
Publications
Discovering Favorite Views of Popular Places with Iconoid Shift

In this paper, we propose a novel algorithm for automatic landmark building discovery in large, unstructured image collections. In contrast to other approaches which aim at a hard clustering, we regard the task as a mode estimation problem. Our algorithm searches for local attractors in the image distribution that have a maximal mutual homography overlap with the images in their neighborhood. Those attractors correspond to central, iconic views of single objects or buildings, which we efficiently extract using a medoid shift search with a novel distance measure. We propose efficient algorithms for performing this search. Most importantly, our approach performs only an efficient local exploration of the matching graph that makes it applicable for large-scale analysis of photo collections. We show experimental results validating our approach on a dataset of 500k images of the inner city of Paris.
@inproceedings{DBLP:conf/iccv/WeyandL11,
author = {Tobias Weyand and
Bastian Leibe},
title = {Discovering favorite views of popular places with iconoid shift},
booktitle = {{IEEE} International Conference on Computer Vision, {ICCV} 2011, Barcelona,
Spain, November 6-13, 2011},
pages = {1132--1139},
year = {2011},
crossref = {DBLP:conf/iccv/2011},
url = {http://dx.doi.org/10.1109/ICCV.2011.6126361},
doi = {10.1109/ICCV.2011.6126361},
timestamp = {Thu, 19 Jan 2012 18:05:15 +0100},
biburl = {http://dblp.uni-trier.de/rec/bib/conf/iccv/WeyandL11},
bibsource = {dblp computer science bibliography, http://dblp.org}
}
Level-Set Person Segmentation and Tracking with Multi-Region Appearance Models and Top-Down Shape Information
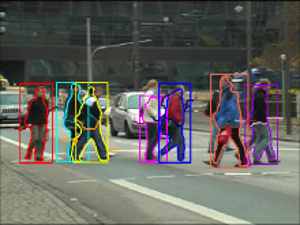
In this paper, we address the problem of segmentationbased tracking of multiple articulated persons. We propose two improvements to current level-set tracking formulations. The first is a localized appearance model that uses additional level-sets in order to enforce a hierarchical subdivision of the object shape into multiple connected regions with distinct appearance models. The second is a novel mechanism to include detailed object shape information in the form of a per-pixel figure/ground probability map obtained from an object detection process. Both contributions are seamlessly integrated into the level-set framework. Together, they considerably improve the accuracy of the tracked segmentations. We experimentally evaluate our proposed approach on two challenging sequences and demonstrate its good performance in practice.
@inproceedings{DBLP:conf/iccv/HorbertRL11,
author = {Esther Horbert and
Konstantinos Rematas and
Bastian Leibe},
title = {Level-set person segmentation and tracking with multi-region appearance
models and top-down shape information},
booktitle = {{IEEE} International Conference on Computer Vision, {ICCV} 2011, Barcelona,
Spain, November 6-13, 2011},
pages = {1871--1878},
year = {2011},
crossref = {DBLP:conf/iccv/2011},
url = {http://dx.doi.org/10.1109/ICCV.2011.6126455},
doi = {10.1109/ICCV.2011.6126455},
timestamp = {Thu, 19 Jan 2012 18:05:15 +0100},
biburl = {http://dblp.uni-trier.de/rec/bib/conf/iccv/HorbertRL11},
bibsource = {dblp computer science bibliography, http://dblp.org}
}
Fast Image-Based Localization using Direct 2D-to-3D Matching

Estimating the position and orientation of a camera given an image taken by it is an important step in many interesting applications such as tourist navigations, robotics, augmented reality and incremental Structure-from-Motion reconstruction. To do so, we have to find correspondences between structures seen in the image and a 3D representation of the scene. Due to the recent advances in the field of Structure-from-Motion it is now possible to reconstruct large scenes up to the level of an entire city in very little time. We can use these results to enable image-based localization of a camera (and its user) on a large scale. However, when processing such large data, the computation between points in the image and points in the model quickly becomes the bottleneck of the localization pipeline. Therefore, it is extremely important to develop methods that are able to effectively and efficiently handle such large environments and that scale well to even larger scenes.
Multi-Class Image Labeling with Top-Down Segmentation and Generalized Robust P^N Potentials

We propose a novel formulation for the scene labeling problem which is able to combine object detections with pixel-level information in a Conditional Random Field (CRF) framework. Since object detection and multi-class image labeling are mutually informative problems, pixel-wise segmentation can benefit from powerful object detectors and vice versa. The main contribution of the current work lies in the incorporation of topdown object segmentations as generalized robust P N potentials into the CRF formulation. These potentials present a principled manner to convey soft object segmentations into a unified energy minimization framework, enabling joint optimization and thus mutual benefit for both problems. As our results show, the proposed approach outperforms the state-of-the-art methods on the categories for which object detections are available. Quantitative and qualitative experiments show the effectiveness of the proposed method.
@inproceedings{DBLP:conf/bmvc/FlorosRL11,
author = {Georgios Floros and
Konstantinos Rematas and
Bastian Leibe},
title = {Multi-Class Image Labeling with Top-Down Segmentation and Generalized
Robust {\textdollar}P{\^{}}N{\textdollar} Potentials},
booktitle = {British Machine Vision Conference, {BMVC} 2011, Dundee, UK, August
29 - September 2, 2011. Proceedings},
pages = {1--11},
year = {2011},
crossref = {DBLP:conf/bmvc/2011},
url = {http://dx.doi.org/10.5244/C.25.79},
doi = {10.5244/C.25.79},
timestamp = {Wed, 24 Apr 2013 17:19:07 +0200},
biburl = {http://dblp.uni-trier.de/rec/bib/conf/bmvc/FlorosRL11},
bibsource = {dblp computer science bibliography, http://dblp.org}
}
Real-Time Multi-Person Tracking with Time-Constrained Detection
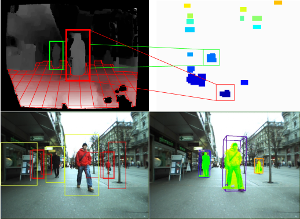
This paper presents a robust real-time multi-person tracking framework for busy street scenes. Tracking-by-detection approaches have recently been successfully applied to this task. However, their run-time is still limited by the computationally expensive object detection component. In this paper, we therefore consider the problem of making best use of an object detector with a fixed and very small time budget. The question we ask is: given a fixed time budget that allows for detector-based verification of k small regions-of-interest (ROIs) in the image, what are the best regions to attend to in order to obtain stable tracking performance? We address this problem by applying a statistical Poisson process model in order to rate the urgency by which individual ROIs should be attended to. These ROIs are initially extracted from a 3D depth-based occupancy map of the scene and are then tracked over time. This allows us to balance the system resources in order to satisfy the twin goals of detecting newly appearing objects, while maintaining the quality of existing object trajectories.
@inproceedings{DBLP:conf/bmvc/MitzelSL11,
author = {Dennis Mitzel and
Patrick Sudowe and
Bastian Leibe},
title = {Real-Time Multi-Person Tracking with Time-Constrained Detection},
booktitle = {British Machine Vision Conference, {BMVC} 2011, Dundee, UK, August
29 - September 2, 2011. Proceedings},
pages = {1--11},
year = {2011},
crossref = {DBLP:conf/bmvc/2011},
url = {http://dx.doi.org/10.5244/C.25.104},
doi = {10.5244/C.25.104},
timestamp = {Wed, 24 Apr 2013 17:19:07 +0200},
biburl = {http://dblp.uni-trier.de/rec/bib/conf/bmvc/MitzelSL11},
bibsource = {dblp computer science bibliography, http://dblp.org}
}
Lying Pose Recognition for Elderly Fall Detection

This paper proposes a pipeline for lying pose recognition from single images, which is designed for health-care robots to find fallen people. We firstly detect object bounding boxes by a mixture of viewpoint-specific part based model detectors and later estimate a detailed configuration of body parts on the detected regions by a finer tree-structured model. Moreover, we exploit the information provided by detection to infer a reasonable limb prior for the pose estimation stage. Additional robustness is achieved by integrating a viewpointspecific foreground segmentation into the detection and body pose estimation stages. This step yields a refinement of detection scores and a better color model to initialize pose estimation. We apply our proposed approach to challenging data sets of fallen people in different scenarios. Our quantitative and qualitative results demonstrate that the part-based model significantly outperforms a holistic model based on same feature type for lying pose detection. Moreover, our system offers a reasonable estimation for the body configuration of varying lying poses.
@inproceedings{DBLP:conf/rss/WangZL11,
author = {Simin Wang and
Salim Zabir and
Bastian Leibe},
title = {Lying Pose Recognition for Elderly Fall Detection},
booktitle = {Robotics: Science and Systems VII, University of Southern California,
Los Angeles, CA, USA, June 27-30, 2011},
year = {2011},
crossref = {DBLP:conf/rss/2011},
url = {http://www.roboticsproceedings.org/rss07/p44.html},
timestamp = {Sun, 18 Dec 2011 20:27:03 +0100},
biburl = {http://dblp.uni-trier.de/rec/bib/conf/rss/WangZL11},
bibsource = {dblp computer science bibliography, http://dblp.org}
}
Online Multi-Person Tracking-by-Detection from a Single, Uncalibrated Camera

In this paper, we address the problem of automatically detecting and tracking a variable number of persons in complex scenes using a monocular, potentially moving, uncalibrated camera. We propose a novel approach for multi-person tracking-bydetection in a particle filtering framework. In addition to final high-confidence detections, our algorithm uses the continuous confidence of pedestrian detectors and online trained, instance-specific classifiers as a graded observation model. Thus, generic object category knowledge is complemented by instance-specific information. The main contribution of this paper is to explore how these unreliable information sources can be used for robust multi-person tracking. The algorithm detects and tracks a large number of dynamically moving persons in complex scenes with occlusions, does not rely on background modeling, requires no camera or ground plane calibration, and only makes use of information from the past. Hence, it imposes very few restrictions and is suitable for online applications. Our experiments show that the method yields good tracking performance in a large variety of highly dynamic scenarios, such as typical surveillance videos, webcam footage, or sports sequences. We demonstrate that our algorithm outperforms other methods that rely on additional information. Furthermore, we analyze the influence of different algorithm components on the robustness.
@article{Breitenstein:2011:OMT:2006854.2007007,
author = {Breitenstein, Michael D. and Reichlin, Fabian and Leibe, Bastian and Koller-Meier, Esther and Van Gool, Luc},
title = {Online Multiperson Tracking-by-Detection from a Single, Uncalibrated Camera},
journal = {IEEE Trans. Pattern Anal. Mach. Intell.},
issue_date = {September 2011},
volume = {33},
number = {9},
month = sep,
year = {2011},
issn = {0162-8828},
pages = {1820--1833},
numpages = {14},
url = {http://dx.doi.org/10.1109/TPAMI.2010.232},
doi = {10.1109/TPAMI.2010.232},
acmid = {2007007},
publisher = {IEEE Computer Society},
address = {Washington, DC, USA},
keywords = {Multi-object tracking, tracking-by-detection, detector confidence particle filter, pedestrian detection, particle filtering, sequential Monte Carlo estimation, online learning, detector confidence, surveillance, sports analysis, traffic safety.},
}
Global Structure Optimization of Quadrilateral Meshes

We introduce a fully automatic algorithm which optimizes the high-level structure of a given quadrilateral mesh to achieve a coarser quadrangular base complex. Such a topological optimization is highly desirable, since state-of-the-art quadrangulation techniques lead to meshes which have an appropriate singularity distribution and an anisotropic element alignment, but usually they are still far away from the high-level structure which is typical for carefully designed meshes manually created by specialists and used e.g. in animation or simulation. In this paper we show that the quality of the high-level structure is negatively affected by helical configurations within the quadrilateral mesh. Consequently we present an algorithm which detects helices and is able to remove most of them by applying a novel grid preserving simplification operator (GP-operator) which is guaranteed to maintain an all-quadrilateral mesh. Additionally it preserves the given singularity distribution and in particular does not introduce new singularities. For each helix we construct a directed graph in which cycles through the start vertex encode operations to remove the corresponding helix. Therefore a simple graph search algorithm can be performed iteratively to remove as many helices as possible and thus improve the high-level structure in a greedy fashion. We demonstrate the usefulness of our automatic structure optimization technique by showing several examples with varying complexity.
Procedural Modeling of Interconnected Structures

The complexity and detail of geometric scenes that are used in today's computer animated films and interactive games have reached a level where the manual creation by traditional 3D modeling tools has become infeasible. This is why procedural modeling concepts have been developed which generate highly complex 3D models by automatically executing a set of formal construction rules. Well-known examples are variants of L-systems which describe the bottom-up growth process of plants and shape grammars which define architectural buildings by decomposing blocks in a top-down fashion. However, none of these approaches allows for the easy generation of interconnected structures such as bridges or roller coasters where a functional interaction between rigid and deformable parts of an object is needed. Our approach mainly relies on the top-down decomposition principle of shape grammars to create an arbitrarily complex but well structured layout. During this process, potential attaching points are collected in containers which represent the set of candidates to establish interconnections. Our grammar then uses either abstract connection patterns or geometric queries to determine elements in those containers that are to be connected. The two different types of connections that our system supports are rigid object chains and deformable beams. The former type is constructed by inverse kinematics, the latter by spline interpolation. We demonstrate the descriptive power of our grammar by example models of bridges, roller coasters, and wall-mounted catenaries.
Walking On Broken Mesh: Defect-Tolerant Geodesic Distances and Parameterizations

Efficient methods to compute intrinsic distances and geodesic paths have been presented for various types of surface representations, most importantly polygon meshes. These meshes are usually assumed to be well-structured and manifold. In practice, however, they often contain defects like holes, gaps, degeneracies, non-manifold configurations – or they might even be just a soup of polygons. The task of repairing these defects is computationally complex and in many cases exhibits various ambiguities demanding tedious manual efforts. We present a computational framework that enables the computation of meaningful approximate intrinsic distances and geodesic paths on raw meshes in a way which is tolerant to such defects. Holes and gaps are bridged up to a user-specified tolerance threshold such that distances can be computed plausibly even across multiple connected components of inconsistent meshes. Further, we show ways to locally parameterize a surface based on geodesic distance fields, easily facilitating the application of textures and decals on raw meshes. We do all this without explicitly repairing the input, thereby avoiding the costly additional efforts. In order to enable broad applicability we provide details on two implementation variants, one optimized for performance, the other optimized for memory efficiency. Using the presented framework many applications can readily be extended to deal with imperfect meshes. Since we abstract from the input applicability is not even limited to meshes, other representations can be handled as well.
Robust Real-Time Deformation of Incompressible Surface Meshes

We introduce an efficient technique for robustly simulating incompressible objects with thousands of elements in real-time. Instead of considering a tetrahedral model, commonly used to simulate volumetric bodies, we simply use their surfaces. Not requiring hundreds or even thousands of elements in the interior of the object enables us to simulate more elements on the surface, resulting in high quality deformations at low computation costs. The elasticity of the objects is robustly simulated with a geometrically motivated shape matching approach which is extended by a fast summation technique for arbitrary triangle meshes suitable for an efficient parallel computation on the GPU. Moreover, we present an oscillation-free and collision-aware volume constraint, purely based on the surface of the incompressible body. The novel heuristic we propose in our approach enables us to conserve the volume, both globally and locally. Our volume constraint is not limited to the shape matching method and can be used with any method simulating the elasticity of an object. We present several examples which demonstrate high quality volume conserving deformations and compare the run-times of our CPU implementation, as well as our GPU implementation with similar methods.
SCA 2011 Honorable Mention
@INPROCEEDINGS{Diziol2011,
author = {Raphael Diziol and Jan Bender and Daniel Bayer},
title = {Robust Real-Time Deformation of Incompressible Surface Meshes},
booktitle = {Proceedings of the 2011 ACM SIGGRAPH/Eurographics Symposium on Computer
Animation},
year = {2011},
publisher = {Eurographics Association},
location = {Vancouver, Canada}
}
Online Loop Closure for Real-time Interactive 3D Scanning

We present a real-time interactive 3D scanning system that allows users to scan complete object geometry by turning the object around in front of a real-time 3D range scanner. The incoming 3D surface patches are registered and integrated into an online 3D point cloud. In contrast to previous systems the online reconstructed 3D model also serves as final result. Registration error accumulation which leads to the well-known loop closure problem is addressed already during the scanning session by distorting the object as rigidly as possible. Scanning errors are removed by explicitly handling outliers based on visibility constraints. Thus, no additional post-processing is required which otherwise might lead to artifacts in the model reconstruction. Both geometry and texture are used for registration which allows for a wide range of objects with different geometric and photometric properties to be scanned. We show the results of our modeling approach on several difficult real-world objects. Qualitative and quantitative results are given for both synthetic and real data demonstrating the importance of online loop closure and outlier handling for model reconstruction. We show that our real-time scanning system has comparable accuracy to offline methods with the additional benefit of immediate feedback and results.
@article{DBLP:journals/cviu/WeiseWLG11,
author = {Thibaut Weise and
Thomas Wismer and
Bastian Leibe and
Luc J. Van Gool},
title = {Online loop closure for real-time interactive 3D scanning},
journal = {Computer Vision and Image Understanding},
volume = {115},
number = {5},
pages = {635--648},
year = {2011},
url = {http://dx.doi.org/10.1016/j.cviu.2010.11.023},
doi = {10.1016/j.cviu.2010.11.023},
timestamp = {Mon, 18 Apr 2011 08:20:18 +0200},
biburl = {http://dblp.uni-trier.de/rec/bib/journals/cviu/WeiseWLG11},
bibsource = {dblp computer science bibliography, http://dblp.org}
}
Efficient and Accurate Urban Outdoor Radio Wave Propagation
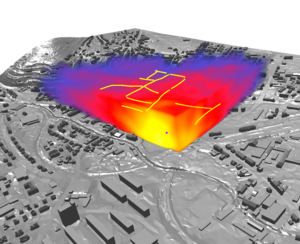
Simulating Radio Wave Propagation using geometrical optics is a well known method. We introduce and compare a simplified 2D beam tracing and a very general 3D ray tracing approach, called photon path tracing. Both methods are designed for outdoor, urban scenarios. The 2D approach is computationally less expensive and can still model an important part of propagation effects. The 3D approach is more general, and not limited to outdoor scenarios, and does not impose constraints or assumptions on the scene geometry. We develop methods to adapt the simulation parameters to real measurements and compare the accuracy of both presented algorithms.
Fast PRISM: Branch and Bound Hough Transform for Object Class Detection
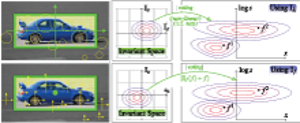
This paper addresses the task of efficient object class detection by means of the Hough transform. This approach has been made popular by the Implicit Shape Model (ISM) and has been adopted many times. Although ISM exhibits robust detection performance, its probabilistic formulation is unsatisfactory. The PRincipled Implicit Shape Model (PRISM) overcomes these problems by interpreting Hough voting as a dual implementation of linear sliding-window detection. It thereby gives a sound justification to the voting procedure and imposes minimal constraints. We demonstrate PRISM’s flexibility by two complementary implementations: a generatively trained Gaussian Mixture Model as well as a discriminatively trained histogram approach. Both systems achieve state-of-the-art performance. Detections are found by gradient-based or branch and bound search, respectively. The latter greatly benefits from PRISM’s feature-centric view. It thereby avoids the unfavorable memory trade-off and any on-line pre-processing of the original Efficient Subwindow Search (ESS). Moreover, our approach takes account of the features’ scale value while ESS does not. Finally, we show how to avoid soft-matching and spatial pyramid descriptors during detection without losing their positive effect. This makes algorithms simpler and faster. Both are possible if the object model is properly regularized and we discuss a modification of SVMs which allows for doing so.
@article{DBLP:journals/ijcv/LehmannLG11,
author = {Alain D. Lehmann and
Bastian Leibe and
Luc J. Van Gool},
title = {Fast {PRISM:} Branch and Bound Hough Transform for Object Class Detection},
journal = {International Journal of Computer Vision},
volume = {94},
number = {2},
pages = {175--197},
year = {2011},
url = {http://dx.doi.org/10.1007/s11263-010-0342-x},
doi = {10.1007/s11263-010-0342-x},
timestamp = {Wed, 19 Feb 2014 09:33:24 +0100},
biburl = {http://dblp.uni-trier.de/rec/bib/journals/ijcv/LehmannLG11},
bibsource = {dblp computer science bibliography, http://dblp.org}
}
Online Estimation of B-Spline Mixture Models From TOF-PET List-Mode Data
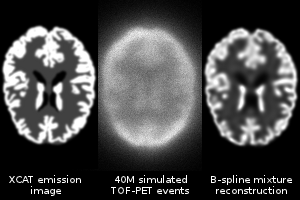
In emission tomography, images are usually represented by regular grids of voxels or overlapping smooth image elements (blobs). Few other image models have been proposed like tetrahedral meshes or point clouds that are adapted to an anatomical image. This work proposes a practical sparse and continuous image model inspired from the field of parametric density estimation for Gaussian mixture models. The position, size, aspect ratio and orientation of each image element is optimized as well as its weight with a very fast online estimation method. Furthermore, the number of mixture components, hence the image resolution, is locally adapted according to the available data. The system model is represented in the same basis as image elements and captures time of flight and positron range effects in an exact way. Computations use apodized B-spline approximations of Gaussians and simple closed-form analytical expressions without any sampling or interpolation. In consequence, the reconstructed image never suffers from spurious aliasing artifacts. Noiseless images of the XCAT brain phantom were reconstructed from simulated data.
Simulating inextensible cloth using locking-free triangle meshes

This paper presents an efficient method for the dynamic simulation of inextensible cloth. The triangle mesh for our cloth model is simulated using an impulse-based approach which is able to solve hard constraints. Using hard distance constraints on the edges of the triangle mesh removes too many degrees of freedom, resulting in a rigid motion. This is known as the locking problem which is typically solved by using rectangular meshes in existing impulse-based simulations. We solve this problem by using a nonconforming representation for the simulation model which unfortunately results in a discontinuous mesh. Therefore, we couple the original conforming mesh with the nonconforming elements and use it for collision handling and visualization.
@inproceedings{Bender11,
author = {Jan Bender and Raphael Diziol and Daniel Bayer},
title = {Simulating inextensible cloth using locking-free triangle meshes},
booktitle = {Virtual Reality Interactions and Physical Simulations (VRIPhys)},
year = {2011},
month = dec,
address = {Lyon (France)},
pages = {11-17}
}
Real Time Vision Based Multi-person Tracking for Mobile Robotics and Intelligent Vehicles
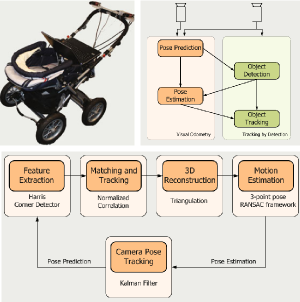
In this paper, we present a real-time vision-based multiperson tracking system working in crowded urban environments. Our approach combines stereo visual odometry estimation, HOG pedestrian detection, and multi-hypothesis tracking-by-detection to a robust tracking framework that runs on a single laptop with a CUDA-enabled graphics card. Through shifting the expensive computations to the GPU and making extensive use of scene geometry constraints we could build up a mobile system that runs with 10Hz. We experimentally demonstrate on several challenging sequences that our approach achieves competitive tracking performance.
@inproceedings{DBLP:conf/icira/MitzelFSZL11,
author = {Dennis Mitzel and
Georgios Floros and
Patrick Sudowe and
Benito van der Zander and
Bastian Leibe},
title = {Real Time Vision Based Multi-person Tracking for Mobile Robotics and
Intelligent Vehicles},
booktitle = {Intelligent Robotics and Applications - 4th International Conference,
{ICIRA} 2011, Aachen, Germany, December 6-8, 2011, Proceedings, Part
{II}},
pages = {105--115},
year = {2011},
crossref = {DBLP:conf/icira/2011-2},
url = {http://dx.doi.org/10.1007/978-3-642-25489-5_11},
doi = {10.1007/978-3-642-25489-5_11},
timestamp = {Fri, 02 Dec 2011 12:36:17 +0100},
biburl = {http://dblp.uni-trier.de/rec/bib/conf/icira/MitzelFSZL11},
bibsource = {dblp computer science bibliography, http://dblp.org}
}
Efficient Use of Geometric Constraints for Sliding-Window Object Detection in Video

We systematically investigate how geometric constraints can be used for efficient sliding-window object detection. Starting with a general characterization of the space of sliding-window locations that correspond to geometrically valid object detections, we derive a general algorithm for incorporating ground plane constraints directly into the detector computation. Our approach is indifferent to the choice of detection algorithm and can be applied in a wide range of scenarios. In particular, it allows to effortlessly combine multiple different detectors and to automatically compute regions-of-interest for each of them. We demonstrate its potential in a fast CUDA implementation of the HOG detector and show that our algorithm enables a factor 2-4 speed improvement on top of all other optimizations.
Bibtex:
@InProceedings{Sudowe11ICVS,
author = {P. Sudowe and B. Leibe},
title = {{Efficient Use of Geometric Constraints for Sliding-Window Object Detection in Video}},
booktitle = {{International Conference on Computer Vision Systems (ICVS'11)}},
OPTpages = {},
year = {2011},
}
Visualizing Acoustical Simulation Data in Immersive Virtual Environments

In this contribution, we present an immersive visualization of room acoustical simulation data. In contrast to the commonly employed external viewpoint, our approach places the user inside the visualized data. The main problem with this technique is the occlusion of some data points by others. We present different solutions for this problem that allow an interactive analysis of the simulation data.
A Sketching Interface for Feature Curve Recovery of Free-Form Surfaces
Special issue on The 2009 SIAM/ACM Joint Conference on Geometric and Physical Modeling
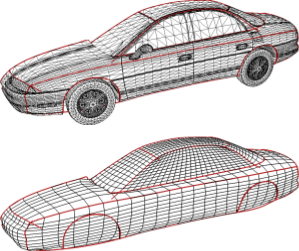
In this paper, we present a semi-automatic approach to efficiently and robustly recover the characteristic feature curves of a given free-form surface where we do not have to assume that the input is a proper manifold. The technique supports a sketch-based interface where the user just has to roughly sketch the location of a feature by drawing a stroke directly on the input mesh. The system then snaps this initial curve to the correct position based on a graph-cut optimization scheme that takes various surface properties into account. Additional position constraints can be placed and modified manually which allows for an interactive feature curve editing functionality. We demonstrate the usefulness of our technique by applying it to two practical scenarios. At first, feature curves can be used as handles for surface deformation, since they describe the main characteristics of an object. Our system allows the user to manipulate a curve while the underlying non-manifold surface adopts itself to the deformed feature. Secondly, we apply our technique to a practical problem scenario in reverse engineering. Here, we consider the problem of generating a statistical (PCA) shape model for car bodies. The crucial step is to establish proper feature correspondences between a large number of input models. Due to the significant shape variation, fully automatic techniques are doomed to failure. With our simple and effective feature curve recovery tool, we can quickly sketch a set of characteristic features on each input model which establishes the correspondence to a pre-defined template mesh and thus allows us to generate the shape model. Finally, we can use the feature curves and the shape model to implement an intuitive modeling metaphor to explore the shape space spanned by the input models.
The paper is an extended version of the paper "A sketching interface for feature curve recovery of free-form surfaces" published at the 2009 SIAM/ACM Joint Conference on Geometric and Physical Modeling. In this extended version, we presend a second application where we use the recovered feature curves as modeling handles for surface deformation.
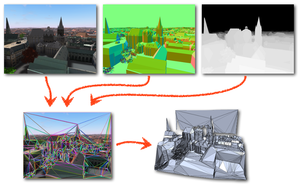
Realtime Compositing of Procedural Facade Textures on the GPU

The real time rendering of complex virtual city models has become more important in the last few years for many practical applications like realistic navigation or urban planning. For maximum rendering performance, the complexity of the geometry or textures can be reduced by decreasing the resolution until the data set can fully reside on the memory of the graphics card. This typically results in a low quality of the virtual city model. Alternatively, a streaming algorithm can load the high quality data set from the hard drive. However, this approach requires a large amount of persistent storage providing several gigabytes of static data. We present a system that uses a texture atlas containing atomic tiles like windows, doors or wall patterns, and that combines those elements on-the-fly directly on the graphics card. The presented approach benefits from a sophisticated randomization approach that produces lots of different facades while the grammar description itself remains small. By using a ray casting apporach, we are able to trace through transparent windows revealing procedurally generated rooms which further contributes to the realism of the rendering. The presented method enables real time rendering of city models with a high level of detail for facades while still relying on a small memory footprint.
Bimanual Haptic Simulator for Medical Training: System Architecture and Performance Measurements
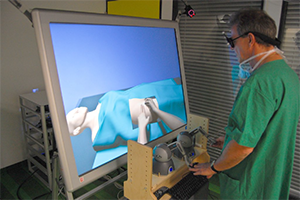
In this paper we present a simulator for two-handed haptic interaction. As an application example, we chose a medical scenario that requires simultaneous interaction with a hand and a needle on a simulated patient. The system combines bimanual haptic interaction with a physics-based soft tissue simulation. To our knowledge the combination of finite element methods for the simulation of deformable objects with haptic rendering is seldom addressed, especially with two haptic devices in a non-trivial scenario. Challenges are to find a balance between real-time constraints and high computational demands for fidelity in simulation and to synchronize data between system components. The system has been successfully implemented and tested on two different hardware platforms: one mobile on a laptop and another stationary on a semi-immersive VR system. These two platforms have been chosen to demonstrate scaleability in terms of fidelity and costs. To compare performance and estimate latency, we measured timings of update loops and logged event-based timings of several components in the software.
@inproceedings {EGVE:JVRC11:039-046,
booktitle = {Joint Virtual Reality Conference of EGVE - EuroVR},
editor = {Sabine Coquillart and Anthony Steed and Greg Welch},
title = {{Bimanual Haptic Simulator for Medical Training: System Architecture and Performance Measurements}},
author = {Ullrich, Sebastian and Rausch, Dominik and Kuhlen, Torsten},
year = {2011},
pages={39--46},
publisher = {The Eurographics Association},
DOI = {10.2312/EGVE/JVRC11/039-046}
}
Markerless Reconstruction and Synthesis of Dynamic Facial Expressions
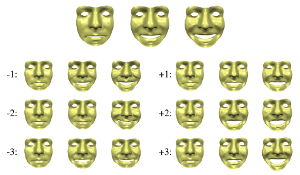
In this paper we combine methods from the field of computer vision with surface editing techniques to generate animated faces, which are all in full correspondence to each other. The inputs for our system are synchronized video streams from multiple cameras. The system produces a sequence of triangle meshes with fixed connectivity, representing the dynamics of the captured face. By carefully taking all requirements and characteristics into account we decided for the proposed system design: We deform an initial face template using movements estimated from the video streams. To increase the robustness of the reconstruction, we use a morphable model as a shape prior to initialize a surfel fitting technique which is able to precisely capture face shapes not included in the morphable model. In the deformation stage, we use a 2D mesh-based tracking approach to establish correspondences over time. We then reconstruct positions in 3D using the same surfel fitting technique, and finally use the reconstructed points to robustly deform the initially reconstructed face.
This paper is an extended version of our paper "Markerless Reconstruction of Dynamic Facial Expressions" which was published 2009 at 3-D Digital Imaging and Modeling. Besides describing the reconstruction of human faces in more detail we demonstrate the applicability of the tracked face template for automatic modeling and show how to use deformation transfer to attenuate expressions, blend expressions or how to build a statistical model, similar to a morphable model, on the dynamic movements.
Pseudo-Immersive Real-Time Display of 3D Scenes on Mobile Devices
The display of complex 3D scenes in real-time on mobile devices is difficult due to the insufficient data throughput and a relatively weak graphics performance. Hence, we propose a client-server system, where the processing of the complex scene is performed on a server and the resulting data is streamed to the mobile device. In order to cope with low transmission bitrates, the server sends new data only with a framerate of about 2 Hz. However, instead of sending plain framebuffers, the server decomposes the geometry represented by the current view's depth profile into a small set of textured polygons. This processing does not require the knowledge of geometries in the scene, i.e. the outputs of Time-of-flight camera can be handled as well. The 2.5D representation of the current frame allows the mobile device to render plausibly distorted views of the scene at high frame rates as long as the viewing direction does not change too much before the next frame arrives from the server. In order to further augment the visual experience, we use the mobile device's built-in camera or gyroscope to detect the spatial relation between the user's face and the device, so that the camera view can be changed accordingly. This produces a pseudo-immersive visual effect. Besides designing the overall system with a render-server, 3D display client, and real-time face/pose detection, our main technical contribution is a highly efficient algorithm that decomposes a frame buffer with per-pixel depth and normal information into a small set of planar regions which can be textured with the current frame. This representation is simple enough for realtime display on today's mobile devices.
Efficient Object Detection and Segmentation with a Cascaded Hough Forest ISM

Visual pedestrian/car detection is very important for mobile robotics in complex outdoor scenarios. In this paper, we propose two improvements to the popular Hough Forest object detection framework. We show how this framework can be extended to efficiently infer precise probabilistic segmentations for the object hypotheses and how those segmentations can be used to improve the final hypothesis selection. Our approach benefits from the dense sampling of a Hough Forest detector, which results in qualitatively better segmentations than previous voting based methods. We show that, compared to previous approaches, the dense feature sampling necessitates several adaptations to the segmentation framework and propose an improved formulation. In addition, we propose an efficient cascaded voting scheme that significantly reduces the effort of the Hough voting stage without loss in accuracy. We quantitatively evaluate our approach on several challenging sequences, reaching stateof-the-art performance and showing the effectiveness of the proposed framework.
@inproceedings{DBLP:conf/iccvw/RematasL11,
author = {Konstantinos Rematas and
Bastian Leibe},
title = {Efficient object detection and segmentation with a cascaded Hough
Forest {ISM}},
booktitle = {{IEEE} International Conference on Computer Vision Workshops, {ICCV}
2011 Workshops, Barcelona, Spain, November 6-13, 2011},
pages = {966--973},
year = {2011},
crossref = {DBLP:conf/iccvw/2011},
url = {http://dx.doi.org/10.1109/ICCVW.2011.6130356},
doi = {10.1109/ICCVW.2011.6130356},
timestamp = {Fri, 20 Jan 2012 17:21:11 +0100},
biburl = {http://dblp.uni-trier.de/rec/bib/conf/iccvw/RematasL11},
bibsource = {dblp computer science bibliography, http://dblp.org}
}
Real-Time Multi-Person Tracking with Detector Assisted Structure Propagation

Classical tracking-by-detection approaches require a robust object detector that needs to be executed in each frame. However the detector is typically the most computationally expensive component, especially if more than one object class needs to be detected. In this paper we investigate how the usage of the object detector can be reduced by using stereo range data for following detected objects over time. To this end we propose a hybrid tracking framework consisting of a stereo based ICP (Iterative Closest Point) tracker and a high-level multi-hypothesis tracker. Initiated by a detector response, the ICP tracker follows individual pedestrians over time using just the raw depth information. Its output is then fed into the high-level tracker that is responsible for solving long-term data association and occlusion handling. In addition, we propose to constrain the detector to run only on some small regions of interest (ROIs) that are extracted from a 3D depth based occupancy map of the scene. The ROIs are tracked over time and only newly appearing ROIs are evaluated by the detector. We present experiments on real stereo sequences recorded from a moving camera setup in urban scenarios and show that our proposed approach achieves state of the art performance
@inproceedings{DBLP:conf/iccvw/MitzelL11,
author = {Dennis Mitzel and
Bastian Leibe},
title = {Real-time multi-person tracking with detector assisted structure propagation},
booktitle = {{IEEE} International Conference on Computer Vision Workshops, {ICCV}
2011 Workshops, Barcelona, Spain, November 6-13, 2011},
pages = {974--981},
year = {2011},
crossref = {DBLP:conf/iccvw/2011},
url = {http://dx.doi.org/10.1109/ICCVW.2011.6130357},
doi = {10.1109/ICCVW.2011.6130357},
timestamp = {Fri, 20 Jan 2012 17:21:11 +0100},
biburl = {http://dblp.uni-trier.de/rec/bib/conf/iccvw/MitzelL11},
bibsource = {dblp computer science bibliography, http://dblp.org}
}
OpenFlipper: An Open Source Geometry Processing and Rendering Framework
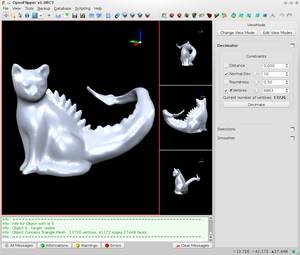
In this paper we present OpenFlipper, an extensible open source geometry processing and rendering framework. OpenFlipper is a free software toolkit and software development platform for geometry processing algorithms. It is mainly developed in the context of various academic research projects. Nevertheless some companies are already using it as a toolkit for commercial applications. This article presents the design goals for OpenFlipper, the central usability considerations and the important steps that were taken to achieve them. We give some examples of commercial applications which illustrate the exibility of OpenFlipper. Besides software developers, end users also bene t from this common framework since all applications built on top of it share the same basic functionality and interaction metaphors.
Figure-Ground Segmentation - Object Based

Tracking with a moving camera is a challenging task due to the combined effects of scene activity and egomotion. As there is no longer a static image background from which moving objects can easily be distinguished, dedicated effort must be spent on detecting objects of interest in the input images and on determining their precise extent. In recent years, there has been considerable progress in the development of approaches that apply object detection and class-specific segmentation in order to facilitate tracking under such circumstances (“tracking-by-detection”). In this chapter, we will give an overview of the main concepts and techniques used in such tracking-by-detection systems. In detail, the chapter will present fundamental techniques and current state-of-the-art approaches for performing object detection, for obtaining detailed object segmentations from single images based on top–down and bottom–up cues, and for propagating this information over time.
Visual Object Recognition

The visual recognition problem is central to computer vision research. From robotics to information retrieval, many desired applications demand the ability to identify and localize categories, places, and objects. This tutorial overviews computer vision algorithms for visual object recognition and image classification. We introduce primary representations and learning approaches, with an emphasis on recent advances in the field. The target audience consists of researchers or students working in AI, robotics, or vision who would like to understand what methods and representations are available for these problems. This lecture summarizes what is and isn't possible to do reliably today, and overviews key concepts that could be employed in systems requiring visual categorization.
Table of Contents: Introduction / Overview: Recognition of Specific Objects / Local Features: Detection and Description / Matching Local Features / Geometric Verification of Matched Features / Example Systems: Specific-Object Recognition / Overview: Recognition of Generic Object Categories / Representations for Object Categories / Generic Object Detection: Finding and Scoring Candidates / Learning Generic Object Category Models / Example Systems: Generic Object Recognition / Other Considerations and Current Challenges / Conclusions
Efficiently Navigating Data Sets Using the Hierarchy Browser

A major challenge in Virtual Reality is to enable users to efficiently explore virtual environments, regardless of prior knowledge. This is particularly true for complex virtual scenes containing a huge amount of potential areas of interest. Providing the user convenient access to these areas is of prime importance, just like supporting her to orient herself in the virtual scene. There exist techniques for either aspect, but combining these techniques into one holistic system is not trivial. To address this issue, we present the Hierarchy Browser. It supports the user in creating a mental image of the scene. This is done by offering a well-arranged, hierarchical visual representation of the scene structure as well as interaction techniques to browse it. Additional interaction allows to trigger a scene manipulation, e.g. an automated travel to a desired area of interest. We evaluate the Hierarchy Browser by means of an expert walkthrough.
@Article{Boensch2011,
Title = {{E}fficiently {N}avigating {D}ata {S}ets {U}sing the {H}ierarchy {B}rowser},
Author = {Andrea B\"{o}nsch and Sebastian Pick and Bernd Hentschel and Torsten Kuhlen},
Journal = {{V}irtuelle und {E}rweiterte {R}ealit\"at, 8. {W}orkshop der {GI}-{F}achgruppe {VR}/{AR}},
Year = {2011},
Pages = {37-48},
ISSN = {978-3-8440-0394-9}
Publisher = {Shaker Verlag}
}
Previous Year (2010)
