
Publications
DynaMITe: Dynamic Query Bootstrapping for Multi-object Interactive Segmentation Transformer
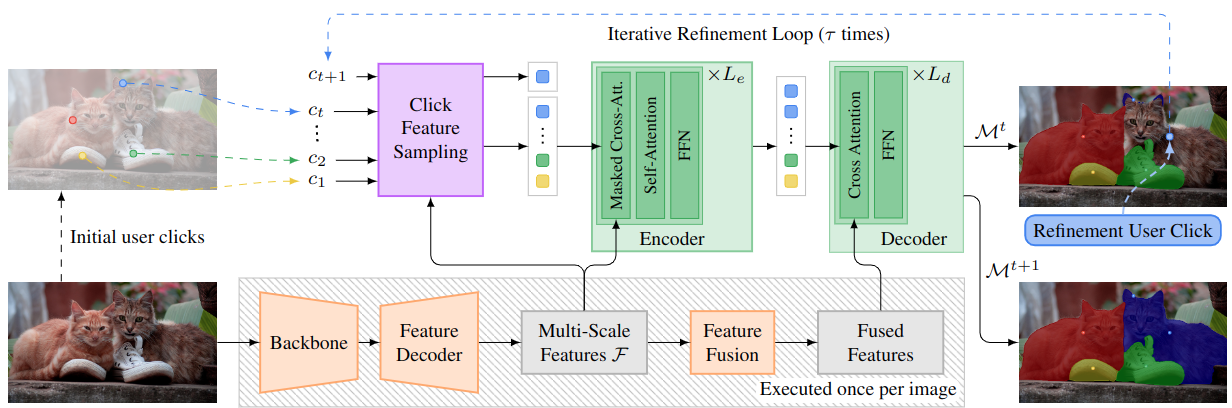
Most state-of-the-art instance segmentation methods rely on large amounts of pixel-precise ground-truth annotations for training, which are expensive to create. Interactive segmentation networks help generate such annotations based on an image and the corresponding user interactions such as clicks. Existing methods for this task can only process a single instance at a time and each user interaction requires a full forward pass through the entire deep network. We introduce a more efficient approach, called DynaMITe, in which we represent user interactions as spatio-temporal queries to a Transformer decoder with a potential to segment multiple object instances in a single iteration. Our architecture also alleviates any need to re-compute image features during refinement, and requires fewer interactions for segmenting multiple instances in a single image when compared to other methods. DynaMITe achieves state-of-the-art results on multiple existing interactive segmentation benchmarks, and also on the new multi-instance benchmark that we propose in this paper.
@article{RanaMahadevan23arxiv,
title={DynaMITe: Dynamic Query Bootstrapping for Multi-object Interactive Segmentation Transformer},
author={Rana, Amit and Mahadevan, Sabarinath and Alexander Hermans and Leibe, Bastian},
journal={arXiv preprint arXiv:2304.06668},
year={2023}
}
TarVis: A Unified Approach for Target-based Video Segmentation
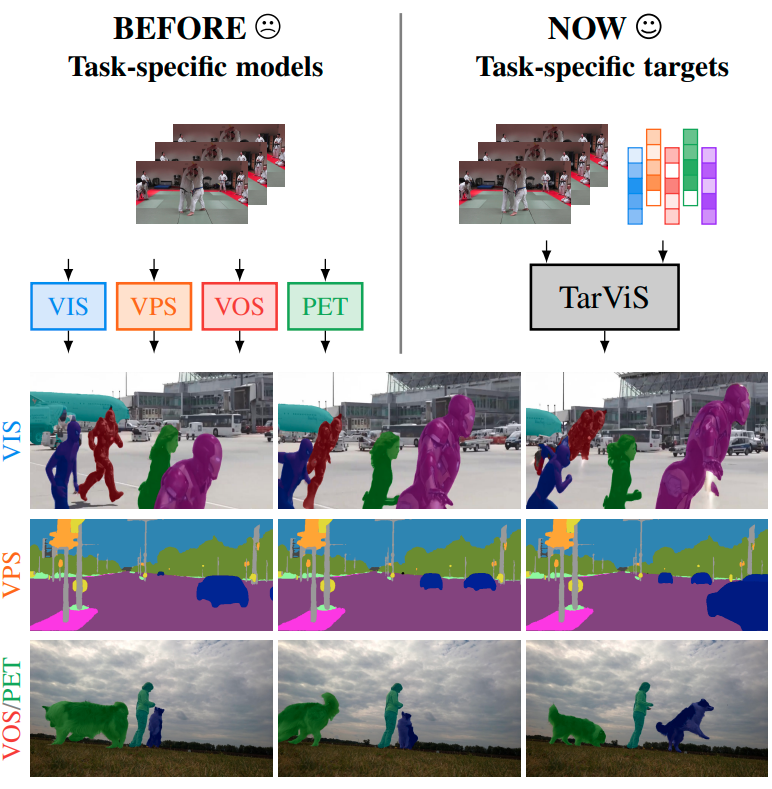
The general domain of video segmentation is currently fragmented into different tasks spanning multiple benchmarks. Despite rapid progress in the state-of-the-art, current methods are overwhelmingly task-specific and cannot conceptually generalize to other tasks. Inspired by recent approaches with multi-task capability, we propose TarViS: a novel, unified network architecture that can be applied to any task that requires segmenting a set of arbitrarily defined 'targets' in video. Our approach is flexible with respect to how tasks define these targets, since it models the latter as abstract 'queries' which are then used to predict pixel-precise target masks. A single TarViS model can be trained jointly on a collection of datasets spanning different tasks, and can hot-swap between tasks during inference without any task-specific retraining. To demonstrate its effectiveness, we apply TarViS to four different tasks, namely Video Instance Segmentation (VIS), Video Panoptic Segmentation (VPS), Video Object Segmentation (VOS) and Point Exemplar-guided Tracking (PET). Our unified, jointly trained model achieves state-of-the-art performance on 5/7 benchmarks spanning these four tasks, and competitive performance on the remaining two.
@inproceedings{athar2023tarvis,
title={TarViS: A Unified Architecture for Target-based Video Segmentation},
author={Athar, Ali and Hermans, Alexander and Luiten, Jonathon and Ramanan, Deva and Leibe, Bastian},
booktitle={CVPR},
year={2023}
}
3D Segmentation of Humans in Point Clouds with Synthetic Data
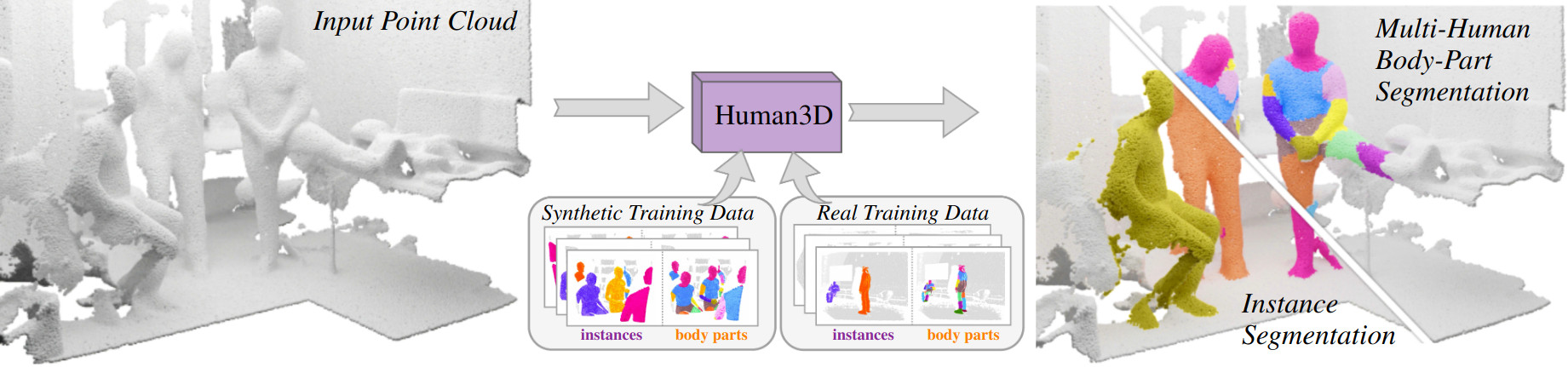
Segmenting humans in 3D indoor scenes has become increasingly important with the rise of human-centered robotics and AR/VR applications. In this direction, we explore the tasks of 3D human semantic-, instance- and multi-human body-part segmentation. Few works have attempted to directly segment humans in point clouds (or depth maps), which is largely due to the lack of training data on humans interacting with 3D scenes. We address this challenge and propose a framework for synthesizing virtual humans in realistic 3D scenes. Synthetic point cloud data is attractive since the domain gap between real and synthetic depth is small compared to images. Our analysis of different training schemes using a combination of synthetic and realistic data shows that synthetic data for pre-training improves performance in a wide variety of segmentation tasks and models. We further propose the first end-to-end model for 3D multi-human body-part segmentation, called Human3D, that performs all the above segmentation tasks in a unified manner. Remarkably, Human3D even outperforms previous task-specific state-of-the-art methods. Finally, we manually annotate humans in test scenes from EgoBody to compare the proposed training schemes and segmentation models.
@article{Takmaz23,
title = {{3D Segmentation of Humans in Point Clouds with Synthetic Data}},
author = {Takmaz, Ay\c{c}a and Schult, Jonas and Kaftan, Irem and Ak\c{c}ay, Mertcan
and Leibe, Bastian and Sumner, Robert and Engelmann, Francis and Tang, Siyu},
booktitle = {{International Conference on Computer Vision (ICCV)}},
year = {2023}
}
Implicit Surface Tension for SPH Fluid Simulation

The numerical simulation of surface tension is an active area of research in many different fields of application and has been attempted using a wide range of methods. Our contribution is the derivation and implementation of an implicit cohesion force based approach for the simulation of surface tension effects using the Smoothed Particle Hydrodynamics (SPH) method. We define a continuous formulation inspired by the properties of surface tension at the molecular scale which is spatially discretized using SPH. An adapted variant of the linearized backward Euler method is used for time discretization, which we also strongly couple with an implicit viscosity model. Finally, we extend our formulation with adhesion forces for interfaces with rigid objects.
Existing SPH approaches for surface tension in computer graphics are mostly based on explicit time integration, thereby lacking in stability for challenging settings. We compare our implicit surface tension method to these approaches and further evaluate our model on a wider variety of complex scenarios, showcasing its efficacy and versatility. Among others, these include but are not limited to simulations of a water crown, a dripping faucet and a droplet-toy.
@article{Jeske2023,
title = {Implicit {{Surface Tension}} for {{SPH Fluid Simulation}}},
author = {Jeske, Stefan Rhys and Westhofen, Lukas and L{\"o}schner, Fabian and {Fern{\'a}ndez-Fern{\'a}ndez}, Jos{\'e} Antonio and Bender, Jan},
year = {2023},
month = nov,
journal = {ACM Transactions on Graphics},
volume = {43},
number = {1},
issn = {0730-0301},
doi = {10.1145/3631936},
urldate = {2023-11-07},
keywords = {adhesion,cohesion,fluid simulation,smoothed particle hydrodynamics,surface tension},
}
BURST: A Benchmark for Unifying Object Recognition, Segmentation and Tracking in Video

Multiple existing benchmarks involve tracking and segmenting objects in video e.g., Video Object Segmentation (VOS) and Multi-Object Tracking and Segmentation (MOTS), but there is little interaction between them due to the use of disparate benchmark datasets and metrics (e.g. J&F, mAP, sMOTSA). As a result, published works usually target a particular benchmark, and are not easily comparable to each another. We believe that the development of generalized methods that can tackle multiple tasks requires greater cohesion among these research sub-communities. In this paper, we aim to facilitate this by proposing BURST, a dataset which contains thousands of diverse videos with high-quality object masks, and an associated benchmark with six tasks involving object tracking and segmentation in video. All tasks are evaluated using the same data and comparable metrics, which enables researchers to consider them in unison, and hence, more effectively pool knowledge from different methods across different tasks. Additionally, we demonstrate several baselines for all tasks and show that approaches for one task can be applied to another with a quantifiable and explainable performance difference.
@inproceedings{athar2023burst,
title={BURST: A Benchmark for Unifying Object Recognition, Segmentation and Tracking in Video},
author={Athar, Ali and Luiten, Jonathon and Voigtlaender, Paul and Khurana, Tarasha and Dave, Achal and Leibe, Bastian and Ramanan, Deva},
booktitle={WACV},
year={2023}
}
Learning 3D Human Pose Estimation from Dozens of Datasets using a Geometry-Aware Autoencoder to Bridge Between Skeleton Formats
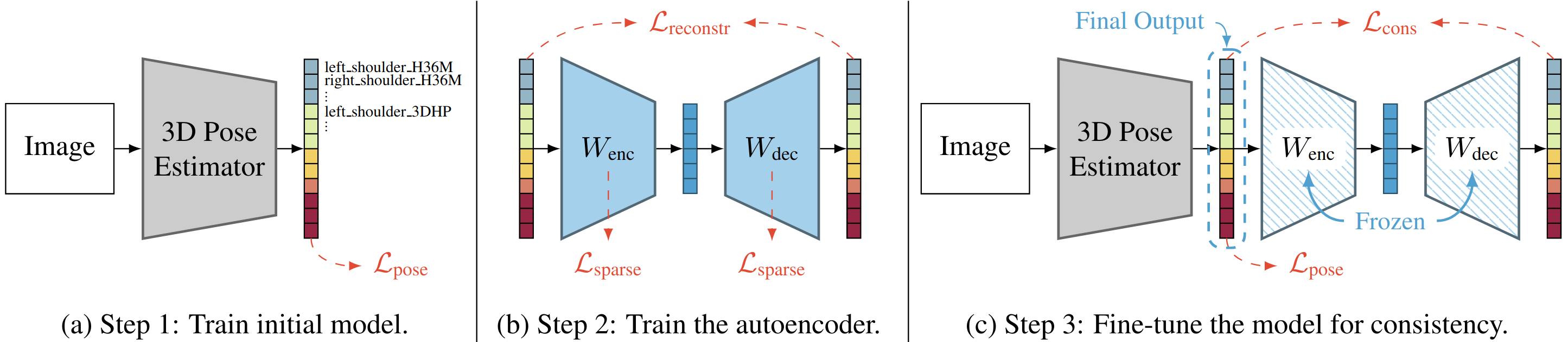
Deep learning-based 3D human pose estimation performs best when trained on large amounts of labeled data, making combined learning from many datasets an important research direction. One obstacle to this endeavor are the different skeleton formats provided by different datasets, i.e., they do not label the same set of anatomical landmarks. There is little prior research on how to best supervise one model with such discrepant labels. We show that simply using separate output heads for different skeletons results in inconsistent depth estimates and insufficient information sharing across skeletons. As a remedy, we propose a novel affine-combining autoencoder (ACAE) method to perform dimensionality reduction on the number of landmarks. The discovered latent 3D points capture the redundancy among skeletons, enabling enhanced information sharing when used for consistency regularization. Our approach scales to an extreme multi-dataset regime, where we use 28 3D human pose datasets to supervise one model, which outperforms prior work on a range of benchmarks, including the challenging 3D Poses in the Wild (3DPW) dataset. Our code and models are available for research purposes.
@inproceedings{Sarandi23WACV,
author = {S\'ar\'andi, Istv\'an and Hermans, Alexander and Leibe, Bastian},
title = {Learning {3D} Human Pose Estimation from Dozens of Datasets using a Geometry-Aware Autoencoder to Bridge Between Skeleton Formats},
booktitle = {IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},
year = {2023},
}
Mask3D for 3D Semantic Instance Segmentation

Modern 3D semantic instance segmentation approaches predominantly rely on specialized voting mechanisms followed by carefully designed geometric clustering techniques. Building on the successes of recent Transformer-based methods for object detection and image segmentation, we propose the first Transformer-based approach for 3D semantic instance segmentation. We show that we can leverage generic Transformer building blocks to directly predict instance masks from 3D point clouds. In our model called Mask3D each object instance is represented as an instance query. Using Transformer decoders, the instance queries are learned by iteratively attending to point cloud features at multiple scales. Combined with point features, the instance queries directly yield all instance masks in parallel. Mask3D has several advantages over current state-of-the-art approaches, since it neither relies on (1) voting schemes which require hand-selected geometric properties (such as centers) nor (2) geometric grouping mechanisms requiring manually-tuned hyper-parameters (e.g. radii) and (3) enables a loss that directly optimizes instance masks. Mask3D sets a new state-of-the-art on ScanNet test (+6.2 mAP), S3DIS 6-fold (+10.1 mAP), STPLS3D (+11.2 mAP) and ScanNet200 test (+12.4 mAP).
@article{Schult23ICRA,
title = {{Mask3D for 3D Semantic Instance Segmentation}},
author = {Schult, Jonas and Engelmann, Francis and Hermans, Alexander and Litany, Or and Tang, Siyu and Leibe, Bastian},
booktitle = {{International Conference on Robotics and Automation (ICRA)}},
year = {2023}
}
Neural Implicit Shape Editing Using Boundary Sensitivity

Neural fields are receiving increased attention as a geometric representation due to their ability to compactly store detailed and smooth shapes and easily undergo topological changes. Compared to classic geometry representations, however, neural representations do not allow the user to exert intuitive control over the shape. Motivated by this, we leverage boundary sensitivity to express how perturbations in parameters move the shape boundary. This allows to interpret the effect of each learnable parameter and study achievable deformations. With this, we perform geometric editing: finding a parameter update that best approximates a globally prescribed deformation. Prescribing the deformation only locally allows the rest of the shape to change according to some prior, such as semantics or deformation rigidity. Our method is agnostic to the model its training and updates the NN in-place. Furthermore, we show how boundary sensitivity helps to optimize and constrain objectives (such as surface area and volume), which are difficult to compute without first converting to another representation, such as a mesh.
@misc{berzins2023neural,
title={Neural Implicit Shape Editing using Boundary Sensitivity},
author={Arturs Berzins and Moritz Ibing and Leif Kobbelt},
year={2023},
eprint={2304.12951},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
Surface Maps via Adaptive Triangulations

We present a new method to compute continuous and bijective maps (surface homeomorphisms) between two or more genus-0 triangle meshes. In contrast to previous approaches, we decouple the resolution at which a map is represented from the resolution of the input meshes. We discretize maps via common triangulations that approximate the input meshes while remaining in bijective correspondence to them. Both the geometry and the connectivity of these triangulations are optimized with respect to a single objective function that simultaneously controls mapping distortion, triangulation quality, and approximation error. A discrete-continuous optimization algorithm performs both energy-based remeshing as well as global second-order optimization of vertex positions, parametrized via the sphere. With this, we combine the disciplines of compatible remeshing and surface map optimization in a unified formulation and make a contribution in both fields. While existing compatible remeshing algorithms often operate on a fixed pre-computed surface map, we can now globally update this correspondence during remeshing. On the other hand, bijective surface-to-surface map optimization previously required computing costly overlay meshes that are inherently tied to the input mesh resolution. We achieve significant complexity reduction by instead assessing distortion between the approximating triangulations. This new map representation is inherently more robust than previous overlay-based approaches, is less intricate to implement, and naturally supports mapping between more than two surfaces. Moreover, it enables adaptive multi-resolution schemes that, e.g., first align corresponding surface regions at coarse resolutions before refining the map where needed. We demonstrate significant speedups and increased flexibility over state-of-the art mapping algorithms at similar map quality, and also provide a reference implementation of the method.
@article{schmidt2023surface,
title={Surface Maps via Adaptive Triangulations},
author={Schmidt, Patrick and Pieper, D\"orte and Kobbelt, Leif},
year={2023},
journal={Computer Graphics Forum},
volume={42},
number={2},
}
TENETvr: Comprehensible Temporal Teleportation in Time-Varying Virtual Environments

The iterative design process of virtual environments commonly generates a history of revisions that each represent the state of the scene at a different point in time. Browsing through these discrete time points by common temporal navigation interfaces like time sliders, however, can be inaccurate and lead to an uncomfortably high number of visual changes in a short time. In this paper, we therefore present a novel technique called TENETvr (Temporal Exploration and Navigation in virtual Environments via Teleportation) that allows for efficient teleportation-based travel to time points in which a particular object of interest changed. Unlike previous systems, we suggest that changes affecting other objects in the same time span should also be mediated before the teleport to improve predictability. We therefore propose visualizations for nine different types of additions, property changes, and deletions. In a formal user study with 20 participants, we confirmed that this addition leads to significantly more efficient change detection, lower task loads, and higher usability ratings, therefore reducing temporal disorientation.
@INPROCEEDINGS{10316438,
author={Rupp, Daniel and Kuhlen, Torsten and Weissker, Tim},
booktitle={2023 IEEE International Symposium on Mixed and Augmented Reality (ISMAR)},
title={{TENETvr: Comprehensible Temporal Teleportation in Time-Varying Virtual Environments}},
year={2023},
volume={},
number={},
pages={922-929},
doi={10.1109/ISMAR59233.2023.00108}}
Who Did What When? Discovering Complex Historical Interrelations in Immersive Virtual Reality
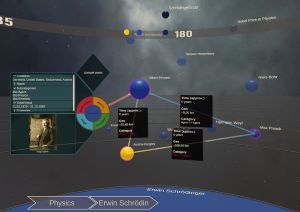
Traditional digital tools for exploring historical data mostly rely on conventional 2D visualizations, which often cannot reveal all relevant interrelationships between historical fragments (e.g., persons or events). In this paper, we present a novel interactive exploration tool for historical data in VR, which represents fragments as spheres in a 3D environment and arranges them around the user based on their temporal, geo, categorical and semantic similarity. Quantitative and qualitative results from a user study with 29 participants revealed that most participants considered the virtual space and the abstract fragment representation well-suited to explore historical data and to discover complex interrelationships. These results were particularly underlined by high usability scores in terms of attractiveness, stimulation, and novelty, while researching historical facts with our system did not impose unexpectedly high task loads. Additionally, the insights from our post-study interviews provided valuable suggestions for future developments to further expand the possibilities of our system.
@INPROCEEDINGS{10316480,
author={Derksen, Melanie and Becker, Julia and Elahi, Mohammad Fazleh and Maier, Angelika and Maile, Marius and Pätzold, Ingo and Penningroth, Jonas and Reglin, Bettina and Rothgänger, Markus and Cimiano, Philipp and Schubert, Erich and Schwandt, Silke and Kuhlen, Torsten and Botsch, Mario and Weissker, Tim},
booktitle={2023 IEEE International Symposium on Mixed and Augmented Reality (ISMAR)},
title={{Who Did What When? Discovering Complex Historical Interrelations in Immersive Virtual Reality}},
year={2023},
volume={},
number={},
pages={129-137},
doi={10.1109/ISMAR59233.2023.00027}}
Stay Vigilant: The Threat of a Replication Crisis in VR Locomotion Research

The ability to reproduce previously published research findings is an important cornerstone of the scientific knowledge acquisition process. However, the exact details required to reproduce empirical experiments vary depending on the discipline. In this paper, we summarize key replication challenges as well as their specific consequences for VR locomotion research. We then present the results of a literature review on artificial locomotion techniques, in which we analyzed 61 papers published in the last five years with respect to their report of essential details required for reproduction. Our results indicate several issues in terms of the description of the experimental setup, the scientific rigor of the research process, and the generalizability of results, which altogether points towards a potential replication crisis in VR locomotion research. As a countermeasure, we provide guidelines to assist researchers with reporting future artificial locomotion experiments in a reproducible form.
Best Paper Award!
@inproceedings{10.1145/3611659.3615697,
author = {Zielasko, Daniel and Weissker, Tim},
title = {Stay Vigilant: The Threat of a Replication Crisis in VR Locomotion Research},
year = {2023},
isbn = {9798400703287},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3611659.3615697},
doi = {10.1145/3611659.3615697},
abstract = {The ability to reproduce previously published research findings is an important cornerstone of the scientific knowledge acquisition process. However, the exact details required to reproduce empirical experiments vary depending on the discipline. In this paper, we summarize key replication challenges as well as their specific consequences for VR locomotion research. We then present the results of a literature review on artificial locomotion techniques, in which we analyzed 61 papers published in the last five years with respect to their report of essential details required for reproduction. Our results indicate several issues in terms of the description of the experimental setup, the scientific rigor of the research process, and the generalizability of results, which altogether points towards a potential replication crisis in VR locomotion research. As a countermeasure, we provide guidelines to assist researchers with reporting future artificial locomotion experiments in a reproducible form.},
booktitle = {Proceedings of the 29th ACM Symposium on Virtual Reality Software and Technology},
articleno = {39},
numpages = {10},
keywords = {Reproducibility, Virtual Reality, Replication Crisis, Teleportation, Locomotion, Steering},
location = {Christchurch, New Zealand},
series = {VRST '23}
}
Who's next? Integrating Non-Verbal Turn-Taking Cues for Embodied Conversational Agents

Taking turns in a conversation is a delicate interplay of various signals, which we as humans can easily decipher. Embodied conversational agents (ECAs) communicating with humans should leverage this ability for smooth and enjoyable conversations. Extensive research hasanalyzed human turn-taking cues, and attempts have been made to predict turn-taking based on observed cues. These cues vary from prosodic, semantic, and syntactic modulation over adapted gesture and gaze behavior to actively used respiration. However, when generating such behavior for social robots or ECAs, often only single modalities were considered, e.g., gazing. We strive to design a comprehensive system that produces cues for all non-verbal modalities: gestures, gaze, and breathing. The system provides valuable cues without requiring speech content adaptation. We evaluated our system in a VR based user study with N = 32 participants executing two subsequent tasks. First, we asked them to listen to two ECAs taking turns in several conversations. Second, participants engaged in taking turns with one of the ECAs directly. We examined the system’s usability and the perceived social presence of the ECAs' turn-taking behavior, both with respect to each individual non-verbal modality and their interplay. While we found effects of gesture manipulation in interactions with the ECAs, no effects on social presence were found.
This work is licensed under a Creative Commons Attribution International 4.0 License
@InProceedings{Ehret2023,
author = {Jonathan Ehret, Andrea Bönsch, Patrick Nossol, Cosima A. Ermert, Chinthusa Mohanathasan, Sabine J. Schlittmeier, Janina Fels and Torsten W. Kuhlen},
booktitle = {ACM International Conference on Intelligent Virtual Agents (IVA ’23)},
title = {Who's next? Integrating Non-Verbal Turn-Taking Cues for Embodied Conversational Agents},
year = {2023},
organization = {ACM},
pages = {8},
doi = {10.1145/3570945.3607312},
}
Micropolar Elasticity in Physically-Based Animation

We explore micropolar materials for the simulation of volumetric deformable solids. In graphics, micropolar models have only been used in the form of one-dimensional Cosserat rods, where a rotating frame is attached to each material point on the one-dimensional centerline. By carrying this idea over to volumetric solids, every material point is associated with a microrotation, an independent degree of freedom that can be coupled to the displacement through a material's strain energy density. The additional degrees of freedom give us more control over bending and torsion modes of a material. We propose a new orthotropic micropolar curvature energy that allows us to make materials stiff to bending in specific directions.
For the simulation of dynamic micropolar deformables we propose a novel incremental potential formulation with a consistent FEM discretization that is well suited for the use in physically-based animation. This allows us to easily couple micropolar deformables with dynamic collisions through a contact model inspired from the Incremental Potential Contact (IPC) approach. For the spatial discretization with FEM we discuss the challenges related to the rotational degrees of freedom and propose a scheme based on the interpolation of angular velocities followed by quaternion time integration at the quadrature points.
In our evaluation we validate the consistency and accuracy of our discretization approach and demonstrate several compelling use cases for micropolar materials. This includes explicit control over bending and torsion stiffness, deformation through prescription of a volumetric curvature field and robust interaction of micropolar deformables with dynamic collisions.
@article{LFJ+23,
author = {L\"{o}schner, Fabian and Fern\'{a}ndez-Fern\'{a}ndez, Jos\'{e} Antonio and Jeske, Stefan Rhys and Longva, Andreas and Bender, Jan},
title = {Micropolar Elasticity in Physically-Based Animation},
year = {2023},
issue_date = {August 2023},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
volume = {6},
number = {3},
url = {https://doi.org/10.1145/3606922},
doi = {10.1145/3606922},
journal = {Proceedings of the ACM on Computer Graphics and Interactive Techniques},
month = {aug},
articleno = {46},
numpages = {24}
}
A comparison of linear consistent correction methods for first-order SPH derivatives

A well-known issue with the widely used Smoothed Particle Hydrodynamics (SPH) method is the neighborhood deficiency. Near the surface, the SPH interpolant fails to accurately capture the underlying fields due to a lack of neighboring particles. These errors may introduce ghost forces or other visual artifacts into the simulation.
In this work we investigate three different popular methods to correct the first-order spatial derivative SPH operators up to linear accuracy, namely the Kernel Gradient Correction (KGC), Moving Least Squares (MLS) and Reproducing Kernel Particle Method (RKPM). We provide a thorough, theoretical comparison in which we remark strong resemblance between the aforementioned methods. We support this by an analysis using synthetic test scenarios. Additionally, we apply the correction methods in simulations with boundary handling, viscosity, surface tension, vorticity and elastic solids to showcase the reduction or elimination of common numerical artifacts like ghost forces. Lastly, we show that incorporating the correction algorithms in a state-of-the-art SPH solver only incurs a negligible reduction in computational performance.
@article{WJB23,
author = {Westhofen, Lukas and Jeske, Stefan and Bender, Jan},
title = {A Comparison of Linear Consistent Correction Methods for First-Order SPH Derivatives},
year = {2023},
issue_date = {August 2023},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
volume = {6},
number = {3},
url = {https://doi.org/10.1145/3606933},
doi = {10.1145/3606933},
journal = {Proceedings of the ACM on Computer Graphics and Interactive Techniques (SCA)},
month = {aug},
articleno = {48},
numpages = {20}
}
Effect of Head-Mounted Displays on Students’ Acquisition of Surgical Suturing Techniques Compared to an E-Learning and Tutor-Led Course: A Randomized Controlled Trial

Background: Although surgical suturing is one of the most important basic skills, many medical school graduates do not acquire sufficient knowledge of it due to its lack of integration into the curriculum or a shortage of tutors. E learning approaches attempt to address this issue but still rely on the involvement of tutors. Furthermore, the learning experience and visual spatial ability appear to play a critical role in surgical skill acquisition. Virtual reality head-mounted displays (HMDs) could address this, but the benefits of immersive and stereoscopic learning of surgical suturing techniques are still unclear.
Material and Methods: In this multi-arm randomized controlled trial, 150 novices participated. Three teaching modalities were compared: an e-learning course (monoscopic), an HMD-based course (stereoscopic, immersive), both self-directed, and a tutor-led course with feedback. Suturing performance was recorded by video camera both before and after course participation (>26 hours of video material) and assessed in a blinded fashion using the OSATS Global Rating Score (GRS). Furthermore, the optical flow of the videos was determined using an algorithm. The number of sutures performed was counted, visual spatial ability was measured with the mental rotation test (MRT), and courses were assessed with questionnaires.
Results: Students' self-assessment in the HMD-based course was comparable to that of the tutor-led course and significantly better than in the e-learning course (P=0.003). Course suitability was rated best for the tutor-led course (x=4.8), followed by the HMD-based (x=3.6) and e-learning (x=2.5) courses. The median GRS between courses was comparable (P=0.15) at 12.4 (95% CI 10.0 12.7) for the e-learning course, 14.1 (95% CI 13.0-15.0) for the HMD-based course, and 12.7 (95% CI 10.3-14.2) for the tutor-led course. However, the GRS was significantly correlated with the number of sutures performed during the training session (P=0.002), but not with visual-spatial ability (P=0.626). Optical flow (R2=0.15, P<0.001) and the number of sutures performed (R2=0.73, P<0.001) can be used as additional measures to GRS.
Conclusion: The use of HMDs with stereoscopic and immersive video provides advantages in the learning experience and should be preferred over a traditional web application for e-learning. Contrary to expectations, feedback is not necessary for novices to achieve a sufficient level in suturing; only the number of surgical sutures performed during training is a good determinant of competence improvement. Nevertheless, feedback still enhances the learning experience. Therefore, automated assessment as an alternative feedback approach could further improve self-directed learning modalities. As a next step, the data from this study could be used to develop such automated AI-based assessments.
@Article{Peters2023,
author = {Philipp Peters and Martin Lemos and Andrea Bönsch and Mark Ooms and Max Ulbrich and Ashkan Rashad and Felix Krause and Myriam Lipprandt and Torsten Wolfgang Kuhlen and Rainer Röhrig and Frank Hölzle and Behrus Puladi},
journal = {International Journal of Surgery},
title = {Effect of head-mounted displays on students' acquisition of surgical suturing techniques compared to an e-learning and tutor-led course: A randomized controlled trial},
year = {2023},
month = {may},
volume = {Publish Ahead of Print},
creationdate = {2023-05-12T11:00:37},
doi = {10.1097/js9.0000000000000464},
modificationdate = {2023-05-12T11:00:37},
publisher = {Ovid Technologies (Wolters Kluwer Health)},
}
Consistent SPH Rigid-Fluid Coupling

A common way to handle boundaries in SPH fluid simulations is to sample the surface of the boundary geometry using particles. These boundary particles are assigned the same properties as the fluid particles and are considered in the pressure force computation to avoid a penetration of the boundary. However, the pressure solver requires a pressure value for each particle. These are typically not computed for the boundary particles due to the computational overhead. Therefore, several strategies have been investigated in previous works to obtain boundary pressure values. A popular, simple technique is pressure mirroring, which mirrors the values from the fluid particles. This method is efficient, but may cause visual artifacts. More complex approaches like pressure extrapolation aim to avoid these artifacts at the cost of computation time.
We introduce a constraint-based derivation of Divergence-Free SPH (DFSPH) --- a common state-of-the-art pressure solver. This derivation gives us new insights on how to integrate boundary particles in the pressure solve without the need of explicitly computing boundary pressure values. This yields a more elegant formulation of the pressure solver that avoids the aforementioned problems.
@inproceedings {BWJ23,
booktitle = {Vision, Modeling, and Visualization},
title = {{Consistent SPH Rigid-Fluid Coupling}},
author = {Jan Bender and Lukas Westhofen and Stefan Rhys Jeske},
year = {2023},
publisher = {The Eurographics Association},
ISBN = {978-3-03868-232-5},
DOI = {10.2312/vmv.20231244}
}
Weighted Laplacian Smoothing for Surface Reconstruction of Particle-based Fluids
Vision, Modeling and Visualization

In physically-based animation, producing detailed and realistic surface reconstructions for rendering is an important part of a simulation pipeline for particle-based fluids. In this paper we propose a post-processing approach to obtain smooth surfaces from "blobby" marching cubes triangulations without visual volume loss or shrinkage of drops and splashes. In contrast to other state-of-the-art methods that often require changes to the entire reconstruction pipeline our approach is easy to implement and less computationally expensive.
The main component is Laplacian mesh smoothing with our proposed feature weights that dampen the smoothing in regions of the mesh with splashes and isolated particles without reducing effectiveness in regions that are supposed to be flat. In addition, we suggest a specialized decimation procedure to avoid artifacts due to low-quality triangle configurations generated by marching cubes and a normal smoothing pass to further increase quality when visualizing the mesh with physically-based rendering. For improved computational efficiency of the method, we outline the option of integrating computation of our weights into an existing reconstruction pipeline as most involved quantities are already known during reconstruction. Finally, we evaluate our post-processing implementation on high-resolution smoothed particle hydrodynamics (SPH) simulations.
@inproceedings {LBJB23,
booktitle = {Vision, Modeling, and Visualization},
title = {{Weighted Laplacian Smoothing for Surface Reconstruction of Particle-based Fluids}},
author = {Fabian L\"{o}schner and Timna B\"{o}ttcher and Stefan Rhys Jeske and Jan Bender},
year = {2023},
publisher = {The Eurographics Association},
ISBN = {978-3-03868-232-5},
DOI = {10.2312/vmv.20231245}
}
Leveraging BC6H Texture Compression and Filtering for Efficient Vector Field Visualization

The steady advance of compute hardware is accompanied by an ever-steeper amount of data to be processed for visualization. Limited memory bandwidth provides a significant bottleneck to the runtime performance of visualization algorithms while limited video memory requires complex out-of-core loading techniques for rendering large datasets. Data compression methods aim to overcome these limitations, potentially at the cost of information loss. This work presents an approach to the compression of large data for flow visualization using the BC6H texture compression format natively supported, and therefore effortlessly leverageable, on modern GPUs. We assess the performance and accuracy of BC6H for compression of steady and unsteady vector fields and investigate its applicability to particle advection. The results indicate an improvement in memory utilization as well as runtime performance, at a cost of moderate loss in precision.
@inproceedings{10.2312:vmv.20231238,
booktitle = {Vision, Modeling, and Visualization},
editor = {Guthe, Michael and Grosch, Thorsten},
title = {{Leveraging BC6H Texture Compression and Filtering for Efficient Vector Field Visualization}},
author = {Oehrl, Simon and Milke, Jan Frieder and Koenen, Jens and Kuhlen, Torsten W. and Gerrits, Tim},
year = {2023},
publisher = {The Eurographics Association},
ISBN = {978-3-03868-232-5},
DOI = {10.2312/vmv.20231238}
}
Voice Quality and its Effects on University Students' Listening Effort in a Virtual Seminar Room
A teacher’s poor voice quality may increase listening effort in pupils, but it is unclear whether this effect persists in adult listeners. Thus, the goal of this study is to examine the impact of vocal hoarseness on university students' listening effort in a virtual seminar room. An audio-visual immersive virtual reality environment is utilized to simulate a typical seminar room with common background sounds and fellow students represented as wooden mannequins. Participants wear a head-mounted display and are equipped with two controllers to engage in a dual-task paradigm. The primary task is to listen to a virtual professor reading short texts and retain relevant content information to be recalled later. The texts are presented either in a normal or an imitated hoarse voice. In parallel, participants perform a secondary task which is responding to tactile vibration patterns via the controllers. It is hypothesized that listening to the hoarse voice induces listening effort, resulting in more cognitive resources needed for primary task performance while secondary task performance is hindered. Results are presented and discussed in light of students’ cognitive performance and listening challenges in higher education learning environments.
@INPROCEEDINGS{Schiller:977871,
author = {Schiller, Isabel Sarah and Aspöck, Lukas and Breuer,
Carolin and Ehret, Jonathan and Bönsch, Andrea and Fels,
Janina and Kuhlen, Torsten and Schlittmeier, Sabine Janina},
title = {{V}oice Quality and its Effects on University
Students' Listening Effort in a Virtual Seminar Room},
year = {2023},
month = {Dec},
date = {2023-12-04},
organization = {Acoustics 2023, Sydney (Australia), 4
Dec 2023 - 8 Dec 2023},
doi = {10.1121/10.0022982}
}
Poster: DaVE - A curated Database of Visualization Examples

Visualization is used throughout all scientific domains for efficient analysis of data and experiments. Learning, underestanding, implementing, and applying suitable, state-of-the-art visualization techniques in HPC projects takes time and and a high level of technological ability and experience. DaVE sets out to offer a user-friendly resource with detailed descriptions, samples, and HPC-specific implementations of visualization methods. It simplifies method discovery with tags and encourages collaboration to foster a platform for sharing best practices and staying updated thus filling a crucial gap in the HPC community by providing a central resource for advanced visualization.
@misc{tim_gerrits_2023_8381126,
author = {Tim Gerrits and
Christoph Garth},
title = {{DaVE - A curated Database of Visualization
Examples}},
month = sep,
year = 2023,
publisher = {Zenodo},
doi = {10.5281/zenodo.8381126},
url = {https://doi.org/10.5281/zenodo.8381126}
}
A Case Study on Providing Accessibility-Focused In-Transit Architectures for Neural Network Simulation and Analysis
Due to the ever-increasing availability of high-performance computing infrastructure, developers can simulate increasingly complex models. However, the increased complexity comes with new challenges regarding data processing and visualization due to the sheer size of simulations. Exploring simulation results needs to be handled efficiently via in-situ/in-transit analysis during run-time. However, most existing in-transit solutions require sophisticated and prior knowledge and significant alteration to existing simulation and visualization code, which produces a high entry barrier for many projects. In this work, we report how Insite, a lightweight in-transit pipeline, provided in-transit visualization and computation capability to various research applications in the neuronal network simulation domain. We describe the development process, including feedback from developers and domain experts, and discuss implications.
@inproceedings{kruger2023case,
title={A Case Study on Providing Accessibility-Focused In-Transit Architectures for Neural Network Simulation and Analysis},
author={Kr{\"u}ger, Marcel and Oehrl, Simon and Kuhlen, Torsten Wolfgang and Gerrits, Tim},
booktitle={International Conference on High Performance Computing},
pages={277--287},
year={2023},
organization={Springer}
}
Towards Plausible Cognitive Research in Virtual Environments: The Effect of Audiovisual Cues on Short-Term Memory in Two Talker Conversations

When three or more people are involved in a conversation, often one conversational partner listens to what the others are saying and has to remember the conversational content. The setups in cognitive-psychological experiments often differ substantially from everyday listening situations by neglecting such audiovisual cues. The presence of speech-related audiovisual cues, such as the spatial position, and the appearance or non-verbal behavior of the conversing talkers may influence the listener's memory and comprehension of conversational content. In our project, we provide first insights into the contribution of acoustic and visual cues on short-term memory, and (social) presence. Analyses have shown that the memory performance varies with increasingly more plausible audiovisual characteristics. Furthermore, we have conducted a series of experiments regarding the influence of the visual reproduction medium (virtual reality vs. traditional computer screens) and spatial or content audio-visual mismatch on auditory short-term memory performance. Adding virtual embodiments to the talkers allowed us to conduct experiments on the influence of the fidelity of co-verbal gestures and turn-taking signals. Thus, we are able to provide a more plausible paradigm for investigating memory for two-talker conversations within an interactive audiovisual virtual reality environment.
@InProceedings{Ehret2023Audictive,
author = {Jonathan Ehret, Cosima A. Ermert, Chinthusa
Mohanathasan, Janina Fels, Torsten W. Kuhlen and Sabine J. Schlittmeier},
booktitle = {Proceedings of the 1st AUDICTIVE Conference},
title = {Towards Plausible Cognitive Research in Virtual
Environments: The Effect of Audiovisual Cues on Short-Term Memory in
Two-Talker Conversations},
year = {2023},
pages = {68-72},
doi = { 10.18154/RWTH-2023-08409},
}
DasherVR: Evaluating a Predictive Text Entry System in Immersive Virtual Reality

Inputting text fluently in virtual reality is a topic still under active research, since many previously presented solutions have drawbacks in either speed, error rate, privacy or accessibility. To address these drawbacks, in this paper we adapted the predictive text entry system "Dasher" into an immersive virtual environment. Our evaluation with 20 participants shows that Dasher offers a good user experience with input speeds similar to other virtual text input techniques in the literature while maintaining low error rates. In combination with positive user feedback, we therefore believe that DasherVR is a promising basis for further research on accessible text input in immersive virtual reality.
@inproceedings{pape2023,
title = {{{DasherVR}}: {{Evaluating}} a {{Predictive Text Entry System}} in {{Immersive Virtual Reality}}},
booktitle = {Towards an {{Inclusive}} and {{Accessible Metaverse}} at {{CHI}}'23},
author = {Pape, Sebastian and Ackermann, Jan Jakub and Weissker, Tim and Kuhlen, Torsten W},
doi = {https://doi.org/10.18154/RWTH-2023-05093},
year = {2023}
}
A Case Study on Providing Immersive Visualization for Neuronal Network Data Using COTS Soft- and Hardware

COTS VR hardware and modern game engines create the impression that bringing even complex data into VR has become easy. In this work, we investigate to what extent game engines can support the development of immersive visualization software with a case study. We discuss how the engine can support the development and where it falls short, e.g., failing to provide acceptable rendering performance for medium and large-sized data sets without using more sophisticated features.
@INPROCEEDINGS{10108843,
author={Krüger, Marcel and Li, Qin and Kuhlen, Torsten W. and Gerrits, Tim},
booktitle={2023 IEEE Conference on Virtual Reality and 3D User Interfaces Abstracts and Workshops (VRW)},
title={A Case Study on Providing Immersive Visualization for Neuronal Network Data Using COTS Soft- and Hardware},
year={2023},
volume={},
number={},
pages={201-205},
doi={10.1109/VRW58643.2023.00050}}
Enhanced Auditoriums for Attending Talks in Social Virtual Reality
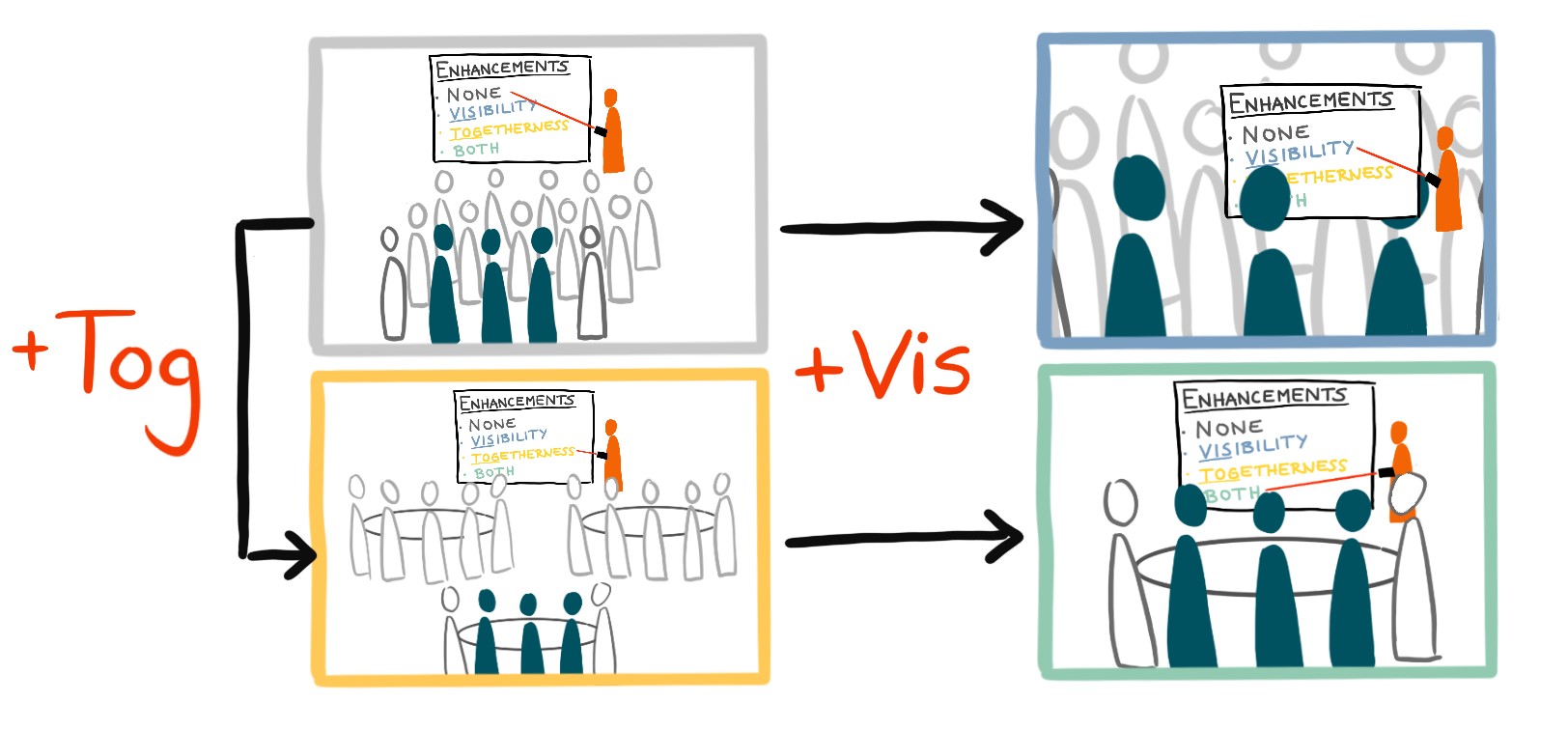
Replicating traditional auditorium layouts for attending talks in social virtual reality often results in poor visibility of the presentation and a reduced feeling of being there together with others. Motivated by the use case of academic conferences, we therefore propose to display miniature representations of the stage close to the viewers for enhanced presentation visibility as well as group table arrangements for enhanced social co-watching. We conducted an initial user study with 12 participants in groups of three to evaluate the influence of these ideas on audience experience. Our results confirm the hypothesized positive effects of both enhancements and show that their combination was particularly appreciated by audience members. Our results therefore strongly encourage us to rethink conventional auditorium layouts in social virtual reality.
@inproceedings{10.1145/3544549.3585718,
author = {Weissker, Tim and Pieters, Leander and Kuhlen, Torsten},
title = {Enhanced Auditoriums for Attending Talks in Social Virtual Reality},
year = {2023},
isbn = {9781450394222},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3544549.3585718},
doi = {10.1145/3544549.3585718},
abstract = {Replicating traditional auditorium layouts for attending talks in social virtual reality often results in poor visibility of the presentation and a reduced feeling of being there together with others. Motivated by the use case of academic conferences, we therefore propose to display miniature representations of the stage close to the viewers for enhanced presentation visibility as well as group table arrangements for enhanced social co-watching. We conducted an initial user study with 12 participants in groups of three to evaluate the influence of these ideas on audience experience. Our results confirm the hypothesized positive effects of both enhancements and show that their combination was particularly appreciated by audience members. Our results therefore strongly encourage us to rethink conventional auditorium layouts in social virtual reality.},
booktitle = {Extended Abstracts of the 2023 CHI Conference on Human Factors in Computing Systems},
articleno = {101},
numpages = {7},
keywords = {Audience Experience, Head-Mounted Display, Multi-User, Social Interaction, Virtual Presentations, Virtual Reality},
location = {<conf-loc>, <city>Hamburg</city>, <country>Germany</country>, </conf-loc>},
series = {CHI EA '23}
}
Advantages of a Training Course for Surgical Planning in Virtual Reality in Oral and Maxillofacial Surgery
Background: As an integral part of computer-assisted surgery, virtual surgical planning(VSP) leads to significantly better surgery results, such as for oral and maxillofacial reconstruction with microvascular grafts of the fibula or iliac crest. It is performed on a 2D computer desktop (DS) based on preoperative medical imaging. However, in this environment, VSP is associated with shortcomings, such as a time-consuming planning process and the requirement of a learning process. Therefore, a virtual reality VR)-based VSP application has great potential to reduce or even overcome these shortcomings due to the benefits of visuospatial vision, bimanual interaction, and full immersion. However, the efficacy of such a VR environment has not yet been investigated.
Objective: Does VR offer advantages in learning process and working speed while providing similar good results compared to a traditional DS working environment?
Methods: During a training course, novices were taught how to use a software application in a DS environment (3D Slicer) and in a VR environment (Elucis) for the segmentation of fibulae and os coxae (n = 156), and they were askedto carry out the maneuvers as accurately and quickly as possible. The individual learning processes in both environments were compared usingobjective criteria (time and segmentation performance) and self-reported questionnaires. The models resulting from the segmentation were compared mathematically (Hausdorff distance and Dice coefficient) and evaluated by two experienced radiologists in a blinded manner (score).
Results: During a training course, novices were taught how to use a software application in a DS environment (3D Slicer) and in a VR environment (Elucis)for the segmentation of fibulae and os coxae (n = 156), and they were asked to carry out the maneuvers as accurately and quickly as possible. The individual learning processes in both environments were compared using objective criteria (time and segmentation performance) and self-reported questionnaires. The models resulting from the segmentation were compared mathematically (Hausdorff distance and Dice coefficient) and evaluated by two experienced radiologists in a blinded manner (score).
Conclusions: The more rapid learning process and the ability to work faster in the VR environment could save time and reduce the VSP workload, providing certain advantages over the DS environment.
@article{Ulbrich2022,
title={Advantages of a Training Course for Surgical Planning in Virtual
Reality in Oral and Maxillofacial Surgery },
author={ Ulbrich, M., Van den Bosch, V., Bönsch, A., Gruber, L.J., Ooms,
M., Melchior, C., Motmaen, I., Wilpert, C., Rashad, A., Kuhlen, T.W.,
Hölzle, F., Puladi, B.},
journal={JMIR Serious Games},
volume={ 28/11/2022:40541 (forthcoming/in press) },
year={2022},
publisher={JMIR Publications Inc., Toronto, Canada}
}
IEEE SciVis Contest 2023 - Dataset of Neuronal Network Simulations of the Human Brain
The IEEE SciVis Contest is held annually as part of the IEEE VIS Conference. It challenges participants within the visualization community to create innovative and effective state-of-the-art visualizations to analyze and understand complex scientific data. In 2023, the data described neuronal network simulations of plasticity changes in the human brain provided by a collaboration of the Crosssectional Group Parallelism and Performance, and the Crosssectional Group Visualization within the National High Performance Computing Center for Computational Engineering Science (NHR4CES).
@dataset{gerrits_2024_10519411,
author = {Gerrits, Tim and
Czappa, Fabian and
Banesh, Divya and
Wolf, Felix},
title = {{IEEE SciVis Contest 2023 - Dataset of Neuronal
Network Simulations of the Human Brain}},
month = jan,
year = 2024,
publisher = {Zenodo},
version = {1.0},
doi = {10.5281/zenodo.10519411},
url = {https://doi.org/10.5281/zenodo.10519411}
}
Poster: Memory and Listening Effort in Two-Talker Conversations: Does Face Visibility Help Us Remember?
Listening to and remembering conversational content is a highly demanding task that requires the interplay of auditory processes and several cognitive functions. In face-to-face conversations, it is quite impossible that two talker’s’ audio signals originate from the same spatial position and that their faces are hidden from view. The availability of such audiovisual cues when listening potentially influences memory and comprehension of the heard content. In the present study, we investigated the effect of static visual faces of two talkers and cognitive functions on the listener’s short-term memory of conversations and listening effort. Participants performed a dual-task paradigm including a primary listening task, where a conversation between two spatially separated talkers (+/- 60°) with static faces was presented. In parallel, a vibrotactile task was administered, independently of both visual and auditory modalities. To investigate the possibility of person-specific factors influencing short-term memory, we assessed additional cognitive functions like working memory. We discuss our results in terms of the role that visual information and cognitive functions play in short-term memory of conversations.
@InProceedings{ Mohanathasan2023ESCoP,
author = { Chinthusa Mohanathasan, Jonathan Ehret, Cosima A. Ermert, Janina Fels, Torsten Wolfgang Kuhlen and Sabine J. Schlittmeier},
booktitle = { 23. Conference of the European Society for Cognitive Psychology , Porto , Portugal , ESCoP 2023},
title = { Memory and Listening Effort in Two-Talker Conversations: Does Face Visibility Help Us Remember?},
year = {2023},
}
Towards More Realistic Listening Research in Virtual Environments: The Effect of Spatial Separation of Two Talkers in Conversations on Memory and Listening Effort
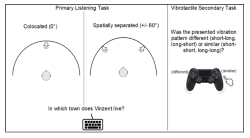
between three or more people often include phases in which one conversational partner is the listener while the others are conversing. In face-to-face conversations, it is quite unlikely to have two talkers’ audio signals come from the same spatial location - yet monaural-diotic sound presentation is often realized in cognitive-psychological experiments. However, the availability of spatial cues probably influences the cognitive processing of heard conversational content. In the present study we test this assumption by investigating spatial separation of conversing talkers in the listener’s short-term memory and listening effort. To this end, participants were administered a dual-task paradigm. In the primary task, participants listened to a conversation between two alternating talkers in a non-noisy setting and answered questions on the conversational content after listening. The talkers’ audio signals were presented at a distance of 2.5m from the listener either spatially separated (+/- 60°) or co-located (0°; within-subject). As a secondary task, participants worked in parallel to the listening task on a vibrotactile stimulation task, which is detached from auditory and visual modalities. The results are reported and discussed in particular regarding future listening experiments in virtual environments.
@InProceedings{Mohanathasan2023DAGA,
author = {Chinthusa Mohanathasan, Jonathan Ehret, Cosima A.
Ermert, Janina Fels, Torsten Wolfgang Kuhlen and Sabine J. Schlittmeier},
booktitle = {49. Jahrestagung für Akustik , Hamburg , Germany ,
DAGA 2023},
title = {Towards More Realistic Listening Research in Virtual
Environments: The Effect of Spatial Separation of Two Talkers in
Conversations on Memory and Listening Effort},
year = {2023},
pages = {1425-1428},
doi = { 10.18154/RWTH-2023-05116},
}
Towards Discovering Meaningful Historical Relationships in Virtual Reality

Traditional digital tools for exploring historical data mostly rely on conventional 2D visualizations, which often cannot reveal all relevant interrelationships between historical fragments. We are working on a novel interactive exploration tool for historical data in virtual reality, which arranges fragments in a 3D environment based on their temporal, spatial and categorical proximity to a reference fragment. In this poster, we report on an initial expert review of our approach, giving us valuable insights into the use cases and requirements that inform our further developments.
@INPROCEEDINGS{Derksen2023,
author={Derksen, Melanie and Weissker, Tim and Kuhlen, Torsten and Botsch, Mario},
booktitle={2023 IEEE Conference on Virtual Reality and 3D User Interfaces Abstracts and Workshops (VRW)},
title={Towards Discovering Meaningful Historical Relationships in Virtual Reality},
year={2023},
volume={},
number={},
pages={697-698},
doi={10.1109/VRW58643.2023.00191}}
Gaining the High Ground: Teleportation to Mid-Air Targets in Immersive Virtual Environments

Most prior teleportation techniques in virtual reality are bound to target positions in the vicinity of selectable scene objects. In this paper, we present three adaptations of the classic teleportation metaphor that enable the user to travel to mid-air targets as well. Inspired by related work on the combination of teleports with virtual rotations, our three techniques differ in the extent to which elevation changes are integrated into the conventional target selection process. Elevation can be specified either simultaneously, as a connected second step, or separately from horizontal movements. A user study with 30 participants indicated a trade-off between the simultaneous method leading to the highest accuracy and the two-step method inducing the lowest task load as well as receiving the highest usability ratings. The separate method was least suitable on its own but could serve as a complement to one of the other approaches. Based on these findings and previous research, we define initial design guidelines for mid-air navigation techniques.
@ARTICLE{10049698,
author={Weissker, Tim and Bimberg, Pauline and Gokhale, Aalok Shashidhar and Kuhlen, Torsten and Froehlich, Bernd},
journal={IEEE Transactions on Visualization and Computer Graphics},
title={Gaining the High Ground: Teleportation to Mid-Air Targets in Immersive Virtual Environments},
year={2023},
volume={29},
number={5},
pages={2467-2477},
keywords={Teleportation;Navigation;Avatars;Visualization;Task analysis;Floors;Virtual environments;Virtual Reality;3D User Interfaces;3D Navigation;Head-Mounted Display;Teleportation;Flying;Mid-Air Navigation},
doi={10.1109/TVCG.2023.3247114}}
Poster: Enhancing Proxy Localization in World in Miniatures Focusing on Virtual Agents

Virtual agents (VAs) are increasingly utilized in large-scale architectural immersive virtual environments (LAIVEs) to enhance user engagement and presence. However, challenges persist in effectively localizing these VAs for user interactions and optimally orchestrating them for an interactive experience. To address these issues, we propose to extend world in miniatures (WIMs) through different localization and manipulation techniques as these 3D miniature scene replicas embedded within LAIVEs have already demonstrated effectiveness for wayfinding, navigation, and object manipulation. The contribution of our ongoing research is thus the enhancement of manipulation and localization capabilities within WIMs, focusing on the use case of VAs.
@InProceedings{Boensch2023c,
author = {Andrea Bönsch, Radu-Andrei Coanda, and Torsten W.
Kuhlen},
booktitle = {{V}irtuelle und {E}rweiterte {R}ealit\"at, 14.
{W}orkshop der {GI}-{F}achgruppe {VR}/{AR}},
title = {Enhancing Proxy Localization in World in
Miniatures Focusing on Virtual Agents},
year = {2023},
organization = {Gesellschaft für Informatik e.V.},
doi = {10.18420/vrar2023_3381}
}
Poster: Whom Do You Follow? Pedestrian Flows Constraining the User’s Navigation during Scene Exploration

In this work-in-progress, we strive to combine two wayfinding techniques supporting users in gaining scene knowledge, namely (i) the River Analogy, in which users are considered as boats automatically floating down predefined rivers, e.g., streets in an urban scene, and (ii) virtual pedestrian flows as social cues indirectly guiding users through the scene. In our combined approach, the pedestrian flows function as rivers. To navigate through the scene, users leash themselves to a pedestrian of choice, considered as boat, and are dragged along the flow towards an area of interest. Upon arrival, users can detach themselves to freely explore the site without navigational constraints. We briefly outline our approach, and discuss the results of an initial study focusing on various leashing visualizations.
@InProceedings{Boensch2023b,
author = {Andrea Bönsch, Lukas B. Zimmermann, Jonathan Ehret, and Torsten W.Kuhlen},
booktitle = {ACM International Conferenceon Intelligent Virtual Agents (IVA ’23)},
title = {Whom Do You Follow? Pedestrian Flows Constraining the User’sNavigation during Scene Exploration},
year = {2023},
organization = {ACM},
pages = {3},
doi = {10.1145/3570945.3607350},
}
Poster: Where Do They Go? Overhearing Conversing Pedestrian Groups during Scene Exploration

On entering an unknown immersive virtual environment, a user’s first task is gaining knowledge about the respective scene, termed scene exploration. While many techniques for aided scene exploration exist, such as virtual guides, or maps, unaided wayfinding through pedestrians-as-cues is still in its infancy. We contribute to this research by indirectly guiding users through pedestrian groups conversing about their target location. A user who overhears the conversation without being a direct addressee can consciously decide whether to follow the group to reach an unseen point of interest. We outline our approach and give insights into the results of a first feasibility study in which we compared our new approach to non-talkative groups and groups conversing about random topics.
@InProceedings{Boensch2023a,
author = {Andrea Bönsch, Till Sittart, Jonathan Ehret, and Torsten W. Kuhlen},
booktitle = {ACM International Conference on Intelligent VirtualAgents (IVA ’23)},
title = {Where Do They Go? Overhearing Conversing Pedestrian Groups duringScene Exploration},
year = {2023},
pages = {3},
publisher = {ACM},
doi = {10.1145/3570945.3607351},
}
Octree Transformer: Autoregressive 3D Shape Generation on Hierarchically Structured Sequences
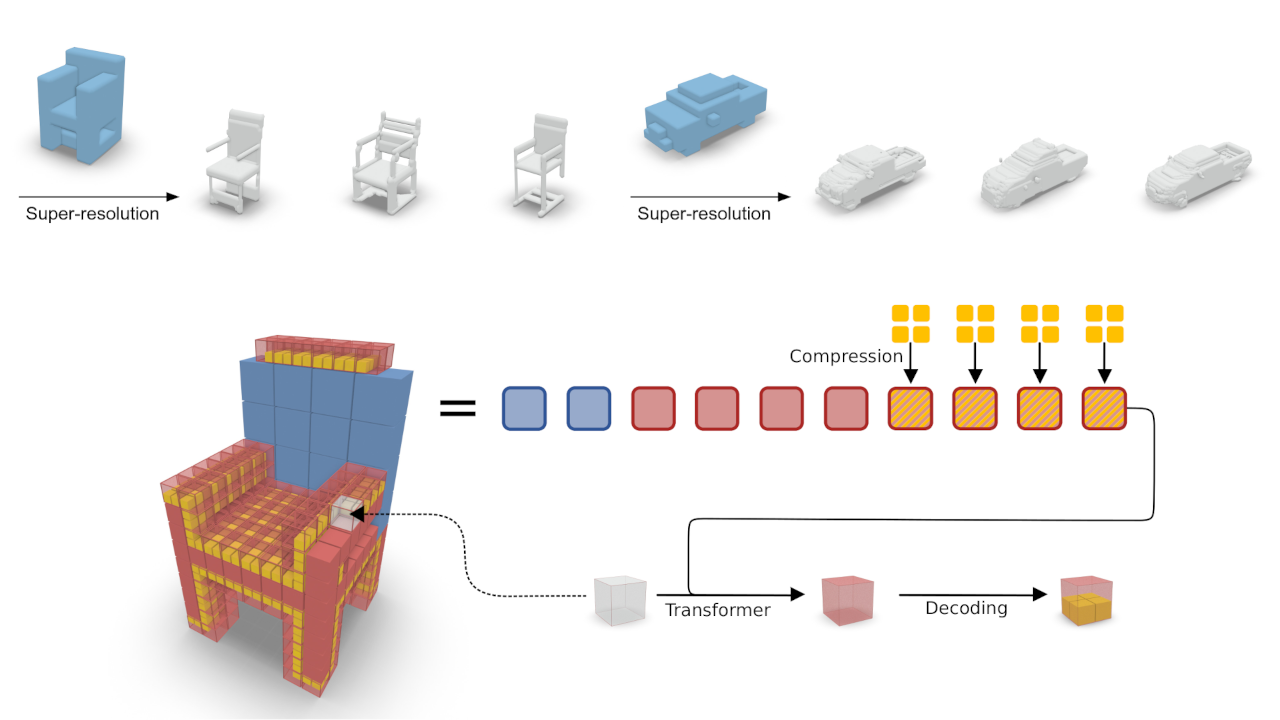
Autoregressive models have proven to be very powerful in NLP text generation tasks and lately have gained pop ularity for image generation as well. However, they have seen limited use for the synthesis of 3D shapes so far. This is mainly due to the lack of a straightforward way to linearize 3D data as well as to scaling problems with the length of the resulting sequences when describing complex shapes. In this work we address both of these problems. We use octrees as a compact hierarchical shape representation that can be sequentialized by traversal ordering. Moreover, we introduce an adaptive compression scheme, that significantly reduces sequence lengths and thus enables their effective generation with a transformer, while still allowing fully autoregressive sampling and parallel training. We demonstrate the performance of our model by performing superresolution and comparing against the state-of-the-art in shape generation.
@inproceedings{ibing_octree,
author = {Moritz Ibing and
Gregor Kobsik and
Leif Kobbelt},
title = {Octree Transformer: Autoregressive 3D Shape Generation on Hierarchically Structured Sequences},
booktitle = {{IEEE/CVF} Conference on Computer Vision and Pattern Recognition Workshops,
{CVPR} Workshops 2023},
publisher = {{IEEE}},
year = {2023},
}
AuViST - An Audio-Visual Speech and Text Database for the Heard-Text-Recall Paradigm
The Audio-Visual Speech and Text (AuViST) database provides additional material to the heardtext-recall (HTR) paradigm by Schlittmeier and colleagues. German audio recordings in male and female voice as well as matching face tracking data are provided for all texts.
Poster: Memory and Listening Effort in Conversations: The Role of Spatial Cues and Cognitive Functions
Conversations involving three or more people often include phases where one conversational partner listens to what the others are saying and has to remember the conversational content. It is possible that the presence of speech-related auditory information, such as different spatial positions of conversing talkers, influences listener's memory and comprehension of conversational content. However, in cognitive-psychological experiments, talkers’ audio signals are often presented diotically, i.e., identically to both ears as mono signals. This does not reflect face-to-face conversations where two talkers’ audio signals never come from the same spatial location. Therefore, in the present study, we examine how the spatial separation of two conversing talkers affects listener’s short-term memory of heard information and listening effort. To accomplish this, participants were administered a dual-task paradigm. In the primary task, participants listened to a conversation between a female and a male talker and then responded to content-related questions. The talkers’ audio signals were presented via headphones at a distance of 2.5m from the listener either spatially separated (+/- 60°) or co-located (0°). In parallel to this listening task, participants performed a vibrotactile pattern recognition task as a secondary task, that is independent of both auditory and visual modalities. In addition, we measured participants’ working memory capacity, selective visual attention, and mental speed to control for listener-specific characteristics that may affect listener’s memory performance. We discuss the extent to which spatial cues affect higher-level auditory cognition, specifically short-term memory of conversational content.
@InProceedings{ Mohanathasan2023TeaP,
author = { Chinthusa Mohanathasan, Jonathan Ehret, Cosima A.
Ermert, Janina Fels, Torsten Wolfgang Kuhlen and Sabine J. Schlittmeier},
booktitle = { Abstracts of the 65th TeaP : Tagung experimentell
arbeitender Psycholog:innen, Conference of Experimental Psychologists},
title = { Memory and Listening Effort in Conversations: The
Role of Spatial Cues and Cognitive Functions},
year = {2023},
pages = {252-252},
}
Audio-Visual Content Mismatches in the Serial Recall Paradigm
In many everyday scenarios, short-term memory is crucial for human interaction, e.g., when remembering a shopping list or following a conversation. A well-established paradigm to investigate short-term memory performance is the serial recall. Here, participants are presented with a list of digits in random order and are asked to memorize the order in which the digits were presented. So far, research in cognitive psychology has mostly focused on the effect of auditory distractors on the recall of visually presented items. The influence of visual distractors on the recall of auditory items has mostly been ignored. In the scope of this talk, we designed an audio-visual serial recall task. Along with the auditory presentation of the to-remembered digits, participants saw the face of a virtual human, moving the lips according to the spoken words. However, the gender of the face did not always match the gender of the voice heard, hence introducing an audio-visual content mismatch. The results give further insights into the interplay of visual and auditory stimuli in serial recall experiments.
@InProceedings{Ermert2023DAGA,
author = {Cosima A. Ermert, Jonathan Ehret, Torsten Wolfgang
Kuhlen, Chinthusa Mohanathasan, Sabine J. Schlittmeier and Janina Fels},
booktitle = {49. Jahrestagung für Akustik , Hamburg , Germany ,
DAGA 2023},
title = {Audio-Visual Content Mismatches in the Serial Recall
Paradigm},
year = {2023},
pages = {1429-1430},
}
Poster: Hoarseness among university professors and how it can influence students’ listening impression: an audio-visual immersive VR study

For university students, following a lecture can be challenging when room acoustic conditions are poor or when their professor suffers from a voice disorder. Related to the high vocal demands of teaching, university professors develop voice disorders quite frequently. The key symptom is hoarseness. The aim of this study is to investigate the effect of hoarseness on university students’ subjective listening effort and listening impression using audio-visual immersive virtual reality (VR) including a real-time room simulation of a typical seminar room. Equipped with a head-mounted display, participants are immersed in the virtual seminar room, with typical binaural background sounds, where they perform a listening task. This task involves comprehending and recalling information from text, read aloud by a female virtual professor positioned in front of the seminar room. Texts are presented in two experimental blocks, one of them read aloud in a normal (modal) voice, the other one in a hoarse voice. After each block, participants fill out a questionnaire to evaluate their perceived listening effort and overall listening impression under the respective voice quality, as well as the human-likeliness of and preferences towards the virtual professor. Results are presented and discussed regarding voice quality design for virtual tutors and potential impli-cations for students’ motivation and performance in academic learning spaces.
@InProceedings{Schiller2023Audictive,
author = {Isabel S. Schiller, Lukas Aspöck, Carolin Breuer,
Jonathan Ehret and Andrea Bönsch},
booktitle = {Proceedings of the 1st AUDICTIVE Conference},
title = {Hoarseness among university professors and how it can
influence students’ listening impression: an audio-visual immersive VR
study},
year = {2023},
pages = {134-137},
doi = { 10.18154/RWTH-2023-08885},
}
Does a Talker's Voice Quality Affect University Students' Listening Effort in a Virtual Seminar Room?

A university professor's voice quality can either facilitate or impede effective listening in students. In this study, we investigated the effect of hoarseness on university students’ listening effort in seminar rooms using audio-visual virtual reality (VR). During the experiment, participants were immersed in a virtual seminar room with typical background sounds and performed a dual-task paradigm involving listening to and answering questions about short stories, narrated by a female virtual professor, while responding to tactile vibration patterns. In a within-subject design, the professor's voice quality was varied between normal and hoarse. Listening effort was assessed based on performance and response time measures in the dual-task paradigm and participants’ subjective evaluation. It was hypothesized that listening to a hoarse voice leads to higher listening effort. While the analysis is still ongoing, our preliminary results show that listening to the hoarse voice significantly increased perceived listening effort. In contrast, the effect of voice quality was not significant in the dual-task paradigm. These findings indicate that, even if students' performance remains unchanged, listening to hoarse university professors may still require more effort.
@INBOOK{Schiller:977866,
author = {Schiller, Isabel Sarah and Bönsch, Andrea and Ehret,
Jonathan and Breuer, Carolin and Aspöck, Lukas},
title = {{D}oes a talker's voice quality affect university
students' listening effort in a virtual seminar room?},
address = {Turin},
publisher = {European Acoustics Association},
pages = {2813-2816},
year = {2024},
booktitle = {Proceedings of the 10th Convention of
the European Acoustics Association :
Forum Acusticum 2023. Politecnico di
Torino, Torino, Italy, September 11 -
15, 2023 / Editors: Arianna Astolfi,
Francesco Asdrudali, Louena Shtrepi},
month = {Sep},
date = {2023-09-11},
organization = {10. Convention of the European
Acoustics Association : Forum
Acusticum, Turin (Italy), 11 Sep 2023 -
15 Sep 2023},
doi = {10.61782/fa.2023.0320},
}
Localized Latent Updates for Fine-Tuning Vision-Language Models
Although massive pre-trained vision-language models like CLIP show impressive generalization capabilities for many tasks, still it often remains necessary to fine-tune them for improved performance on specific datasets. When doing so, it is desirable that updating the model is fast and that the model does not lose its capabilities on data outside of the dataset, as is often the case with classical fine-tuning approaches. In this work we suggest a lightweight adapter that only updates the models predictions close to seen datapoints. We demonstrate the effectiveness and speed of this relatively simple approach in the context of few-shot learning, where our results both on classes seen and unseen during training are comparable with or improve on the state of the art.
@inproceedings{ibing_localized,
author = {Moritz Ibing and
Isaak Lim and
Leif Kobbelt},
title = {Localized Latent Updates for Fine-Tuning Vision-Language Models},
booktitle = {{IEEE/CVF} Conference on Computer Vision and Pattern Recognition Workshops,
{CVPR} Workshops 2023},
publisher = {{IEEE}},
year = {2023},
}
Poster: Insite Pipeline - A Pipeline Enabling In-Transit Processing for Arbor, NEST and TVB

Simulation of neuronal networks has steadily advanced and now allows for larger and more complex models. However, scaling simulations to such sizes comes with issues and challenges.Especially the amount of data produced, as well as the runtime of the simulation, can be limiting.Often, storing all data on disk is impossible, and users might have to wait for a long time until they can process the data.A standard solution in simulation science is to use in-transit approaches.In-transit implementations allow users to access data while the simulation is still running and do parallel processing outside the simulation.This allows for early insights into the results, early stopping of simulations that are not promising, or even steering of the simulations.Existing in-transit solutions, however, are often complex to integrate into the workflow as they rely on integration into simulators and often use data formats that are complex to handle.This is especially constraining in the context of multi-disciplinary research conducted in the HBP, as such an important feature should be accessible to all users.
To remedy this, we developed Insite, a pipeline that allows easy in-transit access to simulation data of multiscale simulations conducted with TVB, NEST, and Arbor.
@misc{kruger_marcel_2023_7849225,
author = {Krüger, Marcel and
Gerrits, Tim and
Kuhlen, Torsten and
Weyers, Benjamin},
title = {{Insite Pipeline - A Pipeline Enabling In-Transit
Processing for Arbor, NEST and TVB}},
month = mar,
year = 2023,
publisher = {Zenodo},
doi = {10.5281/zenodo.7849225},
url = {https://doi.org/10.5281/zenodo.7849225}
}
Greedy Image Approximation for Artwork Generation via Contiguous Bézier Segments

The automatic creation of digital art has a long history in computer graphics. In this work, we focus on approximating input images to mimic artwork by the artist Kumi Yamashita, as well as the popular scribble art style. Both have in common that the artists create the works by using a single, contiguous thread (Yamashita) or stroke (scribble) that is placed seemingly at random when viewed at close range, but perceived as a tone-mapped picture when viewed from a distance. Our approach takes a rasterized image as input and creates a single, connected path by iteratively sampling a set of candidate segments that extend the current path and greedily selecting the best one. The candidates are sampled according to art style specific constraints, i.e. conforming to continuity constraints in the mathematical sense for the scribble art style. To model the perceptual discrepancy between close and far viewing distances, we minimize the difference between the input image and the image created by rasterizing our path after applying the contrast sensitivity function, which models how human vision blurs images when viewed from a distance. Our approach generalizes to colored images by using one path per color. We evaluate our approach on a wide range of input images and show that it is able to achieve good results for both art styles in grayscale and color.
@inproceedings{nehringwirxel2023greedy,
title={Greedy Image Approximation for Artwork Generation via Contiguous B{\'{e}}zier Segments},
author={Nehring-Wirxel, Julius and Lim, Isaak and Kobbelt, Leif},
booktitle={28th International Symposium on Vision, Modeling, and Visualization, VMV 2023},
year={2023}
}
Point2Vec for Self-Supervised Representation Learning on Point Clouds
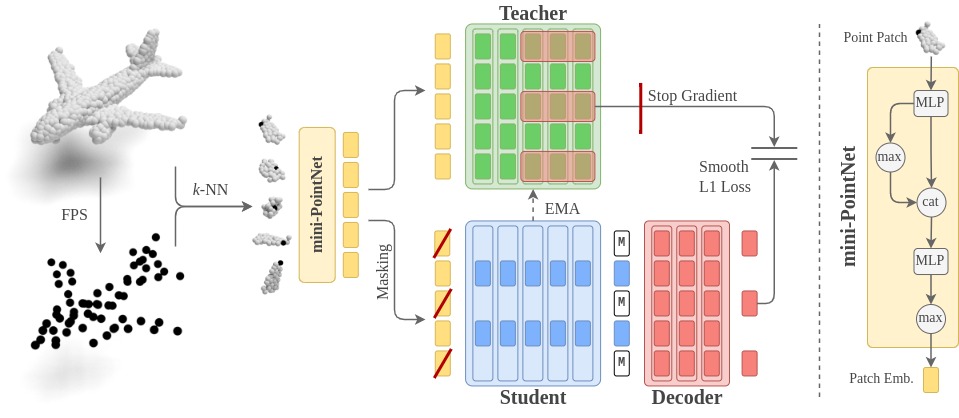
Recently, the self-supervised learning framework data2vec has shown inspiring performance for various modalities using a masked student-teacher approach. However, it remains open whether such a framework generalizes to the unique challenges of 3D point clouds.To answer this question, we extend data2vec to the point cloud domain and report encouraging results on several downstream tasks. In an in-depth analysis, we discover that the leakage of positional information reveals the overall object shape to the student even under heavy masking and thus hampers data2vec to learn strong representations for point clouds. We address this 3D-specific shortcoming by proposing point2vec, which unleashes the full potential of data2vec-like pre-training on point clouds. Our experiments show that point2vec outperforms other self-supervised methods on shape classification and few-shot learning on ModelNet40 and ScanObjectNN, while achieving competitive results on part segmentation on ShapeNetParts. These results suggest that the learned representations are strong and transferable, highlighting point2vec as a promising direction for self-supervised learning of point cloud representations.
@InProceedings{knaebel2023point2vec,
title = {Point2Vec for Self-Supervised Representation Learning on Point Clouds},
author = {Knaebel, Karim and Schult, Jonas and Hermans, Alexander and Leibe, Bastian},
journal = {German Conference on Pattern Recognition (GCPR)},
year = {2023}
}
Clicks as Queries: Interactive Transformer for Multi-instance Segmentation
Transformers have percolated into a multitude of computer vision domains including dense prediction tasks such as instance segmentation and have demonstrated strong performances. Existing transformer based segmentation approaches such as Mask2Former generate pixel-precise object masks automatically given an input image. While these methods are capable of generating high quality masks in general, they have an inherent class bias and are unable to incorporate user inputs to either segment out-of-distribution classes or to correct bad predictions. Hence, we introduce a novel module called Interactive Transformer that enables transformers to predict and refine objects based on user interactions. Subsequently, we use our Interactive Transformer to develop an interactive segmentation network that can generate mask predictions based on user clicks and thereby widen the transformer application domains within computer vision. In addition, the Interactive Transformer can make such interactive segmentation tasks more efficient by (i) imparting the ability to perform multi-instances segmentation, (ii) alleviating the need to re-compute image-level backbone features as done in existing interactive segmentation networks, and (iii) reducing the required number of user interactions by modeling a common background representation. Our transformer-based architecture outperforms the state-of-the-art interactive segmentation networks on multiple benchmark datasets.
@inproceedings{RanaMahadevan23cvprw,
title={Clicks as Queries: Interactive Transformer for Multi-instance Segmentation},
author={Rana, Amit and Mahadevan, Sabarinath and Alexander Hermans and Leibe, Bastian},
booktitle={CVPRW},
year={2023}
}
UGainS: Uncertainty Guided Anomaly Segmentation

A single unexpected object on the road can cause an accident or may lead to injuries. To prevent this, we need a reliable mechanism for finding anomalous objects on the road. This task, called anomaly segmentation, can be a stepping stone to safe and reliable autonomous driving. Current approaches tackle anomaly segmentation by assigning an anomaly score to each pixel and by grouping anomalous regions using simple heuristics. However, pixel grouping is a limiting factor when it comes to evaluating the segmentation performance of individual anomalous objects. To address the issue of grouping multiple anomaly instances into one, we propose an approach that produces accurate anomaly instance masks. Our approach centers on an out-of-distribution segmentation model for identifying uncertain regions and a strong generalist segmentation model for anomaly instances segmentation. We investigate ways to use uncertain regions to guide such a segmentation model to perform segmentation of anomalous instances. By incorporating strong object priors from a generalist model we additionally improve the per-pixel anomaly segmentation performance. Our approach outperforms current pixel-level anomaly segmentation methods, achieving an AP of 80.08% and 88.98% on the Fishyscapes Lost and Found and the RoadAnomaly validation sets respectively.
```
@inproceedings{nekrasov2023ugains,
title = {{UGainS: Uncertainty Guided Anomaly Instance Segmentation}},
author = {Nekrasov, Alexey and Hermans, Alexander and Kuhnert, Lars and Leibe, Bastian},
booktitle = {GCPR},
year = {2023}
}
```
Modeling the Droplet Impact on the Substrate with Surface Preparation in Thermal Spraying with SPH
The properties of thermally sprayed coatings depend heavily on their microstructure. The microstructure is determined by the dynamics of the impact of the droplets on the substrate surface and the subsequent overlapping of the previously solidified and deformed droplets. Substrate preparation prior to spraying ensures strong adhesion of the coating. This includes roughening and preheating of the substrate surface. In the present study, the smoothed particle hydrodynamics (SPH) method is used to model the Al2O3 impact on a preheated substrate and a roughened substrate surface. A semi-implicit enthalpy–porosity method is applied to simulate the solidification process in the mushy zone. In addition, an implicit correction for SPH simulations is used to improve the performance and stability of the simulation. To investigate the dynamics of heat transfer in the contact between the surface and the droplet, the discretization of the substrate is also taken into account. The results show that the studied substrate surface conditions affect the splat morphology and the solidification process. Subsequently, the simulation of multiple droplets for coating formation is also performed and analyzed.
@Article{BHJ+23,
author = {Kirsten Bobzin and Hendrik Heinemann and Kevin Jasutyn and Stefan Rhys Jeske and Jan Bender and Sergej Warkentin and Oleg Mokrov and Rahul Sharma and Uwe Reisgen},
journal = {Journal of Thermal Spray Technology},
title = {Modeling the Droplet Impact on the Substrate with Surface Preparation in Thermal Spraying with SPH},
year = {2023},
month = {jan},
doi = {10.1007/s11666-023-01534-0},
}
Previous Year (2022)
