
Publications
DONUT: A Decoder-Only Model for Trajectory Prediction
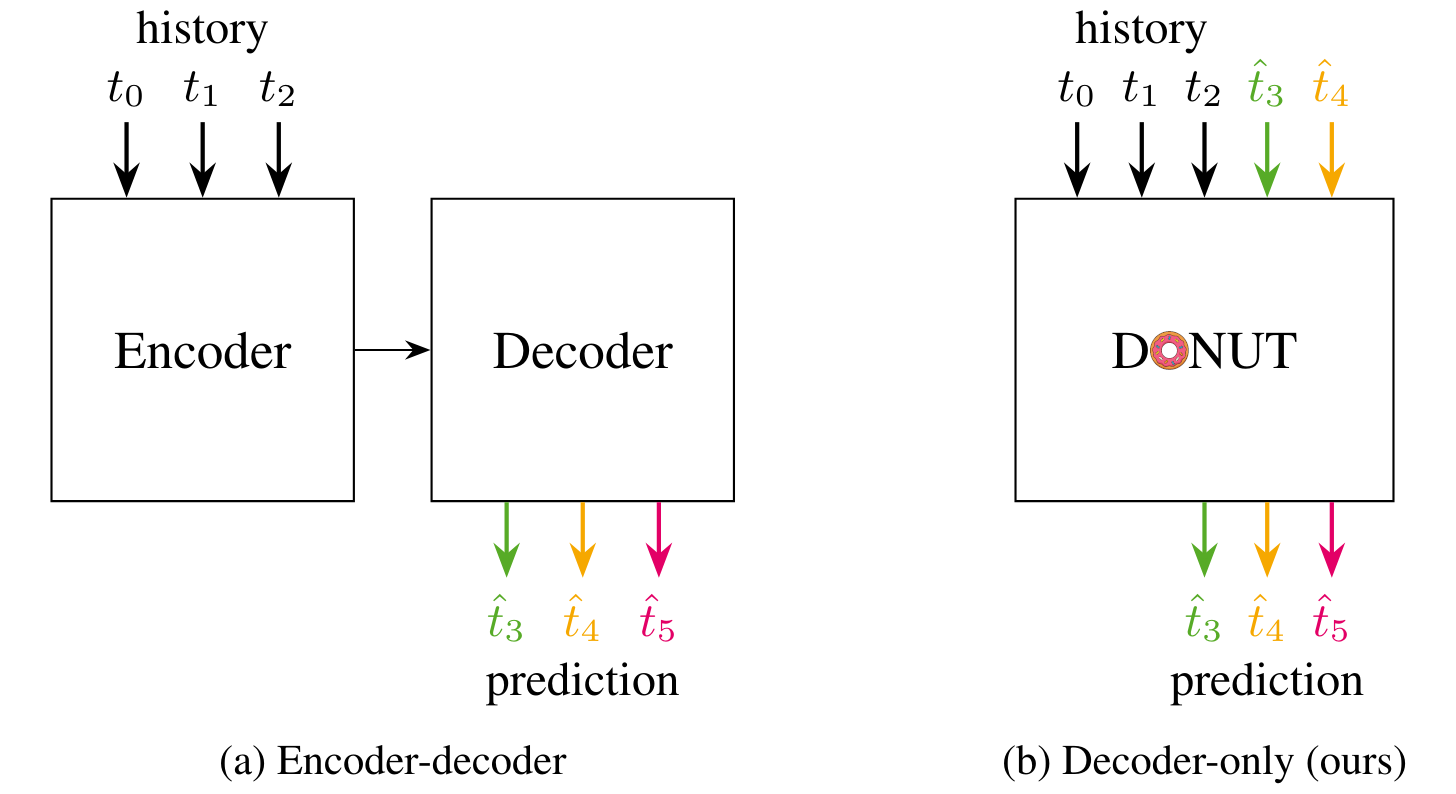
Predicting the motion of other agents in a scene is highly relevant for autonomous driving, as it allows a self-driving car to anticipate. Inspired by the success of decoder-only models for language modeling, we propose DONUT, a Decoder-Only Network for Unrolling Trajectories. Different from existing encoder-decoder forecasting models, we encode historical trajectories and predict future trajectories with a single autoregressive model. This allows the model to make iterative predictions in a consistent manner, and ensures that the model is always provided with up-to-date information, enhancing the performance. Furthermore, inspired by multi-token prediction for language modeling, we introduce an 'overprediction' strategy that gives the network the auxiliary task of predicting trajectories at longer temporal horizons. This allows the model to better anticipate the future, and further improves the performance. With experiments, we demonstrate that our decoder-only approach outperforms the encoder-decoder baseline, and achieves new state-of-the-art results on the Argoverse 2 single-agent motion forecasting benchmark.
@article{knoche2025donut,
title = {{DONUT: A Decoder-Only Model for Trajectory Prediction}},
author = {Knoche, Markus and de Geus, Daan and Leibe, Bastian},
journal = {arXiv preprint arXiv:2506.06854},
year = {2025}
}
Fine-Tuning Image-Conditional Diffusion Models is Easier than You Think
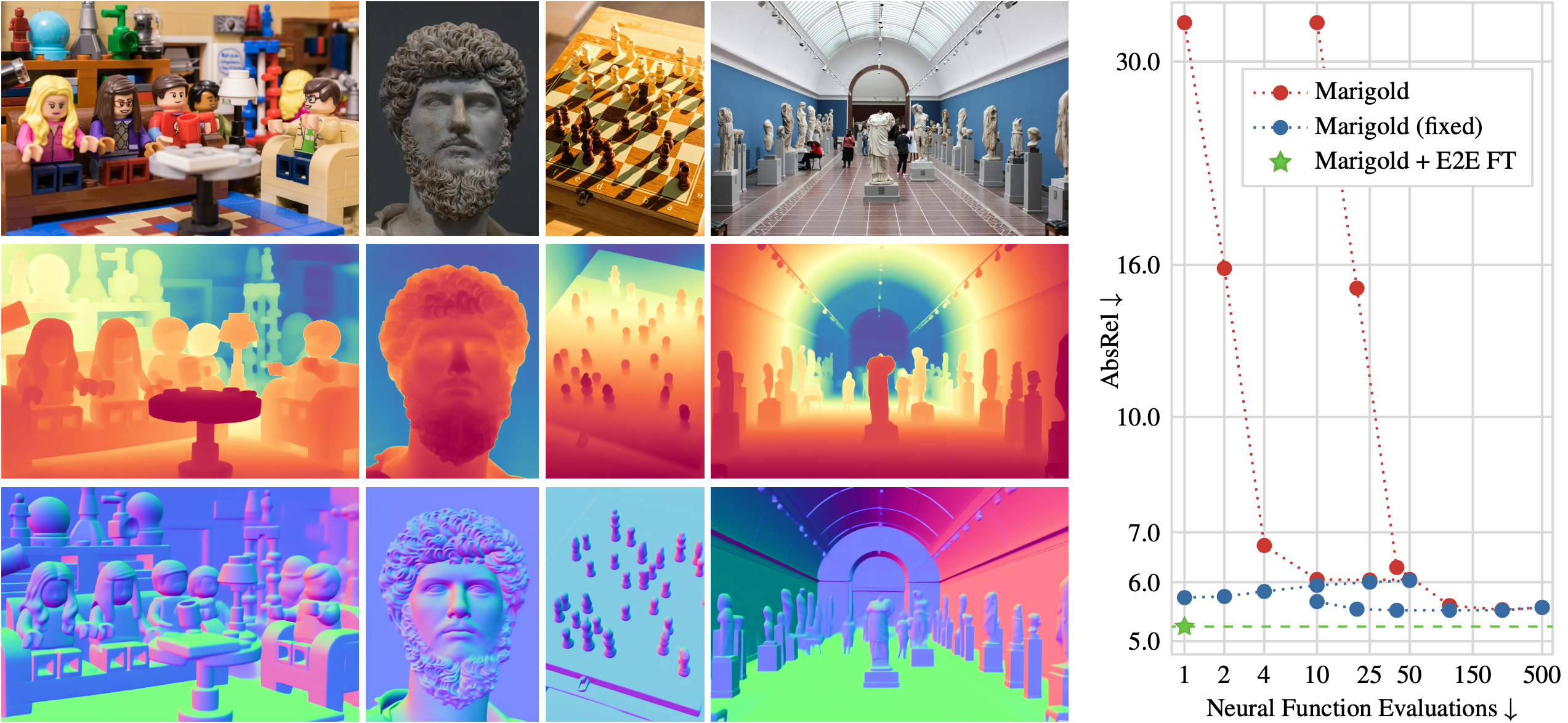
Recent work showed that large diffusion models can be reused as highly precise monocular depth estimators by casting depth estimation as an image-conditional image generation task. While the proposed model achieved state-of-the-art results, high computational demands due to multi-step inference limited its use in many scenarios. In this paper, we show that the perceived inefficiency was caused by a flaw in the inference pipeline that has so far gone unnoticed. The fixed model performs comparably to the best previously reported configuration while being more than 200x faster. To optimize for downstream task performance, we perform end-to-end fine-tuning on top of the single-step model with task-specific losses and get a deterministic model that outperforms all other diffusion-based depth and normal estimation models on common zero-shot benchmarks. We surprisingly find that this fine-tuning protocol also works directly on Stable Diffusion and achieves comparable performance to current state-of-the-art diffusion-based depth and normal estimation models, calling into question some of the conclusions drawn from prior works.
@article{martingarcia2024diffusione2eft,
title = {Fine-Tuning Image-Conditional Diffusion Models is Easier than You Think},
author = {Martin Garcia, Gonzalo and Abou Zeid, Karim and Schmidt, Christian and de Geus, Daan and Hermans, Alexander and Leibe, Bastian},
journal = {arXiv preprint arXiv:2409.11355},
year = {2024}
}
Interactive4D: Interactive 4D LiDAR Segmentation
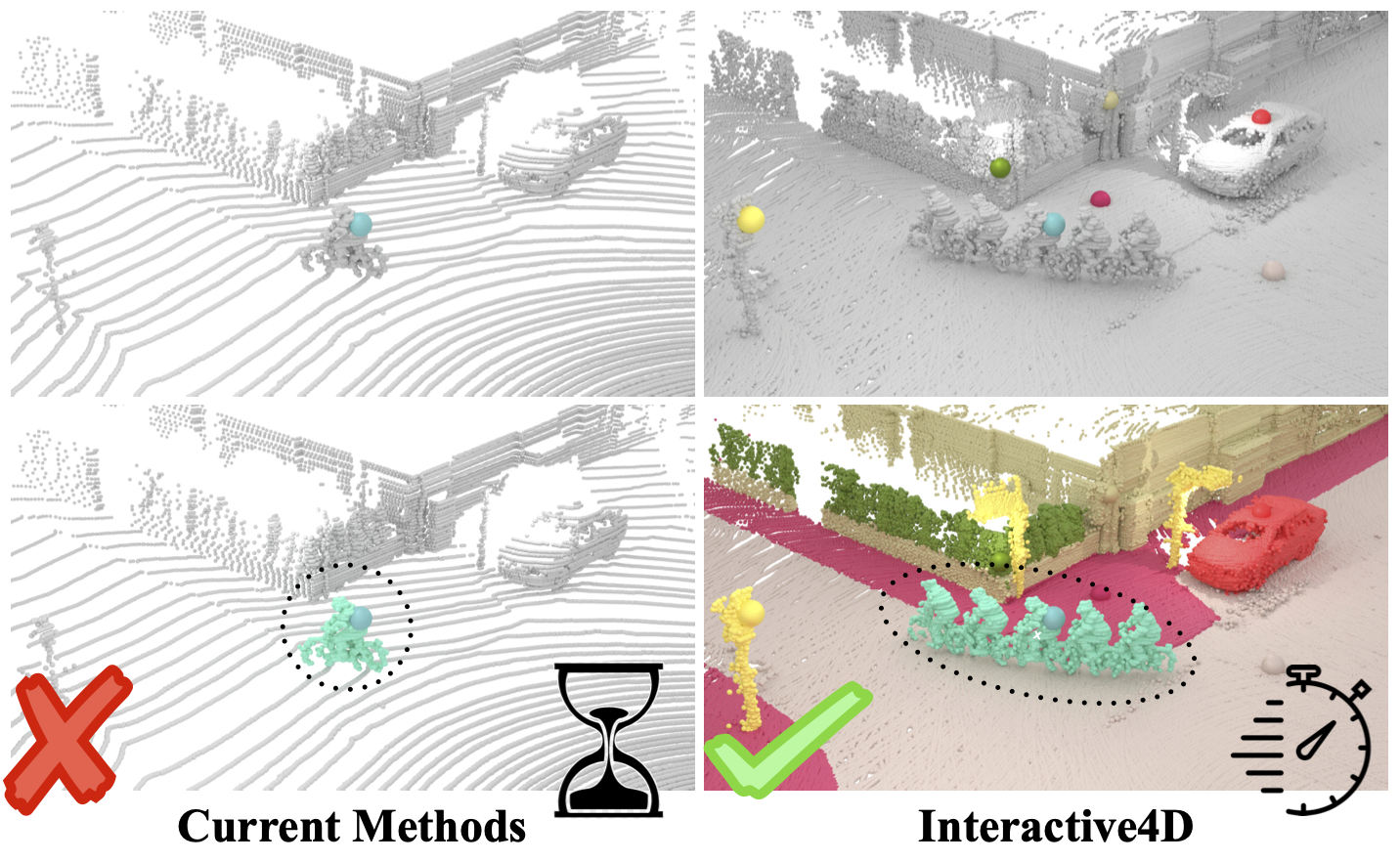
Interactive segmentation has an important role in facilitating the annotation process of future LiDAR datasets. Existing approaches sequentially segment individual objects at each LiDAR scan, repeating the process throughout the entire sequence, which is redundant and ineffective. In this work, we propose interactive 4D segmentation, a new paradigm that allows segmenting multiple objects on multiple LiDAR scans simultaneously, and Interactive4D, the first interactive 4D segmentation model that segments multiple objects on superimposed consecutive LiDAR scans in a single iteration by utilizing the sequential nature of LiDAR data. While performing interactive segmentation, our model leverages the entire space-time volume, leading to more efficient segmentation. Operating on the 4D volume, it directly provides consistent instance IDs over time and also simplifies tracking annotations. Moreover, we show that click simulations are crucial for successful model training on LiDAR point clouds. To this end, we design a click simulation strategy that is better suited for the characteristics of LiDAR data. To demonstrate its accuracy and effectiveness, we evaluate Interactive4D on multiple LiDAR datasets, where Interactive4D achieves a new state-of-the-art by a large margin.
@article{fradlin2024interactive4d,
title = {{Interactive4D: Interactive 4D LiDAR Segmentation}},
author = {Fradlin, Ilya and Zulfikar, Idil Esen and Yilmaz, Kadir and Kontogianni, Thodora and Leibe, Bastian},
journal = {arXiv preprint arXiv:2410.08206},
year = {2024}
}
Adaptive Phase-Field-FLIP for Very Large Scale Two-Phase Fluid Simulation

Capturing the visually compelling features of large-scale water phenomena,such as the spray clouds of crashing waves, stormy seas, or waterfalls, involves simulating not only the water but also the motion of the air interacting with it. However, current solutions in the visual effects industry still largely rely on single-phase solvers and non-physical “white-water” heuristics. To address these limitations, we present Phase-Field-FLIP (PF-FLIP), a hybrid Eulerian/Lagrangian method for the fully physics-based simulation of very large-scale, highly turbulent multiphase flows at high Reynolds numbers and high fluid density contrasts. PF-FLIP transports mass and momentum in a consistent, non-dissipative manner and, unlike most existing multiphase approaches, does not require a surface reconstruction step. Furthermore, we employ spatial adaptivity across all critical components of the simulation algorithm, including the pressure Poisson solver. We augment PF-FLIP with a dual multiresolution scheme that couples an efficient treeless adaptive grid with adaptive particles, along with a fast adaptive Poisson solver tailored for high-density-contrast multiphase flows. Our method enables the simulation of two-phase flow scenarios with a level of physical realism and detail previously unattainable in graphics, supporting billions of particles and adaptive 3D resolutions with thousands of grid cells per dimension on a single workstation.
Multiphysics Simulation Methods in Computer Graphics

Physics simulation is a cornerstone of many computer graphics applications, ranging from video games and virtual reality to visual effects and computational design. The number of techniques for physically-based modeling and animation has thus skyrocketed over the past few decades, facilitating the simulation of a wide variety of materials and physical phenomena. This report captures the state-of-the-art of multiphysics simulation for computer graphics applications. Although a lot of work has focused on simulating individual phenomena, here we put an emphasis on methods developed by the computer graphics community for simulating various physical phenomena and materials, as well as the interactions between them. These include combinations of discretization schemes, mathematical modeling frameworks, and coupling techniques. For the most commonly used methods we provide an overview of the state-of-the-art and deliver valuable insights into the various approaches. A selection of software frameworks that offer out-of-the-box multiphysics modeling capabilities is also presented. Finally, we touch on emerging trends in physics-based animation that affect multiphysics simulation, including machine learning-based methods which have become increasingly popular in recent years.
@article{HJL*25,
journal = {Computer Graphics Forum},
title = {{Multiphysics Simulation Methods in Computer Graphics}},
author = {Holz, Daniel and Jeske, Stefan Rhys and L\"oschner, Fabian and Bender, Jan and Yang, Yin and Andrews, Sheldon},
year = {2025},
publisher = {The Eurographics Association and John Wiley & Sons Ltd.},
ISSN = {1467-8659},
DOI = {10.1111/cgf.70082},
volume = {44},
number = {2}
}
Exact and Efficient Mesh-Kernel Generation

The mesh kernel for a star-shaped mesh is a convex polyhedron given by the intersection of all half-spaces defined by the faces of the input mesh. For all non-star-shaped meshes, the kernel is empty. We present a method to robustly and efficiently compute the kernel of an input triangle mesh by using exact plane-based integer arithmetic to compute the mesh kernel. We make use of several ways to accelerate the computation time. Since many applications just require information if a non-empty mesh kernel exists, we also propose a method to efficiently determine whether a kernel exists by developing an exact plane-based linear program solver. We evaluate our method on a large dataset of triangle meshes and show that in contrast to previous methods, our approach is exact and robust while maintaining a high performance. It is on average two orders of magnitude faster than other exact state-of-the-art methods and often about one order of magnitude faster than non-exact methods.
@article{nehring-wirxel2025mesh_kernel,
title={Exact and Efficient Mesh-Kernel Generation},
author={Nehring-Wirxel, Julius and Kern, Paul and Trettner, Philip and Kobbelt, Leif},
year={2025},
journal={Computer Graphics Forum},
volume={44},
number={5},
}
A Smoothed Particle Hydrodynamics framework for fluid simulation in robotics

Simulation is a core component of robotics workflows that can shed light on the complex interplay between a physical body, the environment and sensory feedback mechanisms in silico. To this goal several simulation methods, originating in rigid body dynamics and in continuum mechanics have been employed, enabling the simulation of a plethora of phenomena such as rigid/soft body dynamics, fluid dynamics, muscle simulation as well as sensor and actuator dynamics. The physics engines commonly employed in robotics simulation focus on rigid body dynamics, whereas continuum mechanics methods excel on the simulation of phenomena where deformation plays a crucial role, keeping the two fields relatively separate. Here, we propose a shift of paradigm that allows for the accurate simulation of fluids in interaction with rigid bodies within the same robotics simulation framework, based on the continuum mechanics-based Smoothed Particle Hydrodynamics method. The proposed framework is useful for simulations such as swimming robots with complex geometries, robots manipulating fluids and even robots emitting highly viscous materials such as the ones used for 3D printing. Scenarios like swimming on the surface, air-water transitions, locomotion on granular media can be natively simulated within the proposed framework. Firstly, we present the overall architecture of our framework and give examples of a concrete software implementation. We then verify our approach by presenting one of the first of its kind simulation of self-propelled swimming robots with a smooth particle hydrodynamics method and compare our simulations with real experiments. Finally, we propose a new category of simulations that would benefit from this approach and discuss ways that the sim-to-real gap could be further reduced.
@article{AAB+24,
title = {A smoothed particle hydrodynamics framework for fluid simulation in robotics},
journal = {Robotics and Autonomous Systems},
volume = {185},
year = {2025},
issn = {0921-8890},
doi = {https://doi.org/10.1016/j.robot.2024.104885},
url = {https://www.sciencedirect.com/science/article/pii/S0921889024002690},
author = {Emmanouil Angelidis and Jonathan Arreguit and Jan Bender and Patrick Berggold and Ziyuan Liu and Alois Knoll and Alessandro Crespi and Auke J. Ijspeert}
}
DaVE - A Curated Database of Visualization Examples

While mobile devices have developed into hardware with advanced capabilities for rendering 3D gra-phics, they commonly lack the computational power to render large 3D scenes with complex lighting interactively. A prominent approach to tackle this is rendering required views on a remote server and streaming them to the mobile client. However, the rate at which servers can supply data is limited, e.g., by the available network speed, requiring image-based rendering techniques like image warping to compensate for the latency and allow a smooth user experience, especially in scenes where rapid user movement is essential. In this paper, we present a novel streaming approach designed to minimize arti-facts during the warping process by including an additional visibility layer that keeps track of occluded surfaces while allowing access to 360° views. In addition, we propose a novel mesh generation techni-que based on the detection of loops to reliably create a mesh that encodes the depth information requi-red for the image warping process. We demonstrate our approach in a number of complex scenes and compare it against existing works using two layers and one layer alone. The results indicate a significant reduction in computation time while achieving comparable or even better visual results when using our dual-layer approach.
Towards Comprehensible and Expressive Teleportation Techniques in Immersive Virtual Environments

Teleportation, a popular navigation technique in virtual environments, is favored for its efficiency and reduction of cybersickness but presents challenges such as reduced spatial awareness and limited navigational freedom compared to continuous techniques. I would like to focus on three aspects that advance our understanding of teleportation in both the spatial and the temporal domain. 1) An assessment of different parametrizations of common mathematical models used to specify the target location of the teleportation and the influence on teleportation distance and accuracy. 2) Extending teleportation capabilities to improve navigational freedom, comprehensibility, and accuracy. 3) Adapt teleportation to the time domain, mediating temporal disorientation. The results will enhance the expressivity of existing teleportation interfaces and provide validated alternatives to their steering-based counterparts.
Exploring Gaze Dynamics: Initial Findings on the Role of Listening Bystanders in Conversational Interactions

This work-in-progress paper investigates how virtual listening bystanders influence participants’ gaze behavior and their perception of turn-taking during scripted conversations with embodied conversational agents (ECAs). 25 participants interacted with five ECAs – two speakers and three bystanders – across three conditions: no bystanders, bystanders exhibiting random gazing behavior, and social bystanders engaging in mutual gaze and backchanneling. Participants either observed the conversation or actively participated as speakers by reciting prompted sentences. The results indicated that bystanders reduced the participants’ attention to speakers, hindering their ability to anticipate turn changes and resulting in longer delays in shifting their gaze to the new speaker after an ECA yielded the turn. Random gazing bystanders were particularly noted for obscuring conversational flow. These findings underscore the challenges of designing effective and natural conversational environments, highlighting the need for careful consideration of ECA behaviors to enhance user engagement.
@INPROCEEDINGS{Ehret2025,
author={Ehret, Jonathan and Dasbach, Valentin and Hartmann, Jan-Nikjas and
Fels, Janina and Kuhlen, Torsten W. and Bönsch, Andrea},
booktitle={2025 IEEE Conference on Virtual Reality and 3D User Interfaces
Abstracts and Workshops (VRW)},
title={Exploring Gaze Dynamics: Initial Findings on the Role of Listening
Bystanders in Conversational Interactions},
year={2025},
volume={},
number={},
pages={748-752},
doi={10.1109/VRW66409.2025.00151}}
Front Matter: 9th Edition of IEEE VR Workshop: Virtual Humans and Crowds in Immersive Environments (VHCIE)

The VHCIE workshop aims to explore and advance the creation of believable virtual humans and crowds within immersive virtual environments (IVEs). With the emergence of various tools, algorithms, and systems, it is now possible to design realistic virtual characters - known as virtual agents (VAs) - that can populate expansive environments with thousands of individuals. These sophisticated crowd simulations facilitate dynamic interactions among the VAs themselves and between VAs and virtual reality (VR) users. The VHCIE workshop seeks to highlight the diverse range of VR applications for these advancements, including virtual tour guides, platforms for professional training, studies on human behavior, and even recreations of live events like concerts. By fostering discussions around these themes, VHCIE aims to inspire innovative approaches and collaborative efforts that push the boundaries of what is possible in social IVEs while also providing an open place for networking and exchanging ideas among participants. Bild: Bitte das VHCIE Logo im Anhang nutzen und klein rechts in die Ecke packen
@INPROCEEDINGS{Boensch2025,
author={Bönsch, Andrea and Chollet, Mathieu and Martin, Jordan and
Olivier, Anne-Hélène and Pettré, Julien},
booktitle={2025 IEEE Conference on Virtual Reality and 3D User Interfaces
Abstracts and Workshops (VRW)},
title={9th Edition of IEEE VR Workshop: Virtual Humans and Crowds in
Immersive Environments (VHCIE)},
year={2025},
volume={},
number={},
pages={703-704},
doi={10.1109/VRW66409.2025.00142}
}
Geschichte(n) in Virtual Reality - Perspektiven der Informatik

Den Bau der Pyramiden von Gizeh beobachten – und dann gleich weiter ins antike Rom? Das und mehr soll mit Virtual Reality möglich werden. Doch was macht das mit unserem Verständnis von Geschichte?
Virtual-Reality-Anwendungen mit historischem Inhalt haben Konjunktur. Sie versprechen virtuelle Zeitreisen und die Möglichkeit, endlich zeigen zu können, wie die Vergangenheit wirklich war. Daraus resultieren Formen des Umgangs mit Geschichte, die nicht nur die außerschulische Geschichtskultur und -vermittlung prägen, sondern auch zunehmend in den Geschichtsunterricht hineinwirken. Im Zentrum dieses Bandes steht daher die Frage: Was macht Virtual Reality mit Geschichte? Während aus Sicht der Informatik historische Inhalte »nur« besondere Gestaltungskriterien mit sich bringen, sieht sich die Geschichtswissenschaft mit einer Konkurrenz im Bereich der Geschichtsdarstellung konfrontiert, die womöglich sogar droht, diese obsolet zu machen. Museen und Gedenkstätten sehen sich mit der Aufgabe konfrontiert, VR-Anwendungen in ihr Angebot einzubinden und trotzdem – oder gerade damit – Besuchende für ihre Institutionen zu gewinnen. Die Geschichtsdidaktik diskutiert vor diesem Hintergrund die Folgen virtueller Darstellungen innerhalb und außerhalb des Unterrichts auf historische Lernprozesse. Zu Wort kommen Expert:innen aus den genannten Fachbereichen, um ihre Perspektive auf die Frage darzulegen: Ist Virtual Reality die Zukunft der historischen Bildung?
Front Matter: The Third Workshop on Locomotion and Wayfinding in XR (LocXR)
The Third Workshop on Locomotion and Wayfinding in XR, held in conjunction with IEEE VR 2025 in Saint-Malo, France, is dedicated to advancing research and fostering discussions around the critical topics of navigation in extended reality (XR). Navigation is a fundamental form of user interaction in XR, yet it poses numerous challenges in conceptual design, technical implementation, and systematic evaluation. By bringing together researchers and practitioners, this workshop aims to address these challenges and push the boundaries of what is achievable in XR navigation.
@inproceedings{Weissker2025,
author={T. {Weissker} and D. {Zielasko}},
booktitle={2025 IEEE Conference on Virtual Reality and 3D User Interfaces Abstracts and Workshops (VRW)},
title={The Third Workshop on Locomotion and Wayfinding in XR (LocXR)},
year={2025},
volume={},
number={},
pages={239-240},
doi={10.1109/VRW66409.2025.00058}
}
PASCAL - A Collaboration Technique Between Non-Collocated Avatars in Large Collaborative Virtual Environments

Collaborative work in large virtual environments often requires transitions from loosely-coupled collaboration at different locations to tightly-coupled collaboration at a common meeting point. Inspired by prior work on the continuum between these extremes, we present two novel interaction techniques designed to share spatial context while collaborating over large virtual distances. The first method replicates the familiar setup of a video conference by providing users with a virtual tablet to share video feeds with their peers. The second method called PASCAL (Parallel Avatars in a Shared Collaborative Aura Link) enables users to share their immediate spatial surroundings with others by creating synchronized copies of it at the remote locations of their collaborators. We evaluated both techniques in a within-subject user study, in which 24 participants were tasked with solving a puzzle in groups of two. Our results indicate that the additional contextual information provided by PASCAL had significantly positive effects on task completion time, ease of communication, mutual understanding, and co-presence. As a result, our insights contribute to the repertoire of successful interaction techniques to mediate between loosely- and tightly-coupled work in collaborative virtual environments.
@article{Gilbert2025,
author={D. {Gilbert} and A. {Bose} and T. {Kuhlen} and T. {Weissker}},
journal={IEEE Transactions on Visualization and Computer Graphics},
title={PASCAL - A Collaboration Technique Between Non-Collocated Avatars in Large Collaborative Virtual Environments},
year={2025},
volume={31},
number={5},
pages={1268-1278},
doi={10.1109/TVCG.2025.3549175}
}
Minimalism or Creative Chaos? On the Arrangement and Analysis of Numerous Scatterplots in Immersi-ve 3D Knowledge Spaces

Working with scatterplots is a classic everyday task for data analysts, which gets increasingly complex the more plots are required to form an understanding of the underlying data. To help analysts retrieve relevant plots more quickly when they are needed, immersive virtual environments (iVEs) provide them with the option to freely arrange scatterplots in the 3D space around them. In this paper, we investigate the impact of different virtual environments on the users' ability to quickly find and retrieve individual scatterplots from a larger collection. We tested three different scenarios, all having in common that users were able to position the plots freely in space according to their own needs, but each providing them with varying numbers of landmarks serving as visual cues - an Emptycene as a baseline condition, a single landmark condition with one prominent visual cue being a Desk, and a multiple landmarks condition being a virtual Office. Results from a between-subject investigation with 45 participants indicate that the time and effort users invest in arranging their plots within an iVE had a greater impact on memory performance than the design of the iVE itself. We report on the individual arrangement strategies that participants used to solve the task effectively and underline the importance of an active arrangement phase for supporting the spatial memorization of scatterplots in iVEs.
@article{Derksen2025,
author={M. {Derksen} and T. {Kuhlen} and M. {Botsch} and T. {Weissker}},
journal={IEEE Transactions on Visualization and Computer Graphics},
title={Minimalism or Creative Chaos? On the Arrangement and Analysis of Numerous Scatterplots in Immersive 3D Knowledge Spaces},
year={2025},
volume={31},
number={5},
pages={746-756},
doi={10.1109/TVCG.2025.3549546}
}
OCCUQ: Efficient Uncertainty Quantification for 3D Occupancy Prediction
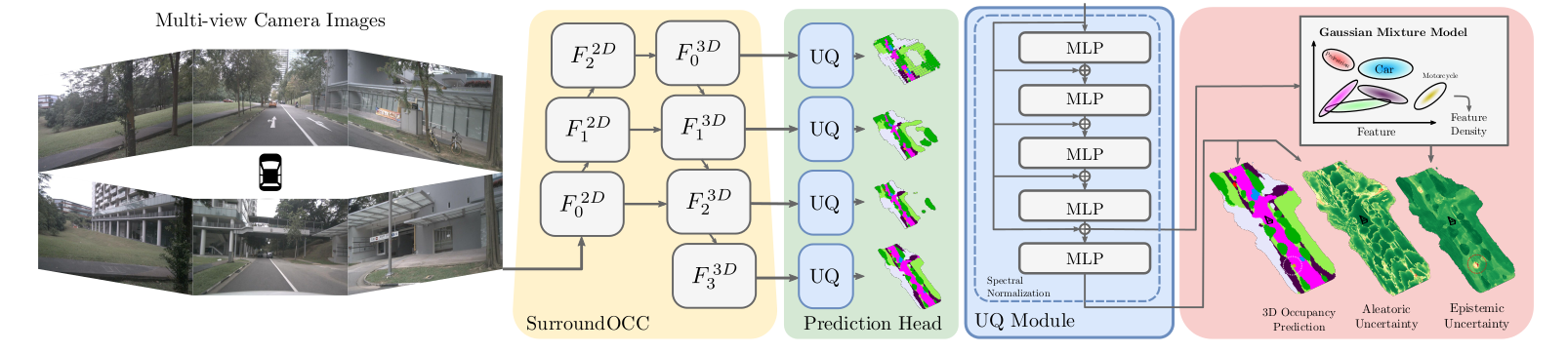
Autonomous driving has the potential to significantly enhance productivity and provide numerous societal benefits. Ensuring robustness in these safety-critical systems is essential, particularly when vehicles must navigate adverse weather conditions and sensor corruptions that may not have been encountered during training. Current methods often overlook uncertainties arising from adversarial conditions or distributional shifts, limiting their real-world applicability. We propose an efficient adaptation of an uncertainty estimation technique for 3D occupancy prediction. Our method dynamically calibrates model confidence using epistemic uncertainty estimates. Our evaluation under various camera corruption scenarios, such as fog or missing cameras, demonstrates that our approach effectively quantifies epistemic uncertainty by assigning higher uncertainty values to unseen data. We introduce region-specific corruptions to simulate defects affecting only a single camera and validate our findings through both scene-level and region-level assessments. Our results show superior performance in Out-of-Distribution (OoD) detection and confidence calibration compared to common baselines such as Deep Ensembles and MC-Dropout. Our approach consistently demonstrates reliable uncertainty measures, indicating its potential for enhancing the robustness of autonomous driving systems in real-world scenarios.
@inproceedings{heidrich2025occuq,
title={{OCCUQ: Exploring Efficient Uncertainty Quantification for 3D Occupancy Prediction}},
author={Heidrich, Severin and Beemelmanns, Till and Nekrasov, Alexey and Leibe, Bastian and Eckstein, Lutz},
booktitle="International Conference on Robotics and Automation (ICRA)",
year={2025}
}
Spotting the Unexpected (STU): A 3D LiDAR Dataset for Anomaly Segmentation in Autonomous Driving
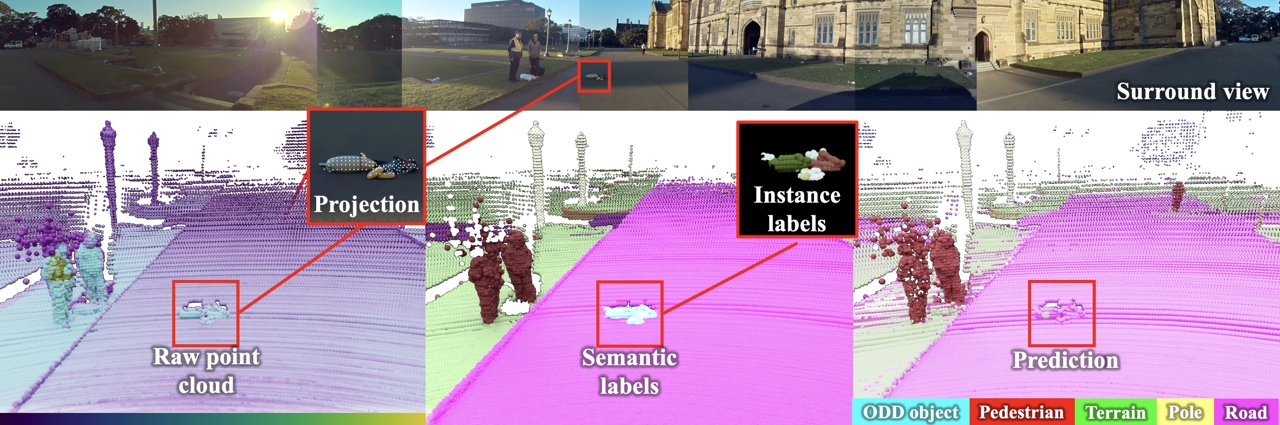
To operate safely, autonomous vehicles (AVs) need to detect and handle unexpected objects or anomalies on the road. While significant research exists for anomaly detection and segmentation in 2D, research progress in 3D is underexplored. Existing datasets lack high-quality multimodal data that are typically found in AVs. This paper presents a novel dataset for anomaly segmentation in driving scenarios. To the best of our knowledge, it is the first publicly available dataset focused on road anomaly segmentation with dense 3D semantic labeling, incorporating both LiDAR and camera data, as well as sequential information to enable anomaly detection across various ranges. This capability is critical for the safe navigation of autonomous vehicles. We adapted and evaluated several baseline models for 3D segmentation, highlighting the challenges of 3D anomaly detection in driving environments. Our dataset and evaluation code will be openly available, facilitating the testing and performance comparison of different approaches.
@inproceedings{nekrasov2025stu,
title = {{Spotting the Unexpected (STU): A 3D LiDAR Dataset for Anomaly Segmentation in Autonomous Driving}},
author = {Nekrasov, Alexey and Burdorf, Malcolm and Worrall, Stewart and Leibe, Bastian and Julie Stephany Berrio Perez},
booktitle = {{"Conference on Computer Vision and Pattern Recognition (CVPR)"}},
year = {2025}
}
Systematic Evaluation of Different Projection Methods for Monocular 3D Human Pose Estimation on Heavily Distorted Fisheye Images
Authors: Stephanie Käs, Sven Peter, Henrik Thillmann, Anton Burenko, Timm Linder, David Adrian, and Dennis Mack, Bastian Leibe
In this work, we tackle the challenge of 3D human pose estimation in fisheye images, which is crucial for applications in robotics, human-robot interaction, and automotive perception. Fisheye cameras offer a wider field of view, but their distortions make pose estimation difficult. We systematically analyze how different camera models impact prediction accuracy and introduce a strategy to improve pose estimation across diverse viewing conditions.
A key contribution of our work is FISHnCHIPS, a novel dataset featuring 3D human skeleton annotations in fisheye images, including extreme close-ups, ground-mounted cameras, and wide-FOV human poses. To support future research, we will be publicly releasing this dataset.
More details coming soon — stay tuned for the final publication! Looking forward to sharing our findings at ICRA 2025!
OoDIS: Anomaly Instance Segmentation Benchmark

Autonomous vehicles require a precise understanding of their environment to navigate safely. Reliable identification of unknown objects, especially those that are absent during training, such as wild animals, is critical due to their potential to cause serious accidents. Significant progress in semantic segmentation of anomalies has been driven by the availability of out-of-distribution (OOD) benchmarks. However, a comprehensive understanding of scene dynamics requires the segmentation of individual objects, and thus the segmentation of instances is essential. Development in this area has been lagging, largely due to the lack of dedicated benchmarks. To address this gap, we have extended the most commonly used anomaly segmentation benchmarks to include the instance segmentation task. Our evaluation of anomaly instance segmentation methods shows that this challenge remains an unsolved problem. The benchmark website and the competition page can be found at: https://vision.rwth-aachen.de/oodis
@article{nekrasov2024oodis,
title={{OoDIS: Anomaly Instance Segmentation Benchmark}},
author={Nekrasov, Alexey and Zhou, Rui and Ackermann, Miriam and Hermans, Alexander and Leibe, Bastian and Rottmann, Matthias},
journal={ICRA},
year={2025}
}
Previous Year (2024)
