
Publications
Towards Metric-Agnostic Trajectory Forecasting

Accurate trajectory forecasting of surrounding traffic participants is a core capability for autonomous driving, enabling vehicles to anticipate behavior and plan safe maneuvers. We observe that current state-of-the-art forecasting models on Argoverse 2 and the Waymo Open Motion Dataset tailor their training objectives to the different benchmark metrics. Because these metrics encourage conflicting behavior, we propose a paradigm change for trajectory forecasting: training models with metric-agnostic probabilistic objectives and treating metric optimization as a downstream task applied to the predictive distribution. Concretely, we introduce Trajectory Distribution Evaluation (TraDiE) policies, metric-specific policies that map a predictive distribution to the set of K trajectories and confidences required by trajectory forecasting metrics. We evaluate this framework by introducing DONUT-NLL, which adapts the training objective of the state-of-the-art trajectory forecasting model DONUT to directly optimize the predictive distribution. Using our policies, DONUT-NLL achieves state-of-the-art results on all metrics of the Waymo motion prediction benchmark.
@inproceedings{knoche2026tradie,
title = {{Towards Metric-Agnostic Trajectory Forecasting}},
author = {Knoche, Markus and de Geus, Daan and Leibe, Bastian},
booktitle = {ECCV},
year = {2026}
}
Block-Sparse Global Attention for Efficient Multi-View Geometry Transformers
Efficient and accurate feed-forward multi-view reconstruction has long been an important task in computer vision. Recent transformer-based models like VGGT, $\pi^3$ and MapAnything have demonstrated remarkable performance with relatively simple architectures. However, their scalability is fundamentally constrained by the quadratic complexity of global attention, which imposes a significant runtime bottleneck when processing large image sets. In this work, we empirically analyze the global attention matrix of these models and observe that the probability mass concentrates on a small subset of patch-patch interactions corresponding to cross-view geometric correspondences. Building on this insight and inspired by recent advances in large language models, we propose a training-free, block-sparse replacement for dense global attention, implemented with highly optimized kernels. Our method accelerates inference by more than 3x while maintaining comparable task performance. Evaluations on a comprehensive suite of multi-view benchmarks demonstrate that our approach seamlessly integrates into existing global attention-based architectures such as VGGT, $\pi^3$, and MapAnything, while substantiallyimproving scalability to large image collections.
VidEoMT: Your ViT is Secretly Also a Video Segmentation Model

Existing online video segmentation models typically combine a per-frame segmenter with complex specialized tracking modules. While effective, these modules introduce significant architectural complexity and computational overhead. Recent studies suggest that plain Vision Transformer (ViT) encoders, when scaled with sufficient capacity and large-scale pre-training, can conduct accurate image segmentation without requiring specialized modules. Motivated by this observation, we propose the Video Encoder-only Mask Transformer (VidEoMT), a simple encoder-only video segmentation model that eliminates the need for dedicated tracking modules. To enable temporal modeling in an encoder-only ViT, VidEoMT introduces a lightweight query propagation mechanism that carries information across frames by reusing queries from the previous frame. To balance this with adaptability to new content, it employs a query fusion strategy that combines the propagated queries with a set of temporally-agnostic learned queries. As a result, VidEoMT attains the benefits of a tracker without added complexity, achieving competitive accuracy while being 5x--10x faster, running at up to 160 FPS with a ViT-L backbone.
@inproceedings{norouzi2026videomt,
author={Norouzi, Narges and Zulfikar, Idil and Cavagnero, Niccol\`{o} and Kerssies, Tommie and Leibe, Bastian and Dubbelman, Gijs and {de Geus}, Daan},
title={{VidEoMT: Your ViT is Secretly Also a Video Segmentation Model}},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2026}
}
DINO in the Room: Leveraging 2D Foundation Models for 3D Segmentation

Vision foundation models (VFMs) trained on large-scale image datasets provide high-quality features that have significantly advanced 2D visual recognition. However, their potential in 3D scene segmentation remains largely untapped, despite the common availability of 2D images alongside 3D point cloud datasets. While significant research has been dedicated to 2D-3D fusion, recent state-of-the-art 3D methods predominantly focus on 3D data, leaving the integration of VFMs into 3D models underexplored. In this work, we challenge this trend by introducing DITR, a generally applicable approach that extracts 2D foundation model features, projects them to 3D, and finally injects them into a 3D point cloud segmentation model. DITR achieves state-of-the-art results on both indoor and outdoor 3D semantic segmentation benchmarks. To enable the use of VFMs even when images are unavailable during inference, we additionally propose to pretrain 3D models by distilling 2D foundation models. By initializing the 3D backbone with knowledge distilled from 2D VFMs, we create a strong basis for downstream 3D segmentation tasks, ultimately boosting performance across various datasets.
@InProceedings{knaebel2025ditr,
title = {{DINO} in the Room: Leveraging {2D} Foundation Models for {3D} Segmentation},
author = {Knaebel, Karim and Yilmaz, Kadir and de Geus, Daan and Hermans, Alexander and Adrian, David and Linder, Timm and Leibe, Bastian},
booktitle = {2026 International Conference on 3D Vision (3DV)},
year = {2026}
}
Objectifying Social Presence: Evaluating Multimodal Degraders in ECAs Using the Heard Text Recall Paradigm

Embodied conversational agents (ECAs) are key social interaction partners in various virtual reality (VR) applications, with their perceived social presence significantly influencing the quality and effectiveness of user-ECA interactions. This paper investigates the potential of the Heard Text Recall (HTR) paradigm as an indirect objective proxy for evaluating social presence, which is traditionally assessed through subjective questionnaires. To this end, we use the HTR task, which was primarily designed to assess memory performance in listening tasks, in a dual-task paradigm to assess cognitive spare capacity and correlate the latter with subjectively-rated social presence. As a prerequisite for this investigation, we introduce various co-verbal gesture modification techniques and assess their impact on the perceived naturalness of the presenting ECA, a crucial aspect fostering social presence. The main study then explores the applicability of HTR as a proxy for social presence by examining its effectiveness under different multimodal degraders of ECA behavior, including degraded co-verbal gestures, omitted lip synchronization, and the use of synthetic voices. The findings suggest that while HTR shows potential as an objective measure of social presence, its effectiveness is primarily evident in response to substantial changes in ECA behavior. Additionally, the study also highlights the negative effects of synthetic voices and inadequate lip synchronization on perceived social presence, emphasizing the need for careful consideration of these elements in ECA design.
@ARTICLE{Ehret2026,
author={Ehret, Jonathan and Schüppen, Jonas and Mohanathasan, Chinthusa and Ermert, Cosima A. and Fels, Janina and Schlittmeier, Sabine J. and Kuhlen, Torsten W. and Bönsch, Andrea},
journal={IEEE Transactions on Visualization and Computer Graphics},
title={Objectifying Social Presence: Evaluating Multimodal Degraders in ECAs Using the Heard Text Recall Paradigm},
year={2026},
volume={32},
number={2},
pages={2312-2325},
doi={10.1109/TVCG.2025.3636079}
}
How Far is Too Far? The Trade-Off between Selection Distance and Accuracy during Teleportation in Immersive Virtual Reality

Target-selection-based teleportation is one of the most widely used and researched travel techniques in immersive virtual environments, requiring the user to specify a target location with a selection ray before being transported there. This work explores the influence of the maximum reach of the parabolic selection ray, modeled by different emission velocities of the projectile motion equation, and compares the resulting teleportation performance to a straight ray as the baseline. In a user study with 60 participants, we asked participants to teleport as far as possible while still remaining within accuracy constraints to understand how the theoretical implications of the projectile motion equation apply to a realistic VR use case. We found that a projectile emission velocity of 14 m/s (resulting in a maximal reach of 21.52 m) offered the best trade-off between selection distance and accuracy, with an inferior performance of the straight ray. Our results demonstrate the necessity to carefully set and report the projectile emission velocity in future work, as it was shown to directly influence user-selected distance, selection errors, and controller height during selection.
@ARTICLE{Rupp2026b,
author={Rupp, Daniel and Weissker, Tim and Wölwer, Matthias and Kuhlen, Torsten W. and Zielasko, Daniel},
journal={IEEE Transactions on Visualization and Computer Graphics},
title={How Far is Too Far? The Trade-Off Between Selection Distance and Accuracy During Teleportation in Immersive Virtual Reality},
year={2026},
volume={32},
number={2},
pages={1864-1878},
doi={10.1109/TVCG.2025.3632345}
}
SATOR: Seamless 3D Teleportation to both Ground and Mid-Air Targets

Traditional target-selection-based teleportation depends on the intersection of a (curved) ray with the scene's geometry, which limits navigation to points on the ground, restricting users' navigational freedom. While previous techniques exist that permit mid-air target selection, they are not optimal for transitioning between air and ground navigation, leading to inaccurate or lengthy interaction sequences. In this paper, we introduce SATOR, a new 3D teleportation technique designed to enable efficient and accurate navigation to both ground and mid-air targets by combining and enhancing previous approaches. Informed by the literature, we implemented four different parametrizations of our technique and compared them to a previously published technique that also enables both ground and mid-air target selection. Our user study with 30 participants indicates that SATOR is more efficient, accurate, and easier to use than the baseline. As a result, SATOR effectively helps users get an overview of the environment, observe features at different heights, or maneuver quickly around larger obstacles.
@ARTICLE{Rupp2026,
author={Rupp, Daniel and Wölwer, Matthias and Kuhlen, Torsten W. and Zielasko, Daniel and Weissker, Tim},
journal={IEEE Transactions on Visualization and Computer Graphics},
title={{SATOR: Seamless 3D Teleportation to both Ground and Mid-Air Targets}},
year={2026},
volume={},
number={},
pages={1-10},
keywords={Projectiles;Weapons;Circuits;Feedback;MIMICs;Millimeter wave integrated circuits;Monolithic integrated circuits;Graphical user interfaces;Videos;Avatars;Virtual Reality;3D User Interfaces;3D Navigation;Head-Mounted Display;Teleportation;Flying;Mid-Air Navigation},
doi={10.1109/TVCG.2026.3679894}}
This Lecture Makes Me Sick: On Confounding Factors Influencing the Simulator Sickness Questionnaire (SSQ)

The Simulator Sickness Questionnaire (SSQ) has become a standard tool for quantifying the severity and distribution of discomfort symptoms in virtual reality (VR) research. Despite its straightforward administration, the use of the SSQ also comes with significant challenges, including response subjectivity, strict threshold values based on a military reference population, and confounding factors influencing the results. To demonstrate the adverse interplay of these issues, we asked three cohorts of students to fill in a SSQ after having attended a 90-minute lecture of our teaching program. Although students were not exposed to any form of VR experience, the resulting SSQ scores were indistinguishable from VR studies and extended far beyond the originally defined threshold of a “bad simulator', with 88.1% of TS scores being larger and 25.4% even exceeding thrice this value. We compare our results to alternative scoring systems of the SSQ proposed in the literature and suggest implications for future experimental designs involving the quantification of sickness symptoms. In summary, our results motivate to exert caution when interpreting the results of the SSQ in the context of a VR study; participants might just have attended a lecture prior to the experiment.
@ARTICLE{Weissker2026a,
author={Weissker, Tim},
journal={IEEE Transactions on Visualization and Computer Graphics},
title={{This Lecture Makes Me Sick: on Confounding Factors Influencing the Simulator Sickness Questionnaire (SSQ)}},
year={2026},
volume={},
number={},
pages={1-7},
keywords={Solid modeling;Particle measurements;Focusing;Cybersickness;Atmospheric measurements;Visualization;Resists;Motion sickness;Education;Anxiety disorders;Virtual Reality;Simulator Sickness;Discomfort;Cybersickness;Nausea},
doi={10.1109/TVCG.2026.3679089}}
Simulation Methods for Multiphysics Phenomena in Visual Computing

Physics simulation is a cornerstone of many computer graphics applications, ranging from video games and virtual reality to visual effects and computational design. The number of techniques for physically-based modeling and animation has thus skyrocketed over the past few decades, facilitating the simulation of a wide variety of materials and physical phenomena. These course notes provide an in-depth introduction to multiphysics simulation methods for computer graphics, covering the mathematical foundations, key algorithms, and practical considerations behind the most widely used approaches. We focus on methods developed by the computer graphics community for simulating various physical phenomena and materials -- including rigid and deformable bodies, fluids, and granular materials -- as well as the interactions between them. For each method, we present the underlying mathematical framework with detailed derivations and discuss how different materials and coupling strategies fit into the formulation. A selection of software frameworks that offer out-of-the-box multiphysics modeling capabilities is also presented. Finally, we touch on emerging trends in physics-based animation, including machine learning-based methods which have become increasingly popular in recent years.
@inproceedings{LJFB2026,
booktitle = {Eurographics 2026 - Tutorials},
title = {{Simulation Methods for Multiphysics Phenomena in Visual Computing}},
author = {Löschner, Fabian and Jeske, Stefan Rhys and Fernández-Fernández, José Antonio and Bender, Jan},
year = {2026},
publisher = {The Eurographics Association},
ISSN = {1017-4656},
ISBN = {978-3-03868-267-7},
DOI = {10.2312/egt.20261002}
}
Progressively Projected Newton’s Method

Newton's Method is widely used to find the solution of complex non-linear simulation problems. To guarantee a descent direction, it is common practice to clamp the negative eigenvalues of each element Hessian prior to assembly — a strategy known as Projected Newton (PN) — but this perturbation often hinders convergence. In this work, we observe that projecting only a small subset of element Hessians is sufficient to secure a descent direction. Building on this insight, we introduce Progressively Projected Newton (PPN), a novel variant of Newton's Method that uses the current iterate's residual to cheaply determine the subset of element Hessians to project. The benefit is twofold: most eigendecompositions are avoided and the global Hessian remains closer to its original form, reducing the number of Newton iterations. We compare PPN with PN and Project-on-Demand Newton (PDN) in a comprehensive set of experiments covering contact-free and contact-rich deformables, co-dimensional and rigid-body simulations, and a range of time step sizes, tolerances and resolutions. PPN reduces the amount of element projections in dynamic simulations by one order of magnitude while simultaneously improving convergence, consistently being the fastest solver in our benchmark.
@article{FLB2026,
title={Progressively Projected Newton's Method},
author={José Antonio Fernández-Fernández and Fabian Löschner and Jan Bender},
year = {2026},
journal = {Computer Graphics Forum (Eurographics)},
volume = {45},
number = {2}
}
Self-supervised Learning of Fine-to-Coarse Cuboid Shape Abstraction
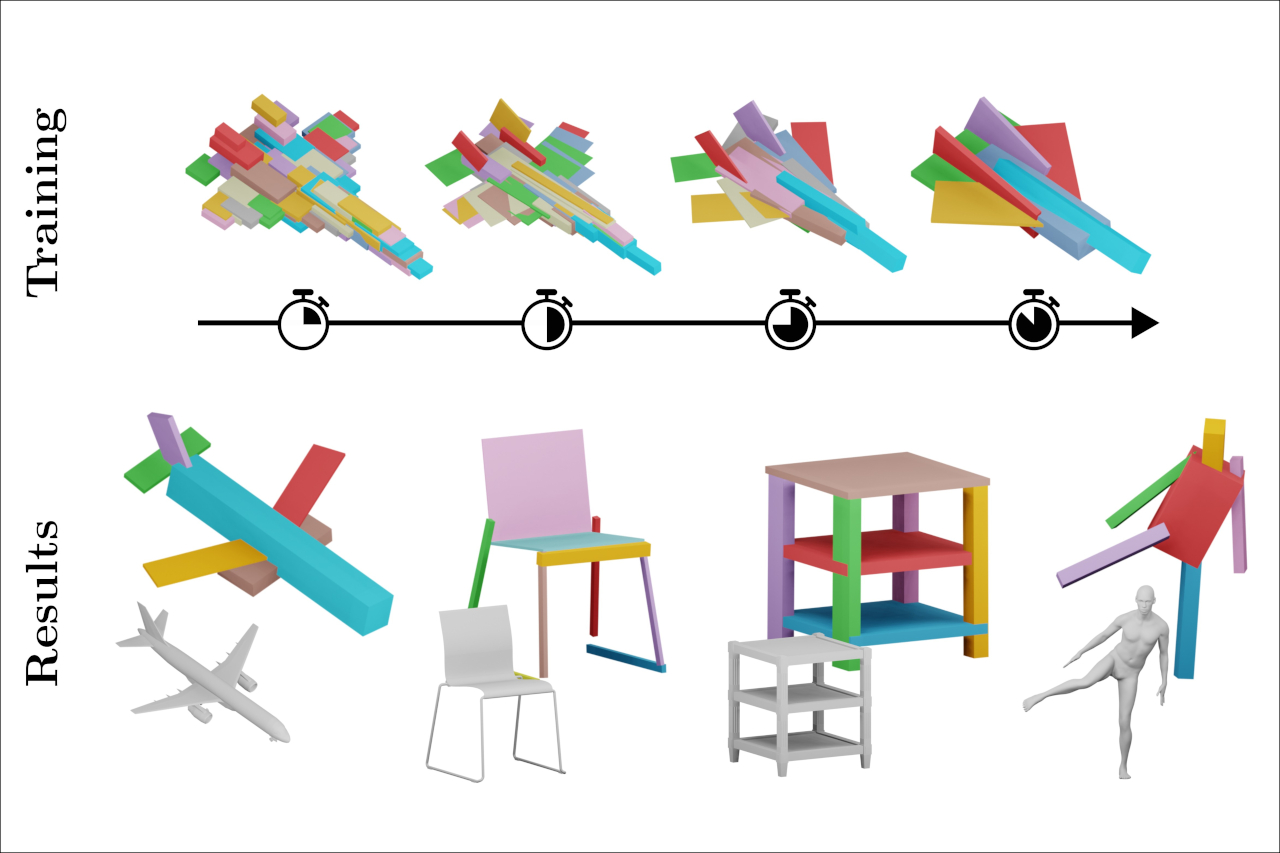
The abstraction of 3D objects with simple geometric primitives like cuboids allows us to infer structural information from complex geometry. It is important for 3D shape understanding, structural analysis and geometric modeling. We introduce a novel fine-to-coarse self-supervised learning approach to abstract collections of 3D shapes. Our architectural design allows us to reduce the number of primitives from hundreds (fine reconstruction) to only a few (coarse abstraction) during training. This allows our network to optimize the reconstruction error and adhere to a user-specified number of primitives per shape while simultaneously learning a consistent structure across the whole collection of data. We achieve this through our abstraction loss formulation which increasingly penalizes redundant primitives. Furthermore, we introduce a reconstruction loss formulation to account not only for surface approximation but also volume preservation. Combining both contributions allows us to represent 3D shapes more precisely with fewer cuboid primitives than previous work. We evaluate our method on collections of man-made and humanoid shapes comparing with previous state-of-the-art learning methods on commonly used benchmarks. Our results confirm an improvement over previous cuboid-based shape abstraction techniques. Furthermore, we demonstrate our cuboid abstraction in downstream tasks like clustering, retrieval, and partial symmetry detection
@article{kobsik2026cuboid,
title={Self-supervised Learning of Fine-to-Coarse Cuboid Shape Abstraction},
author={Kobsik, Gregor and Henkel, Morten and He, Yanjiang and Czech, Victor and Elsner, Tim and Lim, Isaak and Kobbelt, Leif},
year={2026},
journal={Computer Graphics Forum},
volume={45},
number={2},
}
Embedding Optimization of Layouts via Distortion Minimization

Given an embedding of a layout in the surface of a target mesh, we consider the problem of optimizing the embedding geometrically. Layout embeddings partition the surface into multiple disk-like patches, making them particularly useful for parametrization and remeshing tasks, such as quad-remeshing, since these problems can then be solved on simpler subdomains. Existing methods can either not guarantee to maintain patch connectivity, limiting downstream applications, or are specialized for quad layout optimization, relying on principal curvature information. We propose a framework that balances per-patch distortion minimization with strict connectivity control through an explicit representation. By inserting additional nodes along layout arcs, they can be embedded as piecewise geodesic curves on the surface. This sampling of arcs provides additional flexibility where required, enabling joint optimization of both node positions and arc embeddings. Our representation naturally supports a multi-resolution workflow: optimization on coarse meshes can be prolongated to high-resolution inputs. We demonstrate its effectiveness in applications requiring connectivity-preserving, low-distortion surface layouts.
@article{heuschling2026layoutOpt,
title={Embedding Optimization of Layouts via Distortion Minimization},
author={Heuschling, Alexandra and Lim, Isaak and Kobbelt, Leif},
year={2026},
journal={Computer Graphics Forum},
volume={45},
number={2},
}
Beyond Words: The Impact of Static and Animated Faces as Visual Cues on Memory Performance and Listening Effort during Two-Talker Conversations
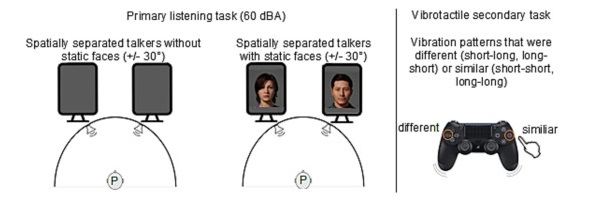
Listening to a conversation between two talkers and recalling the information is a common goal in verbal communication. However, cognitive-psychological experiments on short-term memory performance often rely on rather simple stimulus material, such as unrelated word lists or isolated sentences. The present study uniquely incorporated running speech, such as listening to a two-talker conversation, to investigate whether talker-related visual cues enhance short-term memory performance and reduce listening effort in non-noisy listening settings. In two equivalent dual-task experiments, participants listened to interrelated sentences spoken by two alternating talkers from two spatial positions, with talker-related visual cues presented as either static faces (Experiment 1, n = 30) or animated faces with lip sync (Experiment 2, n = 28). After each conversation, participants answered content-related questions as a measure of short-term memory (via the Heard Text Recall task). In parallel to listening, they performed a vibrotactile pattern recognition task to assess listening effort. Visual cue conditions (static or animated faces) were compared within-subject to a baseline condition without faces. To account for inter-individual variability, we measured and included individual working memory capacity, processing speed, and attentional functions as cognitive covariates. After controlling for these covariates, results indicated that neither static nor animated faces improved short-term memory performance for conversational content. However, static faces reduced listening effort, whereas animated faces increased it, as indicated by secondary task RTs. Participants' subjective ratings mirrored these behavioral results. Furthermore, working memory capacity was associated with short-term memory performance, and processing speed was associated with listening effort, the latter reflected in performance on the vibrotactile secondary task. In conclusion, this study demonstrates that visual cues influence listening effort and that individual differences in working memory and processing speed help explain variability in task performance, even in optimal listening conditions.
@article{MOHANATHASAN2026106295,
title = {Beyond words: The impact of static and animated faces as visual cues on memory performance and listening effort during two-talker conversations},
journal = {Acta Psychologica},
volume = {263},
pages = {106295},
year = {2026},
issn = {0001-6918},
doi = {https://doi.org/10.1016/j.actpsy.2026.106295},
url = {https://www.sciencedirect.com/science/article/pii/S0001691826000946},
author = {Chinthusa Mohanathasan and Plamenna B. Koleva and Jonathan Ehret and Andrea Bönsch and Janina Fels and Torsten W. Kuhlen and Sabine J. Schlittmeier}
}
SPLOCIS - Extending SPLOMs to a Scatterplot Cube with Interactable Shadows for Immersive Analysis in Virtual Reality

In data analysis, scatterplots serve as an initial tool for exploring the relationships between two or three attributes. While scatterplot matrices (SPLOMs) display every attribute combination through numerous 2D scatterplots to show a concise overview of a multivariate dataset, this approach is not directly suitable for 3D scatterplots due to visual clutter. Since research has shown that immersive virtual environments can enhance data analysis compared to traditional 2D desktop setups - especially for spatial analysis tasks - we propose an interactive system, called SPLOCIS, that makes use of virtual reality to enable users to interactively filter and select 3D scatterplots from all possible attribute combinations. Our user study, combining both qualitative and quantitative results, demonstrates that SPLOCIS is a particularly novel and stimulating approach to work with multivariate data in immersive environments. It enables solving classic data exploration tasks in an efficient and accurate way, while not imposing unexpectedly high task loads. Moreover, our findings provide promising suggestions for further developments.
@INPROCEEDINGS{11457517,
author={Derksen, Melanie and Dieke, Viktoria and Kuhlen, Torsten and Botsch, Mario and Weissker, Tim},
booktitle={2026 IEEE Conference on Virtual Reality and 3D User Interfaces (VR)},
title={SPLOCIS – Extending SPLOMs to a Scatterplot Cube with Interactable Shadows for Immersive Analysis in Virtual Reality},
year={2026},
volume={},
number={},
pages={55-65},
keywords={Projectiles;Weapons;Radio broadcasting;Frequency modulation;Filtering;Filters;Feedback;Circuits;Brushes;Negative feedback;Virtual reality;3D user interfaces;Head-mounted display;Immersive analytics;Scatterplot;Scatterplot matrix},
doi={10.1109/VR67842.2026.00029}}
HYVE: Hybrid Vertex Encoder for Neural Distance Fields

Neural shape representation generally refers to representing 3D geometry using neural networks, e.g., computing a signed distance or occupancy value at a specific spatial position. In this paper we present a neural-network architecture suitable for accurate encoding of 3D shapes in a single forward pass. Our architecture is based on a multi-scale hybrid system incorporating graph-based and voxel-based components, as well as a continuously differentiable decoder. The hybrid system includes a novel way of voxelizing point-based features in neural networks by projecting the point "feature-field" onto a grid. This projection is insensitive to local point density, and we show that it can be used to obtain smoother and more detailed reconstructions, in particular when combined with oriented point clouds as input. Our architecture also requires only a single forward pass, instead of the latent-code optimization used in auto-decoder methods. Furthermore, our network is trained to solve the well-established eikonal equation and only requires knowledge of the zero-level set for training and inference. We additionally propose a modification to the aforementioned loss function for the case that surface normals are not well defined, e.g., in the context of non-watertight surfaces and non-manifold geometry. Overall, our method consistently outperforms other baselines on the surface reconstruction task across a wide variety of datasets, while being more computationally efficient and requiring fewer parameters.
@article{jeskeHYVEHybridVertex2026,
title = {{{HYVE}}: {{Hybrid Vertex Encoder}} for {{Neural Distance Fields}}},
shorttitle = {{{HYVE}}},
author = {Jeske, Stefan R. and Klein, Jonathan and Michels, Dominik and Bender, Jan},
year = 2026,
journal = {IEEE Transactions on Visualization and Computer Graphics},
doi = {10.1109/TVCG.2026.3658870},
copyright = {https://ieeexplore.ieee.org/Xplorehelp/downloads/license-information/IEEE.html}
}
Fostering Engagement through a Latency-Optimized LLM-based Dialogue System for Multimodal ECA Responses

Interactions with Embodied Conversational Agents (ECAs) are an integral part of many social Virtual Reality (VR) applications, increasing the need for free, context-sensitive conversations characterized by latency-optimized and multimodal ECA responses. Our presented methodology consists of three interdependent steps: We first present a holistic framework driven by a Large Language Model (LLM), which integrates existing technologies into a modular and extendable system that is developer-friendly and suitable for diverse use-cases. Building on this foundation, our second step comprises streaming-based optimizations that effectively reduce measured response latency, thereby facilitating real-time conversations. Finally, we conduct a comparative analysis between our latency optimized LLM-driven ECA and a conventional button-based Wizard-of-Oz (WoZ) system to evaluate performance differences in user engagement. Our insights reveal that users perceive our LLM-driven ECA as significantly more natural, competent, and trustworthy than their WoZ counterparts, despite objective measures indicating slightly higher latency in technical performance. These findings underscore the potential of LLMs to enhance engagement in ECAs within VR environments.
@INPROCEEDINGS{Kuehlem2026,
author={Kühlem, Konstantin W. and Ehret, Jonathan and Kuhlen, Torsten W. and Bönsch, Andrea},
booktitle={2026 IEEE International Conference on Artificial Intelligence and eXtended and Virtual Reality (AIxVR)},
title={{Fostering Engagement Through a Latency-Optimized LLM-Based Dialogue System for Multimodal ECA Responses}},
year={2026},
volume={},
number={},
pages={85-97},
keywords={Large language models;Buildings;Virtual reality;Oral communication;Real-time systems;Optimization;large language model;embodied conversational agents;latency;multi-modal responses;virtual reality},
doi={10.1109/AIxVR67263.2026.00019}}
Previous Year (2025)
