit from the alignment of parametrization isolines with principal curvature directions. This is particularly true for recent parametrization-based meshing approaches, where this directly translates into a shape-aware edge flow, better approximation quality, and reduced meshing artifacts. Existing methods to influence a parametrization based on principal curvature directions suffer from scale-dependence, which implies the necessity of parameter variation, or try to capture complex directional shape features using simple 1D curves. Especially for non-sharp features, such as chamfers, fillets, blends, and even more for organic variants thereof, these abstractions can be unfit. We present a novel approach which respects and exploits the 2D nature of such directional feature regions, detects them based on coherence and homogeneity properties, and controls the parametrization process accordingly. This approach enables us to provide an intuitive, scale-invariant control parameter to the user. It also allows us to consider non-local aspects like the topology of a feature, enabling further improvements. We demonstrate that, compared to previous approaches, global parametrizations of higher quality can be generated without user intervention.
@article{Campen:2016:ScaleInvariant,
author = "Campen, Marcel and Ibing, Moritz and Ebke, Hans-Christian and Zorin, Denis and Kobbelt, Leif",
title = "Scale-Invariant Directional Alignment of Surface Parametrizations",
journal = "Computer Graphics Forum",
volume = 35,
number = 5,
year = 2016
}
Identifying Style of 3D Shapes using Deep Metric Learning
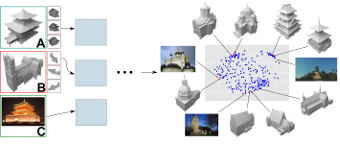
We present a method that expands on previous work in learning human perceived style similarity across objects with different structures and functionalities. Unlike previous approaches that tackle this problem with the help of hand-crafted geometric descriptors, we make use of recent advances in metric learning with neural networks (deep metric learning). This allows us to train the similarity metric on a shape collection directly, since any low- or high-level features needed to discriminate between different styles are identified by the neural network automatically. Furthermore, we avoid the issue of finding and comparing sub-elements of the shapes. We represent the shapes as rendered images and show how image tuples can be selected, generated and used efficiently for deep metric learning. We also tackle the problem of training our neural networks on relatively small datasets and show that we achieve style classification accuracy competitive with the state of the art. Finally, to reduce annotation effort we propose a method to incorporate heterogeneous data sources by adding annotated photos found online in order to expand or supplant parts of our training data.
@article{Lim:2016:StyleLearning,
author = "Lim, Isaak and Gehre, Anne and Kobbelt, Leif",
title = "Identifying Style of 3D Shapes using Deep Metric Learning",
journal = "Computer Graphics Forum",
volume = 35,
number = 5,
year = 2016
}
Accurate and adaptive contact modeling for multi-rate multi-point haptic rendering of static and deformable environments

Common approaches for the haptic rendering of complex scenarios employ multi-rate simulation schemes. Here, the collision queries or the simulation of a complex deformable object are often performed asynchronously at a lower frequency, while some kind of intermediate contact representation is used to simulate interactions at the haptic rate. However, this can produce artifacts in the haptic rendering when the contact situation quickly changes and the intermediate representation is not able to reflect the changes due to the lower update rate.
We address this problem utilizing a novel contact model. It facilitates the creation of contact representations that are accurate for a large range of motions and multiple simulation time-steps. We handle problematic geometrically convex contact regions using a local convex decomposition and special constraints for convex areas. We combine our accurate contact model with an implicit temporal integration scheme to create an intermediate mechanical contact representation, which reflects the dynamic behavior of the simulated objects. To maintain a haptic real time simulation, the size of the region modeled by the contact representation is automatically adapted to the complexity of the geometry in contact. Moreover, we propose a new iterative solving scheme for the involved constrained dynamics problems. We increase the robustness of our method using techniques from trust region-based optimization. Our approach can be combined with standard methods for the modeling of deformable objects or constraint-based approaches for the modeling of, for instance, friction or joints. We demonstrate its benefits with respect to the simulation accuracy and the quality of the rendered haptic forces in several scenarios with one or more haptic proxies.
@Article{Knott201668,
Title = {Accurate and adaptive contact modeling for multi-rate multi-point haptic rendering of static and deformable environments },
Author = {Thomas C. Knott and Torsten W. Kuhlen},
Journal = {Computers \& Graphics },
Year = {2016},
Pages = {68 - 80},
Volume = {57},
Abstract = {Abstract Common approaches for the haptic rendering of complex scenarios employ multi-rate simulation schemes. Here, the collision queries or the simulation of a complex deformable object are often performed asynchronously at a lower frequency, while some kind of intermediate contact representation is used to simulate interactions at the haptic rate. However, this can produce artifacts in the haptic rendering when the contact situation quickly changes and the intermediate representation is not able to reflect the changes due to the lower update rate. We address this problem utilizing a novel contact model. It facilitates the creation of contact representations that are accurate for a large range of motions and multiple simulation time-steps. We handle problematic geometrically convex contact regions using a local convex decomposition and special constraints for convex areas. We combine our accurate contact model with an implicit temporal integration scheme to create an intermediate mechanical contact representation, which reflects the dynamic behavior of the simulated objects. To maintain a haptic real time simulation, the size of the region modeled by the contact representation is automatically adapted to the complexity of the geometry in contact. Moreover, we propose a new iterative solving scheme for the involved constrained dynamics problems. We increase the robustness of our method using techniques from trust region-based optimization. Our approach can be combined with standard methods for the modeling of deformable objects or constraint-based approaches for the modeling of, for instance, friction or joints. We demonstrate its benefits with respect to the simulation accuracy and the quality of the rendered haptic forces in several scenarios with one or more haptic proxies. },
Doi = {http://dx.doi.org/10.1016/j.cag.2016.03.007},
ISSN = {0097-8493},
Keywords = {Haptic rendering},
Url = {http://www.sciencedirect.com/science/article/pii/S0097849316300206}
}
Interactive 3D Force-Directed Edge Bundling
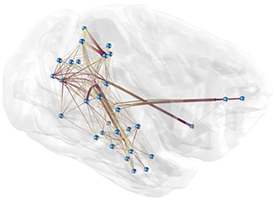
Interactive analysis of 3D relational data is challenging. A common way of representing such data are node-link diagrams as they support analysts in achieving a mental model of the data. However, naïve 3D depictions of complex graphs tend to be visually cluttered, even more than in a 2D layout. This makes graph exploration and data analysis less efficient. This problem can be addressed by edge bundling. We introduce a 3D cluster-based edge bundling algorithm that is inspired by the force-directed edge bundling (FDEB) algorithm [Holten2009] and fulfills the requirements to be embedded in an interactive framework for spatial data analysis. It is parallelized and scales with the size of the graph regarding the runtime. Furthermore, it maintains the edge’s model and thus supports rendering the graph in different structural styles. We demonstrate this with a graph originating from a simulation of the function of a macaque brain.
Visual Quality Adjustment for Volume Rendering in a Head-Tracked Virtual Environment
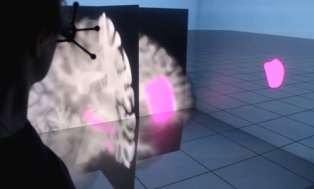
To avoid simulator sickness and improve presence in immersive virtual environments (IVEs), high frame rates and low latency are required. In contrast, volume rendering applications typically strive for high visual quality that induces high computational load and, thus, leads to low frame rates. To evaluate this trade-off in IVEs, we conducted a controlled user study with 53 participants. Search and count tasks were performed in a CAVE with varying volume rendering conditions which are applied according to viewer position updates corresponding to head tracking. The results of our study indicate that participants preferred the rendering condition with continuous adjustment of the visual quality over an instantaneous adjustment which guaranteed for low latency and over no adjustment providing constant high visual quality but rather low frame rates. Within the continuous condition, the participants showed best task performance and felt less disturbed by effects of the visualization during movements. Our findings provide a good basis for further evaluations of how to accelerate volume rendering in IVEs according to user’s preferences.
@article{Hanel2016,
author = { H{\"{a}}nel, Claudia and Weyers, Benjamin and Hentschel, Bernd and Kuhlen, Torsten W.},
doi = {10.1109/TVCG.2016.2518338},
issn = {10772626},
journal = {IEEE Transactions on Visualization and Computer Graphics},
number = {4},
pages = {1472--1481},
pmid = {26780811},
title = {{Visual Quality Adjustment for Volume Rendering in a Head-Tracked Virtual Environment}},
volume = {22},
year = {2016}
}
Examining Rotation Gain in CAVE-like Virtual Environments

When moving through a tracked immersive virtual environment, it is sometimes useful to deviate from the normal one-to-one mapping of real to virtual motion. One option is the application of rotation gain, where the virtual rotation of a user around the vertical axis is amplified or reduced by a factor. Previous research in head-mounted display environments has shown that rotation gain can go unnoticed to a certain extent, which is exploited in redirected walking techniques. Furthermore, it can be used to increase the effective field of regard in projection systems. However, rotation gain has never been studied in CAVE systems, yet. In this work, we present an experiment with 87 participants examining the effects of rotation gain in a CAVE-like virtual environment. The results show no significant effects of rotation gain on simulator sickness, presence, or user performance in a cognitive task, but indicate that there is a negative influence on spatial knowledge especially for inexperienced users. In secondary results, we could confirm results of previous work and demonstrate that they also hold for CAVE environments, showing a negative correlation between simulator sickness and presence, cognitive performance and spatial knowledge, a positive correlation between presence and spatial knowledge, a mitigating influence of experience with 3D applications and previous CAVE exposure on simulator sickness, and a higher incidence of simulator sickness in women.
@ARTICLE{freitag2016a,
author={S. Freitag and B. Weyers and T. W. Kuhlen},
journal={IEEE Transactions on Visualization and Computer Graphics},
title={{Examining Rotation Gain in CAVE-like Virtual Environments}},
year={2016},
volume={22},
number={4},
pages={1462-1471},
doi={10.1109/TVCG.2016.2518298},
ISSN={1077-2626},
month={April},
}
Design and Evaluation of Data Annotation Workflows for CAVE-like Virtual Environments

Data annotation finds increasing use in Virtual Reality applications with the goal to support the data analysis process, such as architectural reviews. In this context, a variety of different annotation systems for application to immersive virtual environments have been presented. While many interesting interaction designs for the data annotation workflow have emerged from them, important details and evaluations are often omitted. In particular, we observe that the process of handling metadata to interactively create and manage complex annotations is often not covered in detail. In this paper, we strive to improve this situation by focusing on the design of data annotation workflows and their evaluation. We propose a workflow design that facilitates the most important annotation operations, i.e., annotation creation, review, and modification. Our workflow design is easily extensible in terms of supported annotation and metadata types as well as interaction techniques, which makes it suitable for a variety of application scenarios. To evaluate it, we have conducted a user study in a CAVE-like virtual environment in which we compared our design to two alternatives in terms of a realistic annotation creation task. Our design obtained good results in terms of task performance and user experience.
Towards the Ultimate Display for Neuroscientific Data Analysis

This article wants to give some impulses for a discussion about how an “ultimate” display should look like to support the Neuroscience community in an optimal way. In particular, we will have a look at immersive display technology. Since its hype in the early 90’s, immersive Virtual Reality has undoubtedly been adopted as a useful tool in a variety of application domains and has indeed proven its potential to support the process of scientific data analysis. Yet, it is still an open question whether or not such non-standard displays make sense in the context of neuroscientific data analysis. We argue that the potential of immersive displays is neither about the raw pixel count only, nor about other hardware-centric characteristics. Instead, we advocate the design of intuitive and powerful user interfaces for a direct interaction with the data, which support the multi-view paradigm in an efficient and flexible way, and – finally – provide interactive response times even for huge amounts of data and when dealing multiple datasets simultaneously.
@InBook{Kuhlen2016,
Title = {Towards the Ultimate Display for Neuroscientific Data Analysis},
Author = {Kuhlen, Torsten Wolfgang and Hentschel, Bernd},
Editor = {Amunts, Katrin and Grandinetti, Lucio and Lippert, Thomas and Petkov, Nicolai},
Pages = {157--168},
Publisher = {Springer International Publishing},
Year = {2016},
Address = {Cham},
Booktitle = {Brain-Inspired Computing: Second International Workshop, BrainComp 2015, Cetraro, Italy, July 6-10, 2015, Revised Selected Papers},
Doi = {10.1007/978-3-319-50862-7_12},
ISBN = {978-3-319-50862-7},
Url = {http://dx.doi.org/10.1007/978-3-319-50862-7_12}
}
Human Factors in Information Visualization and Decision Support Systems
With the increase in data availability and data volume it becomes increasingly important to extract information and actionable knowledge from data. Information Visualization helps the user to understand data by utilizing vision as a relatively parallel input channel to the user’s mind. Decision Support systems on the other hand help users in making information actionable, by suggesting beneficial decisions and presenting them in context. Both fields share a common need for understanding the interface between the computer and the human. This makes human factors research critical for both fields. Understanding limitations of human perception, cognition and action, as well as their variance must be understood to fully leverage information visualization and decision support. This article reflects on research agendas for investigating human factors in the aforementioned fields.
@inproceedings{Valdez2016,
author = {Valdez, André Calero AND Brauner, Philipp AND Ziefle, Martina AND Kuhlen, Torsten Wolfgang AND Sedlmair, Michael},
title = {Human Factors in Information Visualization and Decision Support Systems},
booktitle = {Mensch und Computer 2016 – Workshopband},
year = {2016},
editor = {Weyers, Benjamin AND Dittmar, Anke},
pages = {},
publisher = {Gesellschaft für Informatik e.V.},
address = {Aachen}
}
City Reconstruction and Visualization from Public Data Sources

We present a city reconstruction and visualization framework that integrates geometric models reconstructed with a range of different techniques. The framework generates the vast majority of buildings procedurally, which yields plausible visualizations for structurally simple buildings, e.g. residential buildings. For structurally complex landmarks, e.g. churches, a procedural approach does not achieve satisfactory visual fidelity. Thus, we also employ image-based techniques to reconstruct the latter in a more realistic, recognizable way. As the manual acquisition of data required for the procedural and image-based reconstructions is practically infeasible for whole cities, we rely on publicly available data as well as crowd sourcing projects. This enables our framework to render views from cities without any dedicated data acquisition as long as there are sufficient public data sources available. To obtain a more lively impression of a city, we also visualize dynamic features like weather conditions and traffic based on publicly available real-time data.
Geodesic Iso-Curve Signature
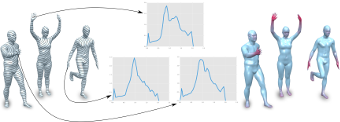
During the last decade a set of surface descriptors have been presented describing local surface features. Recent approaches have shown that augmenting local descriptors with topological information improves the correspondence and segmentation quality. In this paper we build upon the work of Tevs et al. and Sun and Abidi by presenting a surface descriptor which captures both local surface properties and topological features of 3D objects. We present experiments on shape repositories that are provided with ground-truth correspondences (FAUST, SCAPE, TOSCA) which show that this descriptor outperforms current local surface descriptors.
@INPROCEEDINGS{gbk2016,
author = {Gehre, Anne and Bommes, David and Kobbelt, Leif}
title = {Geodesic Iso-Curve Signature},
booktitle = {Vision, Modeling {\&} Visualization},
year = {2016},
publisher = {The Eurographics Association}
}
Deferred Warping

We introduce deferred warping, a novel approach for real-time deformation of 3D objects attached to an animated or manipulated surface. Our target application is virtual prototyping of garments where 2D pattern modeling is combined with 3D garment simulation which allows an immediate validation of the design. The technique works in two steps: First, the surface deformation of the target object is determined and the resulting transformation field is stored as a matrix texture. Then the matrix texture is used as look-up table to transform a given geometry onto a deformed surface. Splitting the process in two steps yields a large flexibility since different attachment types can be realized by simply defining specific mapping functions. Our technique can directly handle complex topology changes within the surface. We demonstrate a fast implementation in the vertex shading stage allowing the use of highly decorated surfaces with millions of triangles in real-time.
@ARTICLE{Knuth2016,
author={Martin Knuth and Jan Bender and Michael Goesele and Arjan Kuijper},
journal={IEEE Computer Graphics and Applications},
title={Deferred Warping},
year={2016},
doi={10.1109/MCG.2016.41},
ISSN={0272-1716}
}
Towards Multi-user Provenance Tracking of Visual Analysis Workflows over Multiple Applications
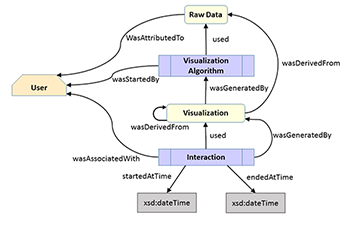
Provenance tracking for visual analysis workflows is still a challenge as especially interaction and collaboration aspects are poorly covered in existing realizations. Therefore, we propose a first prototype addressing these issues based on the PROV model. Interactions in multiple applications by multiple users can be tracked by means of a web interface and, thus, allowing even for tracking of remote-located collaboration partners. In the end, we demonstrate the applicability based on two use cases and discuss some open issues not addressed by our implementation so far but that can be easily integrated into our architecture.
@inproceedings {eurorv3.20161112,
booktitle = {EuroVis Workshop on Reproducibility, Verification, and Validation in Visualization (EuroRV3)},
editor = {Kai Lawonn and Mario Hlawitschka and Paul Rosenthal},
title = {{Towards Multi-user Provenance Tracking of Visual Analysis Workflows over Multiple Applications}},
author = { H{\"{a}}nel, Claudia and Khatami, Mohammad and Kuhlen, Torsten W. and Weyers, Benjamin},
year = {2016},
publisher = {The Eurographics Association},
ISSN = {-},
ISBN = {978-3-03868-017-8},
DOI = {10.2312/eurorv3.20161112}
}
A Lightweight Electrotactile Feedback Device to Improve Grasping in Immersive Virtual Environments

An immersive virtual environment is the ideal platform for the planning and training of on-orbit servicing missions. In such kind of virtual assembly simulation, grasping virtual objects is one of the most common and natural interactions. In this paper, we present a novel, small and lightweight electrotactile feedback device, specifically designed for immersive virtual environments. We conducted a study to assess the feasibility and usability of our interaction device. Results show that electrotactile feedback improved the user’s grasping in our virtual on-orbit servicing scenario. The task completion time was significantly lower and the precision of the user’s interaction was higher.
Collision Avoidance in the Presence of a Virtual Agent in Small-Scale Virtual Environments

Computer-controlled, human-like virtual agents (VAs), are often embedded into immersive virtual environments (IVEs) in order to enliven a scene or to assist users. Certain constraints need to be fulfilled, e.g., a collision avoidance strategy allowing users to maintain their personal space. Violating this flexible protective zone causes discomfort in real-world situations and in IVEs. However, no studies on collision avoidance for small-scale IVEs have been conducted yet.
Our goal is to close this gap by presenting the results of a controlled user study in a CAVE. 27 participants were immersed in a small-scale office with the task of reaching the office door. Their way was blocked either by a male or female VA, representing their co-worker. The VA showed different behavioral patterns regarding gaze and locomotion.
Our results indicate that participants preferred collaborative collision avoidance: they expect the VA to step aside in order to get more space to pass while being willing to adapt their own walking paths.
Honorable Mention for Best Technote!
@InProceedings{Boensch2016a,
Title = {Collision Avoidance in the Presence of a Virtual Agent in Small-Scale Virtual Environments},
Author = {Andrea B\"{o}nsch and Benjamin Weyers and Jonathan Wendt and Sebastian Freitag and Torsten W. Kuhlen},
Booktitle = {IEEE Symposium on 3D User Interfaces},
Year = {2016},
Pages = {145-148},
Abstract = {Computer-controlled, human-like virtual agents (VAs), are often embedded into immersive virtual environments (IVEs) in order to enliven a scene or to assist users. Certain constraints need to be fulfilled, e.g., a collision avoidance strategy allowing users to maintain
their personal space. Violating this flexible protective zone causes discomfort in real-world situations and in IVEs. However, no studies on collision avoidance for small-scale IVEs have been conducted yet. Our goal is to close this gap by presenting the results of a controlled
user study in a CAVE. 27 participants were immersed in a small-scale office with the task of reaching the office door. Theirwaywas blocked either by a male or female VA, representing their co-worker. The VA showed different behavioral patterns regarding gaze and locomotion.
Our results indicate that participants preferred collaborative collision avoidance: they expect the VA to step aside in order to get more space to pass while being willing to adapt their own walking paths.}
}
Automatic Speed Adjustment for Travel through Immersive Virtual Environments based on Viewpoint Quality

When traveling virtually through large scenes, long distances and different detail densities render fixed movement speeds impractical. However, to manually adjust the travel speed, users have to control an additional parameter, which may be uncomfortable and requires cognitive effort. Although automatic speed adjustment techniques exist, many of them can be problematic in indoor scenes. Therefore, we propose to automatically adjust travel speed based on viewpoint quality, originally a measure of the informativeness of a viewpoint. In a user study, we show that our technique is easy to use, allowing users to reach targets faster and use less cognitive resources than when choosing their speed manually.
Best Technote!
@INPROCEEDINGS{freitag2016b,
author={S. Freitag and B. Weyers and T. W. Kuhlen},
booktitle={2016 IEEE Symposium on 3D User Interfaces (3DUI)},
title={{Automatic Speed Adjustment for Travel through Immersive Virtual Environments based on Viewpoint Quality}},
year={2016},
pages={67-70},
doi={10.1109/3DUI.2016.7460033},
month={March},
}
SWIFTER: Design and Evaluation of a Speech-based Text Input Metaphor for Immersive Virtual Environments

Text input is an important part of the data annotation process, where text is used to capture ideas and comments. For text entry in immersive virtual environments, for which standard keyboards usually do not work, various approaches have been proposed. While these solutions have mostly proven effective, there still remain certain shortcomings making further investigations worthwhile. Motivated by recent research, we propose the speech-based multimodal text entry system SWIFTER, which strives for simplicity while maintaining good performance. In an initial user study, we compared our approach to smartphone-based text entry within a CAVE-like virtual environment. Results indicate that SWIFTER reaches an average input rate of 23.6 words per minute and is positively received by users in terms of user experience.
Evaluation of Hands-Free HMD-Based Navigation Techniques for Immersive Data Analysis
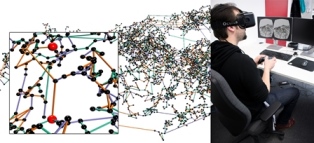
To use the full potential of immersive data analysis when wearing a head-mounted display, users have to be able to navigate through the spatial data. We collected, developed and evaluated 5 different hands-free navigation methods that are usable while seated in the analyst’s usual workplace. All methods meet the requirements of being easy to learn and inexpensive to integrate into existing workplaces. We conducted a user study with 23 participants which showed that a body leaning metaphor and an accelerometer pedal metaphor performed best. In the given task the participants had to determine the shortest path between various pairs of vertices in a large 3D graph.
Interactive Simulation of Aircraft Noise in Aural and Visual Virtual Environments

This paper describes a novel aircraft noise simulation technique developed at RWTH Aachen University, which makes use of aircraft noise auralization and 3D visualization to make aircraft noise both heard and seen in immersive Virtual Reality (VR) environments. This technique is intended to be used to increase the residents’ acceptance of aircraft noise by presenting noise changes in a more directly relatable form, and also aid in understanding what contributes to the residents’ subjective annoyance via psychoacoustic surveys. This paper describes the technique as well as some of its initial applications. The reasoning behind the development of such a technique is that the issue of aircraft noise experienced by residents in airport vicinities is one of subjective annoyance. Any efforts at noise abatement have been conventionally presented to residents in terms of noise level reductions in conventional metrics such as A-weighted level or equivalent sound level Leq. This conventional approach however proves insufficient in increasing aircraft noise acceptance due to two main reasons – firstly, the residents have only a rudimentary understanding of changes in decibel and secondly, the conventional metrics do not fully capture what the residents actually find annoying i.e. characteristics of aircraft noise they find least acceptable. In order to allow least resistance to air-traffic expansion, the acceptance of aircraft noise has to be increased, for which such a new approach to noise assessment is required.
Vista Widgets: A Framework for Designing 3D User Interfaces from Reusable Interaction Building Blocks
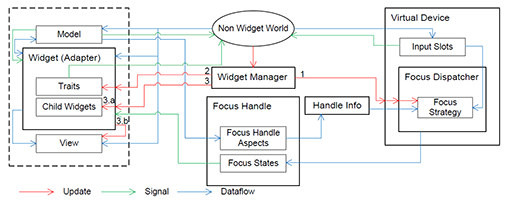
Virtual Reality (VR) has been an active field of research for several decades, with 3D interaction and 3D User Interfaces (UIs) as important sub-disciplines. However, the development of 3D interaction techniques and in particular combining several of them to construct complex and usable 3D UIs remains challenging, especially in a VR context. In addition, there is currently only limited reusable software for implementing such techniques in comparison to traditional 2D UIs. To overcome this issue, we present ViSTA Widgets, a software framework for creating 3D UIs for immersive virtual environments. It extends the ViSTA VR framework by providing functionality to create multi-device, multi-focus-strategy interaction building blocks and means to easily combine them into complex 3D UIs. This is realized by introducing a device abstraction layer along sophisticated focus management and functionality to create novel 3D interaction techniques and 3D widgets. We present the framework and illustrate its effectiveness with code and application examples accompanied by performance evaluations.
@InProceedings{Gebhardt2016,
Title = {{Vista Widgets: A Framework for Designing 3D User Interfaces from Reusable Interaction Building Blocks}},
Author = {Gebhardt, Sascha and Petersen-Krau, Till and Pick, Sebastian and Rausch, Dominik and Nowke, Christian and Knott, Thomas and Schmitz, Patric and Zielasko, Daniel and Hentschel, Bernd and Kuhlen, Torsten W.},
Booktitle = {Proceedings of the 22nd ACM Conference on Virtual Reality Software and Technology},
Year = {2016},
Address = {New York, NY, USA},
Pages = {251--260},
Publisher = {ACM},
Series = {VRST '16},
Acmid = {2993382},
Doi = {10.1145/2993369.2993382},
ISBN = {978-1-4503-4491-3},
Keywords = {3D interaction, 3D user interfaces, framework, multi-device, virtual reality},
Location = {Munich, Germany},
Numpages = {10},
Url = {http://doi.acm.org/10.1145/2993369.2993382}
}
Projective Fluids

We present a new method for particle based fluid simulation, using a combination of Projective Dynamics and Smoothed Particle Hydrodynamics (SPH). The Projective Dynamics framework allows the fast simulation of a wide range of constraints. It offers great stability through its implicit time integration scheme and is parallelizable in large parts, so that it can make use of modern multi core CPUs. Yet existing work only uses Projective Dynamics to simulate various kinds of soft bodies and cloth. We are the first ones to incorporate fluid simulation into the Projective Dynamics framework. Our proposed fluid constraints are derived from SPH and seamlessly integrate into the existing method. Furthermore, we adapt the solver to handle the constantly changing constraints that appear in fluid simulation. We employ a highly parallel matrix-free conjugate gradient solver, and thus do not require expensive matrix factorizations.
@inproceedings{Weiler2016,
author = {Marcel Weiler and Dan Koschier and Jan Bender},
title = {Projective Fluids},
booktitle = {Proceedings of ACM SIGGRAPH Conference on Motion in Games},
series = {MIG '16},
year = {2016},
publisher = {ACM}
}
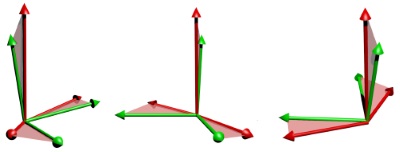
A Robust Method to Extract the Rotational Part of Deformations
We present a novel algorithm to extract the rotational part of an arbitrary 3x3 matrix. This problem lies at the core of two popular simulation methods in computer graphics, the co-rotational Finite Element Method and Shape Matching techniques. In contrast to the traditional method based on polar decomposition, degenerate configurations and inversions are handled robustly and do not have to be treated in a special way. In addition, our method can be implemented with only a few lines of code without branches which makes it particularly well suited for GPU-based applications. We demonstrate the robustness, coherence and efficiency of our method by comparing it to stabilized polar decomposition in several simulation scenarios.
@inproceedings{Mueller2016,
author = {Matthias M\"{u}ller and Jan Bender and Nuttapong Chentanez and Miles Macklin},
title = {A Robust Method to Extract the Rotational Part of Deformations},
booktitle = {Proceedings of ACM SIGGRAPH Conference on Motion in Games},
series = {MIG '16},
year = {2016},
publisher = {ACM}
}
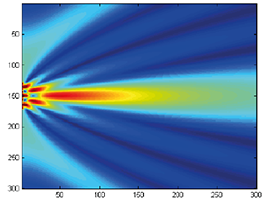
Experiences on Validation of Multi-Component System Simulations for Medical Training Applications
In the simulation of multi-component systems, we often encounter a problem with a lack of ground-truth data. This situation makes the validation of our simulation methods and models a difficult task. In this work we present a guideline to design validation methodologies that can be applied to the validation of multi-component simulations that lack of ground-truth data. Additionally we present an example applied to an Ultrasound Image Simulation for medical training and give an overview of the considerations made and the results for each of the validation methods. With these guidelines we expect to obtain more comparable and reproducible validation results from which other similar work can benefit.
@InProceedings{eurorv3.20161113,
author = {Law, Yuen C. and Weyers, Benjamin and Kuhlen, Torsten W.},
title = {{Experiences on Validation of Multi-Component System Simulations for Medical Training Applications}},
booktitle = {EuroVis Workshop on Reproducibility, Verification, and Validation in Visualization (EuroRV3)},
year = {2016},
editor = {Kai Lawonn and Mario Hlawitschka and Paul Rosenthal},
publisher = {The Eurographics Association},
doi = {10.2312/eurorv3.20161113},
isbn = {978-3-03868-017-8},
pages = {29--33}
}
The STRANDS Project: Long-Term Autonomy in Everyday Environments

Thanks to the efforts of our community, autonomous robots are becoming capable of ever more complex and impressive feats. There is also an increasing demand for, perhaps even an expectation of, autonomous capabilities from end-users. However, much research into autonomous robots rarely makes it past the stage of a demonstration or experimental system in a controlled environment. If we don't confront the challenges presented by the complexity and dynamics of real end-user environments, we run the risk of our research becoming irrelevant or ignored by the industries who will ultimately drive its uptake. In the STRANDS project we are tackling this challenge head-on. We are creating novel autonomous systems, integrating state-of-the-art research in artificial intelligence and robotics into robust mobile service robots, and deploying these systems for long-term installations in security and care environments. To date, over four deployments, our robots have been operational for a combined duration of 2545 hours (or a little over 106 days), covering 116km while autonomously performing end-user defined tasks. In this article we present an overview of the motivation and approach of the STRANDS project, describe the technology we use to enable long, robust autonomous runs in challenging environments, and describe how our robots are able to use these long runs to improve their own performance through various forms of learning.
Visualizing Performance Data With Respect to the Simulated Geometry
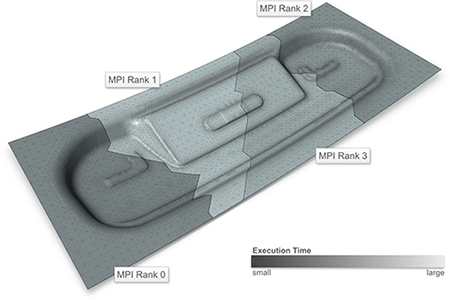
Understanding the performance behaviour of high-performance computing (hpc) applications based on performance profiles is a challenging task. Phenomena in the performance behaviour can stem from the hpc system itself, from the application’s code, but also from the simulation domain. In order to analyse the latter phenomena, we propose a system that visualizes profile-based performance data in its spatial context in the simulation domain, i.e., on the geometry processed by the application. It thus helps hpc experts and simulation experts understand the performance data better. Furthermore, it reduces the initially large search space by automatically labeling those parts of the data that reveal variation in performance and thus require detailed analysis.
@inproceedings{VIERJAHN-2016-02,
Author = {Vierjahn, Tom and Kuhlen, Torsten W. and M\"{u}ller, Matthias S. and Hentschel, Bernd},
Booktitle = {JARA-HPC Symposium (accepted for publication)},
Title = {Visualizing Performance Data With Respect to the Simulated Geometry},
Year = {2016}}
Using Directed Variance to Identify Meaningful Views in Call-Path Performance Profiles
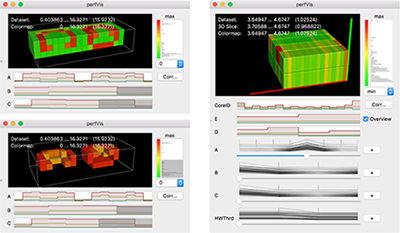
Understanding the performance behaviour of massively parallel high-performance computing (HPC) applications based on call-path performance profiles is a time-consuming task. In this paper, we introduce the concept of directed variance in order to help analysts find performance bottlenecks in massive performance data and in the end optimize the application. According to HPC experts’ requirements, our technique automatically detects severe parts in the data that expose large variation in an application’s performance behaviour across system resources. Previously known variations are effectively filtered out. Analysts are thus guided through a reduced search space towards regions of interest for detailed examination in a 3D visualization. We demonstrate the effectiveness of our approach using performance data of common benchmark codes as well as from actively developed production codes.
@inproceedings{VIERJAHN-2016-04,
Author = {Vierjahn, Tom and Hermanns, Marc-Andr\'{e} and Mohr, Bernd and M\"{u}ller, Matthias S. and Kuhlen, Torsten W. and Hentschel, Bernd},
Booktitle = {3rd Workshop Visual Performance Analysis (to appear)},
Title = {Using Directed Variance to Identify Meaningful Views in Call-Path Performance Profiles},
Year = {2016}}
Poster: Correlating Sub-Phenomena in Performance Data in the Frequency Domain
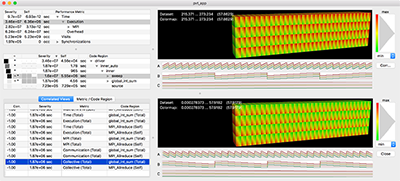
Finding and understanding correlated performance behaviour of the individual functions of massively parallel high-performance computing (HPC) applications is a time-consuming task. In this poster, we propose filtered correlation analysis for automatically locating interdependencies in call-path performance profiles. Transforming the data into the frequency domain splits a performance phenomenon into sub-phenomena to be correlated separately. We provide the mathematical framework and an overview over the visualization, and we demonstrate the effectiveness of our technique.
Best Poster Award!
@inproceedings{Vierjahn-2016-03,
Author = {Vierjahn, Tom and Hermanns, Marc-Andr\'{e} and Mohr, Bernd and M\"{u}ller, Matthias S. and Kuhlen, Torsten W. and Hentschel, Bernd},
Booktitle = {LDAV 2016 -- Posters (accepted)},
Date-Added = {2016-08-31 22:14:47 +0000},
Date-Modified = {2016-08-31 22:15:58 +0000},
Title = {Correlating Sub-Phenomena in Performance Data in the Frequency Domain}
}
Poster: Evaluating Presence Strategies of Temporarily Required Virtual Assistants

Computer-controlled virtual humans can serve as assistants in virtual scenes. Here, they are usually in an almost constant contact with the user. Nonetheless, in some applications assistants are required only temporarily. Consequently, presenting them only when needed, i.e, minimizing their presence time, might be advisable.
To the best of our knowledge, there do not yet exist any design guidelines for such agent-based support systems. Thus, we plan to close this gap by a controlled qualitative and quantitative user study in a CAVE-like environment.We expect users to prefer assistants with a low presence time as well as a low fallback time to get quick support. However, as both factors are linked, a suitable trade-off needs to be found. Thus, we plan to test four different strategies, namely fading, moving, omnipresent and busy. This work presents our hypotheses and our planned within-subject design.
@InBook{Boensch2016c,
Title = {Evaluating Presence Strategies of Temporarily Required Virtual Assistants},
Author = {Andrea B\"{o}nsch and Tom Vierjahn and Torsten W. Kuhlen},
Pages = {387 - 391},
Publisher = {Springer International Publishing},
Year = {2016},
Month = {September},
Abstract = {Computer-controlled virtual humans can serve as assistants in virtual scenes. Here, they are usually in an almost constant contact with the user. Nonetheless, in some applications assistants are required only
temporarily. Consequently, presenting them only when needed, i.e., minimizing their presence time, might be advisable.
To the best of our knowledge, there do not yet exist any design guidelines for such agent-based support systems. Thus, we plan to close this gap by a controlled qualitative and quantitative user study in a CAVE-like environment. We expect users to prefer assistants with a low presence time as well as a low fallback time to get quick support. However, as both factors are linked, a suitable trade-off needs to be found. Thus, we p lan to test four different strategies, namely fading, moving, omnipresent and busy. This work presents our hypotheses and our planned within-subject design.},
Booktitle = {Intelligent Virtual Agents: 16th International Conference, IVA 2016. Proceedings},
Doi = {10.1007/978-3-319-47665-0_39},
Keywords = {Virtual agent, Assistive technology, Immersive virtual environments, User study design},
Owner = {ab280112},
Timestamp = {2016.08.01},
Url = {http://dx.doi.org/10.1007/978-3-319-47665-0_39}
}
An Integrated Approach for the Knowledge Discovery in Computer Simulation Models with a Multi-dimensional Parameter Space
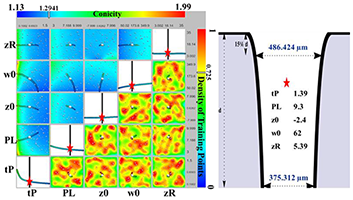
In production industries, parameter identification, sensitivity analysis and multi-dimensional visualization are vital steps in the planning process for achieving optimal designs and gaining valuable information. Sensitivity analysis and visualization can help in identifying the most-influential parameters and quantify their contribution to the model output, reduce the model complexity, and enhance the understanding of the model behavior. Typically, this requires a large number of simulations, which can be both very expensive and time consuming when the simulation models are numerically complex and the number of parameter inputs increases. There are three main constituent parts in this work. The first part is to substitute the numerical, physical model by an accurate surrogate model, the so-called metamodel. The second part includes a multi-dimensional visualization approach for the visual exploration of metamodels. In the third part, the metamodel is used to provide the two global sensitivity measures: i) the Elementary Effect for screening the parameters, and ii) the variance decomposition method for calculating the Sobol indices that quantify both the main and interaction effects. The application of the proposed approach is illustrated with an industrial application with the goal of optimizing a drilling process using a Gaussian laser beam.
@article{:/content/aip/proceeding/aipcp/10.1063/1.4952148,
author = "Khawli, Toufik Al and Gebhardt, Sascha and Eppelt, Urs and Hermanns, Torsten and Kuhlen, Torsten and Schulz, Wolfgang",
title = "An integrated approach for the knowledge discovery in computer simulation models with a multi-dimensional parameter space",
journal = "AIP Conference Proceedings",
year = "2016",
volume = "1738",
number = "1",
eid = 370003,
pages = "",
url = "http://scitation.aip.org/content/aip/proceeding/aipcp/10.1063/1.4952148;jsessionid=jy3FCznaGWpVQVNPYx765REW.x-aip-live-03",
doi = "http://dx.doi.org/10.1063/1.4952148"
}
Web-based Interactive and Visual Data Analysis for Ubiquitous Learning Analytics
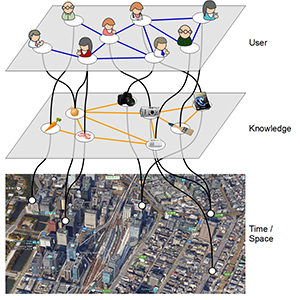
Interactive visual data analysis is a well-established class of methods to gather knowledge from raw and complex data. A broad variety of examples can be found in literature presenting its applicability in various ways and different scientific domains. However, fully fledged solutions for visual analysis addressing learning analytics are still rare. Therefore, this paper will discuss visual and interactive data analysis for learning analytics by presenting best practices followed by a discussion of a general architecture combining interactive visualization employing the Information Seeking Mantra in conjunction with the paradigm of coordinated multiple views. Finally, by presenting a use case for ubiquitous learning analytics its applicability will be demonstrated with the focus on temporal and spatial relation of learning data. The data is gathered from a ubiquitous learning scenario offering information for students to identify learning partners and provides information to teachers enabling the adaption of their learning material.
@InProceedings{weyers2016a,
Title = {Web-based Interactive and Visual Data Analysis for Ubiquitous Learning Analytics},
Author = {Benjamin Weyers, Christian Nowke, Torsten Wolfgang Kuhlen, Mouri Kousuke, Hiroaki Ogata},
Booktitle = {First International Workshop on Learning Analytics Across Physical and Digital Spaces co-located with 6th International Conference on Learning Analytics \& Knowledge (LAK 2016)},
Year = {2016},
Pages = {65--69},
Editor = {Roberto Martinez-Maldonado, Davinia Hernandez-Leo},
Volume = {1601},
Abstract = {Interactive visual data analysis is a well-established class of methods to gather knowledge from raw and complex data. A broad variety of examples can be found in literature presenting its applicability in various ways and different scientific domains. However, fully fledged solutions for visual analysis addressing learning analytics are still rare. Therefore, this paper will discuss visual and interactive data analysis for learning analytics by presenting best practices followed by a discussion of a general architecture combining interactive visualization employing the Information Seeking Mantra in conjunction with the paradigm of coordinated multiple views. Finally, by presenting a use case for ubiquitous learning analytics its applicability will be demonstrated with the focus on temporal and spatial relation of learning data. The data is gathered from a ubiquitous learning scenario offering information
for students to identify learning partners and provides information to teachers enabling the adaption of their learning material.},
Keywords = {interactive analysis, web-based visualization, learning analytics},
Url = {http://ceur-ws.org/Vol-1601/}
}
Semantic Segmentation of Modular Furniture

This paper proposes an approach for the semantic seg- mentation and structural parsing of modular furniture items, such as cabinets, wardrobes, and bookshelves, into so called interaction elements. Such a segmentation into functional units is challenging not only due to the visual similarity of the different elements but also because of their often uniformly colored and low-texture appearance. Our method addresses these challenges by merging structural and appearance likelihoods of each element and jointly op- timizing over shape, relative location, and class labels us- ing Markov Chain Monte Carlo (MCMC) sampling. We propose a novel concept called rectangle coverings which provides a tight bound on the number of structural elements and hence narrows down the search space. We evaluate our approach’s performance on a novel dataset of furniture items and demonstrate its applicability in practice.
@inproceedings{badamiWACV17,
title={Semantic Segmentation of Modular Furniture},
author={Pohlen, Tobias and Badami, Ishrat and Mathias, Markus and Leibe, Bastian},
booktitle={WACV},
year={2016}
}
Poster: Evaluation of Hands-Free HMD-Based Navigation Techniques for Immersive Data Analysis
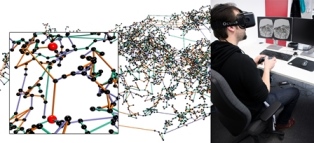
To use the full potential of immersive data analysis when wearing a head-mounted display, the user has to be able to navigate through the spatial data. We collected, developed and evaluated 5 different hands-free navigation methods that are usable while seated in the analyst’s usual workplace. All methods meet the requirements of being easy to learn and inexpensive to integrate into existing workplaces. We conducted a user study with 23 participants which showed that a body leaning metaphor and an accelerometer pedal metaphor performed best within the given task.
Poster: Automatic Generation of World in Miniatures for Realistic Architectural Immersive Virtual Environments

Orientation and wayfinding in architectural Immersive Virtual Environments (IVEs) are non-trivial, accompanying tasks which generally support the users’ main task. World in Miniatures (WIMs)— essentially 3D maps containing a scene replica—are an established approach to gain survey knowledge about the virtual world, as well as information about the user’s relation to it. However, for largescale, information-rich scenes, scaling and occlusion issues result in diminishing returns. Since there typically is a lack of standardized information regarding scene decompositions, presenting the inside of self-contained scene extracts is challenging.
Therefore, we present an automatic WIM generation workflow for arbitrary, realistic in- and outdoor IVEs in order to support users with meaningfully selected and scaled extracts of the IVE as well as corresponding context information. Additionally, a 3D user interface is provided to manually manipulate the represented extract.
@InProceedings{Boensch2016b,
Title = {Automatic Generation of World in Miniatures for Realistic Architectural Immersive Virtual Environments},
Author = {Andrea B\"{o}nsch and Sebastian Freitag and Torsten W. Kuhlen},
Booktitle = {IEEE Virtual Reality Conference Poster Proceedings},
Year = {2016},
Pages = {155-156},
Abstract = {Orientation and wayfinding in architectural Immersive Virtual Environments (IVEs) are non-trivial, accompanying tasks which generally support the users’ main task. World in Miniatures (WIMs)—essentially 3D maps containing a scene replica—are an established approach to gain survey knowledge about the virtual world, as well as information about the user’s relation to it. However, for largescale, information-rich scenes, scaling and occlusion issues result in diminishing returns. Since there typically is a lack of standardized information regarding scene decompositions, presenting the inside of self-contained scene extracts is challenging.
Therefore, we present an automatic WIM generation workflow for arbitrary, realistic in- and outdoor IVEs in order to support users with meaningfully selected and scaled extracts of the IVE as well as corresponding context information. Additionally, a 3D user interface is provided to manually manipulate the represented extract.}
}
Poster: Formal Evaluation Strategies for Feature Tracking

We present an approach for tracking space-filling features based on a two-step algorithm utilizing two graph optimization techniques. First, one-to-one assignments between successive time steps are found by a matching on a weighted, bi-partite graph. Second, events are detected by computing an independent set on potential event explanations. The main objective of this work is investigating options for formal evaluation of complex feature tracking algorithms in the absence of ground truth data.
@INPROCEEDINGS{Schnorr2016, author = {Andrea Schnorr and Sebastian Freitag and Dirk Helmrich and Torsten W. Kuhlen and Bernd Hentschel}, title = {{F}ormal {E}valuation {S}trategies for {F}eature {T}racking}, booktitle = Proc # { the } # LDAV, year = {2016}, pages = {103--104}, abstract = { We present an approach for tracking space-filling features based on a two-step algorithm utilizing two graph optimization techniques. First, one-to-one assignments between successive time steps are found by a matching on a weighted, bi-partite graph. Second, events are detected by computing an independent set on potential event explanations. The main objective of this work is investigating options for formal evaluation of complex feature tracking algorithms in the absence of ground truth data.
}, doi = { 10.1109/LDAV.2016.7874339}}
Poster: Geometry-Aware Visualization of Performance Data
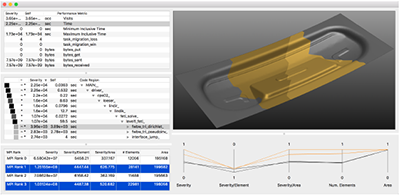
Phenomena in the performance behaviour of high-performance computing (HPC) applications can stem from the HPC system itself, from the application's code, but also from the simulation domain. In order to analyse the latter phenomena, we propose a system that visualizes profile-based performance data in its spatial context, i.e., on the geometry, in the simulation domain. It thus helps HPC experts but also simulation experts understand the performance data better. In addition, our tool reduces the initially large search space by automatically labelling large-variation views on the data which require detailed analysis.
@inproceedings {eurp.20161136,
booktitle = {EuroVis 2016 - Posters},
editor = {Tobias Isenberg and Filip Sadlo},
title = {{Geometry-Aware Visualization of Performance Data}},
author = {Vierjahn, Tom and Hentschel, Bernd and Kuhlen, Torsten W.},
year = {2016},
publisher = {The Eurographics Association},
ISBN = {978-3-03868-015-4},
DOI = {10.2312/eurp.20161136},
pages = {37--39}
}
Poster: Tracking Space-Filling Features by Two-Step Optimization
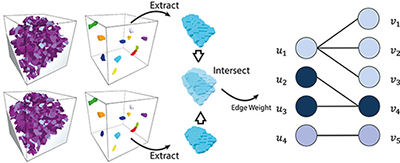
We present a novel approach for tracking space-filling features, i.e., a set of features covering the entire domain. The assignment between successive time steps is determined by a two-step, global optimization scheme. First, a maximum-weight, maximal matching on a bi-partite graph is computed to provide one-to-one assignments between features of successive time steps. Second, events are detected in a subsequent step; here the matching step serves to restrict the exponentially large set of potential solutions. To this end, we compute an independent set on a graph representing conflicting event explanations. The method is evaluated by tracking dissipation elements, a structure definition from turbulent flow analysis.
Honorable Mention Award!
@inproceedings {eurp.20161146,
booktitle = {EuroVis 2016 - Posters},
editor = {Tobias Isenberg and Filip Sadlo},
title = {{Tracking Space-Filling Features by Two-Step Optimization}},
author = {Schnorr, Andrea and Freitag, Sebastian and Kuhlen, Torsten W. and Hentschel, Bernd},
year = {2016},
publisher = {The Eurographics Association},
pages = {77--79},
ISBN = {978-3-03868-015-4},
DOI = {10.2312/eurp.20161146}
}
Avatars as Peers at Work: An Experimental Study in Virtual Reality
Identification of peer effects is often complicated by the reflection problem: Does agent i influence agent j, or vice versa? To be able to identify a clear causality, we embed a virtual human (avatar) as co-worker of a human subject into an immersive virtual environment. We observe that low productive human subjects increase their work performance more when they observe a low productive avatar – compared to a high productive avatar. This result is in line with the predictions of the social comparison theory, in as much as we observe stronger peer effects when the perceived similarity in abilities between the peers is high.
@Article{Guererk2016,
Title = {Avatars as Peers at Work: An Experimental Study in Virtual Reality},
Author = {Ozgür Gürerk and Thomas Kittsteiner and Andrea Bönsch and Andreas Staffeldt},
Year = {2016},
DOI = {10.2139/ssrn.2842411},
Publisher = {SSRN}
}
Talk: Two Basic Aspects of Virtual Agents’ Behavior: Collision Avoidance and Presence Strategies
Virtual Agents (VAs) are embedded in virtual environments for two reasons: they enliven architectural scenes by representing more realistic situations, and they are dialogue partners. They can function as training partners such as representing students in a teaching scenario, or as assistants by, e.g., guiding users through a scene or by performing certain tasks either individually or in collaboration with the user. However, designing such VAs is challenging as various requirements have to be met. Two relevant factors will be briefly discussed in the talk: Collision Avoidance and Presence Strategies.
Experimental Economics in Virtual Reality

Experimental economics uses controlled and incentivized lab and field experiments to learn about economic behavior. By means of three examples, we illustrate how experiments conducted in immersive virtual environments emerge as a new methodological tool that can benefit behavioral economic research.
@TechReport{Gurerk2016,
Title = {{Experimental Economics in Virtual Reality},}
Author = {G{\"u}rerk, {\"O}zg{\"u}r and B{\"o}nsch, Andrea and Braun, Lucas and Grund, Christian and Harbring, Christine and Kittsteiner, Thomas and Staffeldt, Andreas},
Institution = {{M}unich {P}ersonal {R}e{PE}c {A}rchive ({MPRA}), Paper No. 71409},
Year = {2016},
Number = {Paper No. 71409},
Url = {http://mpra.ub.uni-muenchen.de/71409/}
}
Superpixels: An Evaluation of the State-of-the-Art
Superpixels group perceptually similar pixels to create visually meaningful entities while heavily reducing the number of primitives. As of these properties, superpixel algorithms have received much attention since their naming in 2003. By today, publicly available and well-understood superpixel algorithms have turned into standard tools in low-level vision. As such, and due to their quick adoption in a wide range of applications, appropriate benchmarks are crucial for algorithm selection and comparison. Until now, the rapidly growing number of algorithms as well as varying experimental setups hindered the development of a unifying benchmark. We present a comprehensive evaluation of 28 state-of-the-art superpixel algorithms utilizing a benchmark focussing on fair comparison and designed to provide new and relevant insights. To this end, we explicitly discuss parameter optimization and the importance of strictly enforcing connectivity. Furthermore, by extending well-known metrics, we are able to summarize algorithm performance independent of the number of generated superpixels, thereby overcoming a major limitation of available benchmarks. Furthermore, we discuss runtime, robustness against noise, blur and affine transformations, implementation details as well as aspects of visual quality. Finally, we present an overall ranking of superpixel algorithms which redefines the state-of-the-art and enables researchers to easily select appropriate algorithms and the corresponding implementations which themselves are made publicly available as part of our benchmark at davidstutz.de/projects/superpixel-benchmark/.
@article{Stutz2016Arxiv,
title = {{Superpixels: An Evaluation of the State-of-the-Art}},
author = {David Stutz and Alexander Hermans and Bastian Leibe},
journal = {arXiv preprint arXiv:1612.01601},
year = {2016}
}
An Efficient Convolutional Network for Human Pose Estimation
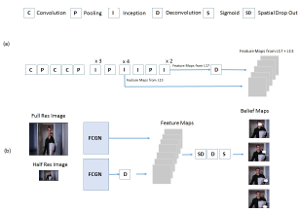
In recent years, human pose estimation has greatly benefited from deep learning and huge gains in performance have been achieved. The trend to maximise the accuracy on benchmarks, however, resulted in computationally expensive deep network architectures that require expensive hardware and pre-training on large datasets. This makes it difficult to compare different methods and to reproduce existing results. We therefore propose in this work an efficient deep network architecture that can be efficiently trained on mid-range GPUs without the need of any pre-training. Despite of the low computational requirements of our network, it is on par with much more complex models on popular benchmarks for human pose estimation.
On Multi-Modal People Tracking from Mobile Platforms in Very Crowded and Dynamic Environments

Tracking people is a key technology for robots and intelligent systems in human environments. Many person detectors, filtering methods and data association algorithms for people tracking have been proposed in the past 15+ years in both the robotics and computer vision communities, achieving decent tracking performances from static and mobile platforms in real-world scenarios. However, little effort has been made to compare these methods, analyze their performance using different sensory modalities and study their impact on different performance metrics. In this paper, we propose a fully integrated real-time multi-modal laser/RGB-D people tracking framework for moving platforms in environments like a busy airport terminal. We conduct experiments on two challenging new datasets collected from a first-person perspective, one of them containing very dense crowds of people with up to 30 individuals within close range at the same time. We consider four different, recently proposed tracking methods and study their impact on seven different performance metrics, in both single and multi-modal settings. We extensively discuss our findings, which indicate that more complex data association methods may not always be the better choice, and derive possible future research directions.
@incollection{linder16multi,
title={On Multi-Modal People Tracking from Mobile Platforms in Very Crowded and Dynamic Environments},
author={Linder, Timm and Breuers, Stefan and Leibe, Bastian and Arras, Kai Oliver},
booktitle={ICRA},
year={2016},
}
Exploring Bounding Box Context for Multi-Object Tracker Fusion
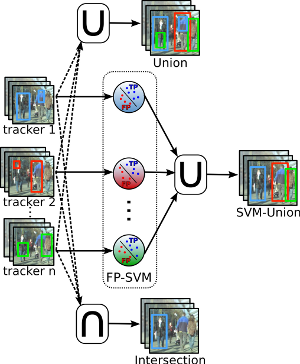
Many multi-object-tracking (MOT) techniques have been developed over the past years. The most successful ones are based on the classical tracking-by-detection approach. The different methods rely on different kinds of data association, use motion and appearance models, or add optimization terms for occlusion and exclusion. Still, errors occur for all those methods and a consistent evaluation has just started. In this paper we analyze three current state-of-the-art MOT trackers and show that there is still room for improvement. To that end, we train a classifier on the trackers' output bounding boxes in order to prune false positives. Furthermore, the different approaches have different strengths resulting in a reduced false negative rate when combined. We perform an extensive evaluation over ten common evaluation sequences and consistently show improved performances by exploiting the strengths and reducing the weaknesses of current methods.
@inproceedings{breuersWACV16,
title={Exploring Bounding Box Context for Multi-Object Tracker Fusion},
author={Breuers, Stefan and Yang, Shishan and Mathias, Markus and Leibe, Bastian},
booktitle={WACV},
year={2016}
}
Previous Year (2015)
