
Publications
Parametrization Quantization with Free Boundaries for Trimmed Quad Meshing

The generation of quad meshes based on surface parametrization techniques has proven to be a versatile approach. These techniques quantize an initial seamless parametrization so as to obtain an integer grid map implying a pure quad mesh. State-of-the-art methods following this approach have to assume that the surface to be meshed either has no boundary, or has a boundary which the resulting mesh is supposed to be aligned to. In a variety of applications this is not desirable and non-boundary-aligned meshes or grid-parametrizations are preferred. We thus present a technique to robustly generate integer grid maps which are either boundary-aligned, non-boundary-aligned, or partially boundary-aligned, just as required by different applications. We thereby generalize previous work to this broader setting. This enables the reliable generation of trimmed quad meshes with partial elements along the boundary, preferable in various scenarios, from tiled texturing over design and modeling to fabrication and architecture, due to fewer constraints and hence higher overall mesh quality and other benefits in terms of aesthetics and flexibility.
@article{Lyon:2019:TrimmedQuadMeshing,
author = "Lyon, Max and Campen, Marcel and Bommes, David and Kobbelt, Leif",
title = "Parametrization Quantization with Free Boundaries for Trimmed Quad Meshing",
journal = "ACM Transactions on Graphics",
volume = 38,
number = 4,
year = 2019
}
FEELVOS: Fast End-to-End Embedding Learning for Video Object Segmentation
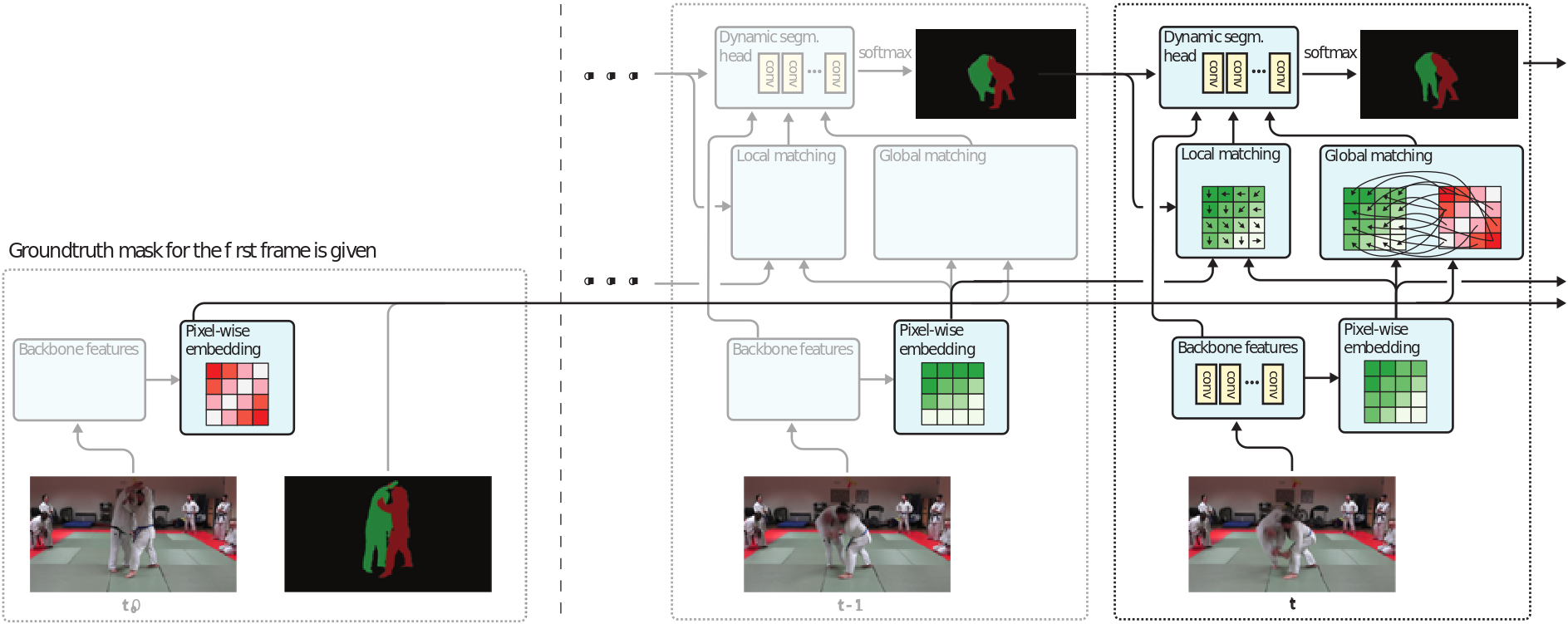
Many of the recent successful methods for video object segmentation (VOS) are overly complicated, heavily rely on fine-tuning on the first frame, and/or are slow, and are hence of limited practical use. In this work, we propose FEELVOS as a simple and fast method which does not rely on fine-tuning. In order to segment a video, for each frame FEELVOS uses a semantic pixel-wise embedding together with a global and a local matching mechanism to transfer information from the first frame and from the previous frame of the video to the current frame. In contrast to previous work, our embedding is only used as an internal guidance of a convolutional network. Our novel dynamic segmentation head allows us to train the network, including the embedding, end-to-end for the multiple object segmentation task with a cross entropy loss. We achieve a new state of the art in video object segmentation without fine-tuning with a J&F measure of 71.5% on the DAVIS 2017 validation set. We make our code and models available at https://github.com/tensorflow/models/tree/master/research/feelvos.
@inproceedings{Voigtlaender19CVPR,
title={{FEELVOS}: Fast End-to-End Embedding Learning for Video Object Segmentation},
author={Paul Voigtlaender and Yuning Chai and Florian Schroff and Hartwig Adam and Bastian Leibe and Liang-Chieh Chen},
booktitle={CVPR},
year={2019}
}
MOTS: Multi-Object Tracking and Segmentation

This paper extends the popular task of multi-object tracking to multi-object tracking and segmentation (MOTS). Towards this goal, we create dense pixel-level annotations for two existing tracking datasets using a semi-automatic annotation procedure. Our new annotations comprise 65,213 pixel masks for 977 distinct objects (cars and pedestrians) in 10,870 video frames. For evaluation, we extend existing multi-object tracking metrics to this new task. Moreover, we propose a new baseline method which jointly addresses detection, tracking, and segmentation with a single convolutional network. We demonstrate the value of our datasets by achieving improvements in performance when training on MOTS annotations. We believe that our datasets, metrics and baseline will become a valuable resource towards developing multi-object tracking approaches that go beyond 2D bounding boxes. We make our annotations, code, and models available at https://www.vision.rwth-aachen.de/page/mots.
@inproceedings{Voigtlaender19CVPR_MOTS,
author = {Paul Voigtlaender and Michael Krause and Aljo\u{s}a O\u{s}ep and Jonathon Luiten and Berin Balachandar Gnana Sekar and Andreas Geiger and Bastian Leibe},
title = {{MOTS}: Multi-Object Tracking and Segmentation},
booktitle = {CVPR},
year = {2019},
}
Interlinked SPH Pressure Solvers for Strong Fluid-Rigid Coupling

We present a strong fluid-rigid coupling for SPH fluids and rigid bodies with particle-sampled surfaces. The approach interlinks the iterative pressure update at fluid particles with a second SPH solver that computes artificial pressure at rigid body particles. The introduced SPH rigid body solver models rigid-rigid contacts as artificial density deviations at rigid body particles. The corresponding pressure is iteratively computed by solving a global formulation which is particularly useful for large numbers of rigid-rigid contacts. Compared to previous SPH coupling methods, the proposed concept stabilizes the fluid-rigid interface handling. It significantly reduces the computation times of SPH fluid simulations by enabling larger time steps. Performance gain factors of up to 58 compared to previous methods are presented. We illustrate the flexibility of the presented fluid-rigid coupling by integrating it into DFSPH, IISPH and a recent SPH solver for highly viscous fluids. We further show its applicability to a recent SPH solver for elastic objects. Large scenarios with up to 90M particles of various interacting materials and complex contact geometries with up to 90k rigid-rigid contacts are shown. We demonstrate the competitiveness of our proposed rigid body solver by comparing it to Bullet.
@article{ Gissler2019,
author= {Christoph Gissler and Andreas Peer and Stefan Band and Jan Bender and Matthias Teschner},
title= {Interlinked SPH Pressure Solvers for Strong Fluid-Rigid Coupling},
year= {2018},
journal= {ACM Trans. Graph.},
publisher= {ACM},
issue_date = {January 2019},
volume = {38},
number = {1},
month = jan,
year = {2019},
issn = {0730-0301},
pages = {5:1--5:13},
articleno = {5},
numpages = {13},
url = {http://doi.acm.org/10.1145/3284980},
doi = {10.1145/3284980},
address = {New York, NY, USA},
}
Distortion-Minimizing Injective Maps Between Surfaces
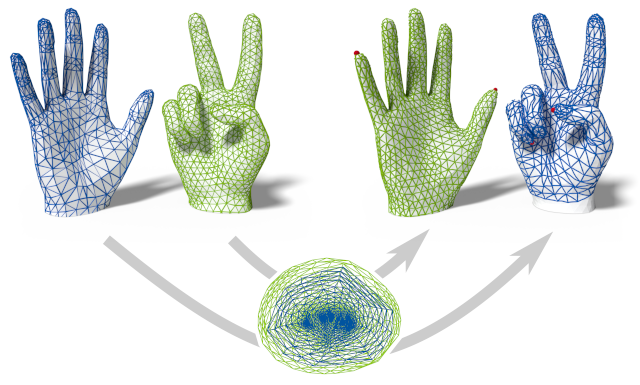
The problem of discrete surface parametrization, i.e. mapping a mesh to a planar domain, has been investigated extensively. We address the more general problem of mapping between surfaces. In particular, we provide a formulation that yields a map between two disk-topology meshes, which is continuous and injective by construction and which locally minimizes intrinsic distortion. A common approach is to express such a map as the composition of two maps via a simple intermediate domain such as the plane, and to independently optimize the individual maps. However, even if both individual maps are of minimal distortion, there is potentially high distortion in the composed map. In contrast to many previous works, we minimize distortion in an end-to-end manner, directly optimizing the quality of the composed map. This setting poses additional challenges due to the discrete nature of both the source and the target domain. We propose a formulation that, despite the combinatorial aspects of the problem, allows for a purely continuous optimization. Further, our approach addresses the non-smooth nature of discrete distortion measures in this context which hinders straightforward application of off-the-shelf optimization techniques. We demonstrate that, despite the challenges inherent to the more involved setting, discrete surface-to-surface maps can be optimized effectively.
@article{schmidt2019distortion,
author = {Schmidt, Patrick and Born, Janis and Campen, Marcel and Kobbelt, Leif},
title = {Distortion-Minimizing Injective Maps Between Surfaces},
journal = {ACM Transactions on Graphics},
issue_date = {November 2019},
volume = {38},
number = {6},
month = nov,
year = {2019},
articleno = {156},
url = {https://doi.org/10.1145/3355089.3356519},
doi = {10.1145/3355089.3356519},
publisher = {ACM},
address = {New York, NY, USA},
}
AlignNet-3D: Fast Point Cloud Registration of Partially Observed Objects

Methods tackling multi-object tracking need to estimate the number of targets in the sensing area as well as to estimate their continuous state. While the majority of existing methods focus on data association, precise state (3D pose) estimation is often only coarsely estimated by approximating targets with centroids or (3D) bounding boxes. However, in automotive scenarios, motion perception of surrounding agents is critical and inaccuracies in the vehicle close-range can have catastrophic consequences. In this work, we focus on precise 3D track state estimation and propose a learning-based approach for object-centric relative motion estimation of partially observed objects. Instead of approximating targets with their centroids, our approach is capable of utilizing noisy 3D point segments of objects to estimate their motion. To that end, we propose a simple, yet effective and efficient network, AlignNet-3D, that learns to align point clouds. Our evaluation on two different datasets demonstrates that our method outperforms computationally expensive, global 3D registration methods while being significantly more efficient.
@inproceedings{Gross193DV,
title = {AlignNet-3D: Fast Point Cloud Registration of Partially Observed Objects},
author = {Johannes Gro\ss and Aljo\v{s}a O\v{s}ep and Bastian Leibe},
booktitle = {International Conference on 3D Vision {(3DV)}},
year = {2019}
}
String-Based Synthesis of Structured Shapes

We propose a novel method to synthesize geometric models from a given class of context-aware structured shapes such as buildings and other man-made objects. Our central idea is to leverage powerful machine learning methods from the area of natural language processing for this task. To this end, we propose a technique that maps shapes to strings and vice versa, through an intermediate shape graph representation. We then convert procedurally generated shape repositories into text databases that in turn can be used to train a variational autoencoder which enables higher level shape manipulation and synthesis like, e.g., interpolation and sampling via its continuous latent space.
@article{Kalojanov2019,
journal = {Computer Graphics Forum},
title = {{String-Based Synthesis of Structured Shapes}},
author = {Javor Kalojanov and Isaak Lim and Niloy Mitra and Leif Kobbelt},
pages = {027-036},
volume= {38},
number= {2},
year = {2019},
note = {\URL{https://diglib.eg.org/bitstream/handle/10.1111/cgf13616/v38i2pp027-036.pdf}},
DOI = {10.1111/cgf.13616},
}
Large-Scale Object Mining for Object Discovery from Unlabeled Video
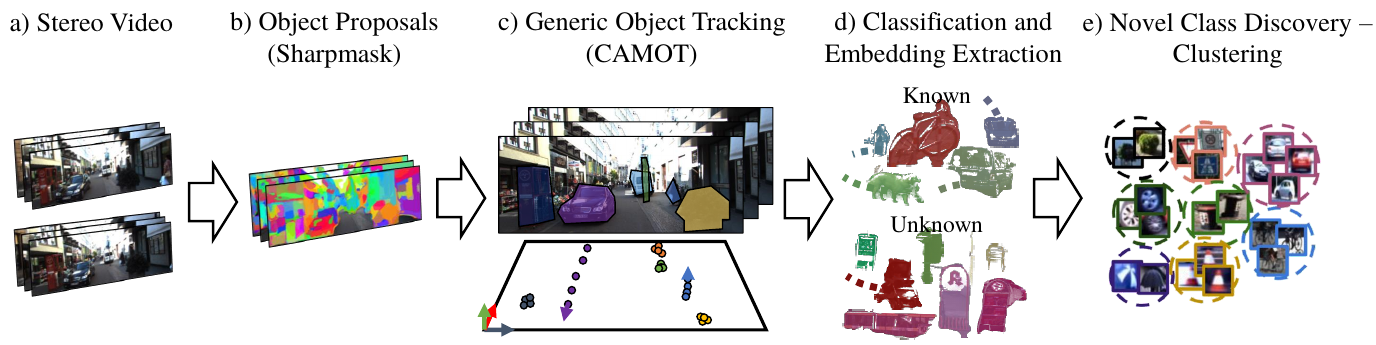
This paper addresses the problem of object discovery from unlabeled driving videos captured in a realistic automotive setting. Identifying recurring object categories in such raw video streams is a very challenging problem. Not only do object candidates first have to be localized in the input images, but many interesting object categories occur relatively infrequently. Object discovery will therefore have to deal with the difficulties of operating in the long tail of the object distribution. We demonstrate the feasibility of performing fully automatic object discovery in such a setting by mining object tracks using a generic object tracker. In order to facilitate further research in object discovery, we will release a collection of more than 360'000 automatically mined object tracks from 10+ hours of video data (560'000 frames). We use this dataset to evaluate the suitability of different feature representations and clustering strategies for object discovery.
@article{Osep19ICRA,
author = {O\v{s}ep, Aljo\v{s}a and Voigtlaender, Paul and Luiten, Jonathon and Breuers, Stefan and Leibe, Bastian},
title = {Large-Scale Object Mining for Object Discovery from Unlabeled Video},
journal = {ICRA},
year = {2019}
}
4D Generic Video Object Proposals

Many high-level video understanding methods require input in the form of object proposals. Currently, such proposals are predominantly generated with the help of networks that were trained for detecting and segmenting a set of known object classes, which limits their applicability to cases where all objects of interest are represented in the training set. This is a restriction for automotive scenarios, where unknown objects can frequently occur. We propose an approach that can reliably extract spatio-temporal object proposals for both known and unknown object categories from stereo video. Our 4D Generic Video Tubes (4D-GVT) method leverages motion cues, stereo data, and object instance segmentation to compute a compact set of video-object proposals that precisely localizes object candidates and their contours in 3D space and time. We show that given only a small amount of labeled data, our 4D-GVT proposal generator generalizes well to real-world scenarios, in which unknown categories appear. It outperforms other approaches that try to detect as many objects as possible by increasing the number of classes in the training set to several thousand.
@inproceedings{Osep19ICRA,
author = {O\v{s}ep, Aljo\v{s}a and Voigtlaender, Paul and Weber, Mark and Luiten, Jonathon and Leibe, Bastian},
title = {4D Generic Video Object Proposals},
booktitle = {ICRA},
year = {2020}
}
Turbulent Micropolar SPH Fluids with Foam
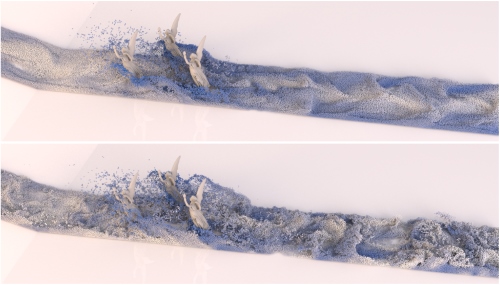
In this paper we introduce a novel micropolar material model for the simulation of turbulent inviscid fluids. The governing equations are solved by using the concept of Smoothed Particle Hydrodynamics (SPH). As already investigated in previous works, SPH fluid simulations suffer from numerical diffusion which leads to a lower vorticity, a loss in turbulent details and finally in less realistic results. To solve this problem we propose a micropolar fluid model. The micropolar fluid model is a generalization of the classical Navier-Stokes equations, which are typically used in computer graphics to simulate fluids. In contrast to the classical Navier-Stokes model, micropolar fluids have a microstructure and therefore consider the rotational motion of fluid particles. In addition to the linear velocity field these fluids also have a field of microrotation which represents existing vortices and provides a source for new ones. However, classical micropolar materials are viscous and the translational and the rotational motion are coupled in a dissipative way. Since our goal is to simulate turbulent fluids, we introduce a novel modified micropolar material for inviscid fluids with a non-dissipative coupling. Our model can generate realistic turbulences, is linear and angular momentum conserving, can be easily integrated in existing SPH simulation methods and its computational overhead is negligible. Another important visual feature of turbulent liquids is foam. Therefore, we present a post-processing method which considers microrotation in the foam particle generation. It works completely automatic and requires only one user-defined parameter to control the amount of foam.
@Article{BKKW19,
author = {Bender, Jan and Koschier, Dan and Kugelstadt, Tassilo and Weiler, Marcel},
title = {Turbulent Micropolar SPH Fluids with Foam},
journal = {IEEE Transactions on Visualization and Computer Graphics},
year = {2019},
publisher = {IEEE},
volume={25},
number={6},
pages={2284-2295},
doi={10.1109/TVCG.2018.2832080},
ISSN={1077-2626},
month={June},
}
Voxel-Based Edge Bundling Trough Direction-Aware Kernel Smoothing
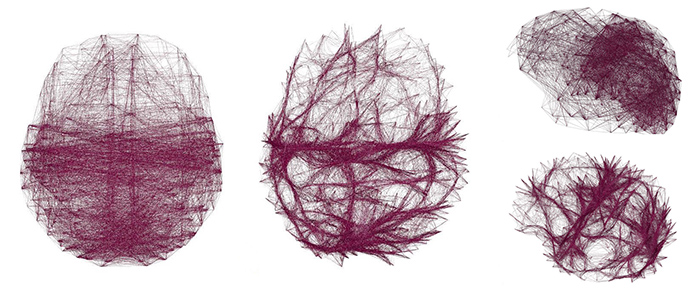
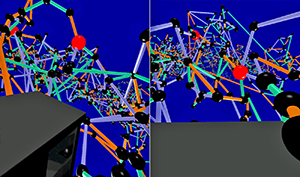
Relational data with a spatial embedding and depicted as node-link diagram is very common, e.g., in neuroscience, and edge bundling is one way to increase its readability or reveal hidden structures. This article presents a 3D extension to kernel density estimation-based edge bundling that is meant to be used in an interactive immersive analysis setting. This extension adds awareness of the edges’ direction when using kernel smoothing and thus implicitly supports both directed and undirected graphs. The method generates explicit bundles of edges, which can be analyzed and visualized individually and as sufficient as possible for a given application context, while it scales linearly with the input size.
@article{ZIELASKO2019,
title = "Voxel-based edge bundling through direction-aware kernel smoothing",
journal = "Computers & Graphics",
volume = "83",
pages = "87 - 96",
year = "2019",
issn = "0097-8493",
doi = "https://doi.org/10.1016/j.cag.2019.06.008",
url = "http://www.sciencedirect.com/science/article/pii/S0097849319301025",
author = "Daniel Zielasko and Xiaoqing Zhao and Ali Can Demiralp and Torsten W. Kuhlen and Benjamin Weyers"}
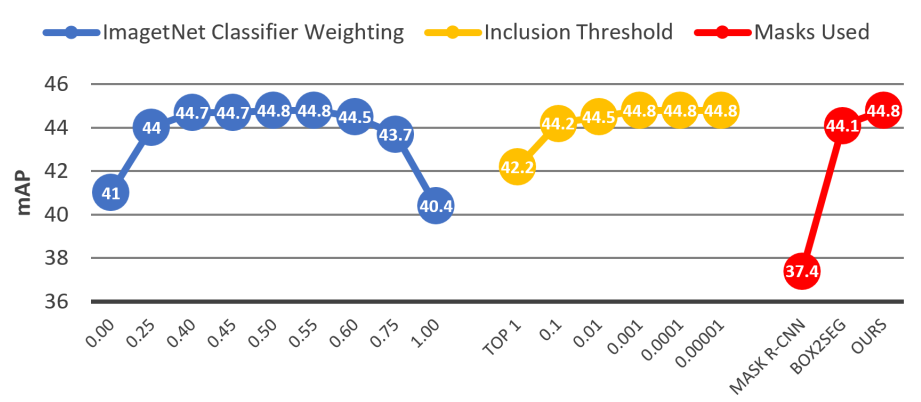
Combining PReMVOS with Box-Level Tracking for the 2019 DAVIS Challenge
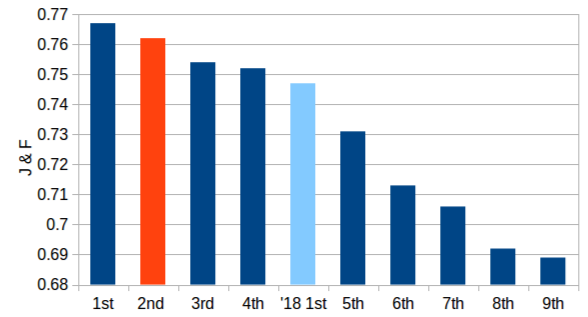
Recently a number of different approaches have beenproposed for tackling the task of Video Object Segmentation(VOS). In this paper we compare and contrast two particu-larly powerful methods, PReMVOS (Proposal-generation,Refinement and Merging for VOS), and BoLTVOS (Box-Level Tracking for VOS). PReMVOS follows a tracking-by-detection framework in which a set of object proposals aregenerated per frame and are then linked into tracks overtime by optical flow and appearance similarity cues. In con-trast, BoLTVOS uses a Siamese architecture to directly de-tect the object to be tracked based on its similarity to thegiven first-frame object. Although BoLTVOS can outper-form PReMVOS when the number of objects to be trackedis small, it does not scale as well to tracking multiple ob-jects. Finally we develop a model which combines bothBoLTVOS and PReMVOS and achieves aJ&Fscore of76.2% on the DAVIS 2017 test-challenge benchmark, re-sulting in a 2nd place finish in the 2019 DAVIS challengeon semi-supervised VOS.
@article{LuitenDAVIS2019,
title={Combining PReMVOS with Box-Level Tracking for the 2019 DAVIS Challenge},
author={Luiten, Jonathon and Voigtlaender, Paul and Leibe, Bastian},
booktitle = {The 2019 DAVIS Challenge on Video Object Segmentation - CVPR Workshops},
year = {2019}
}
A Convolutional Decoder for Point Clouds using Adaptive Instance Normalization
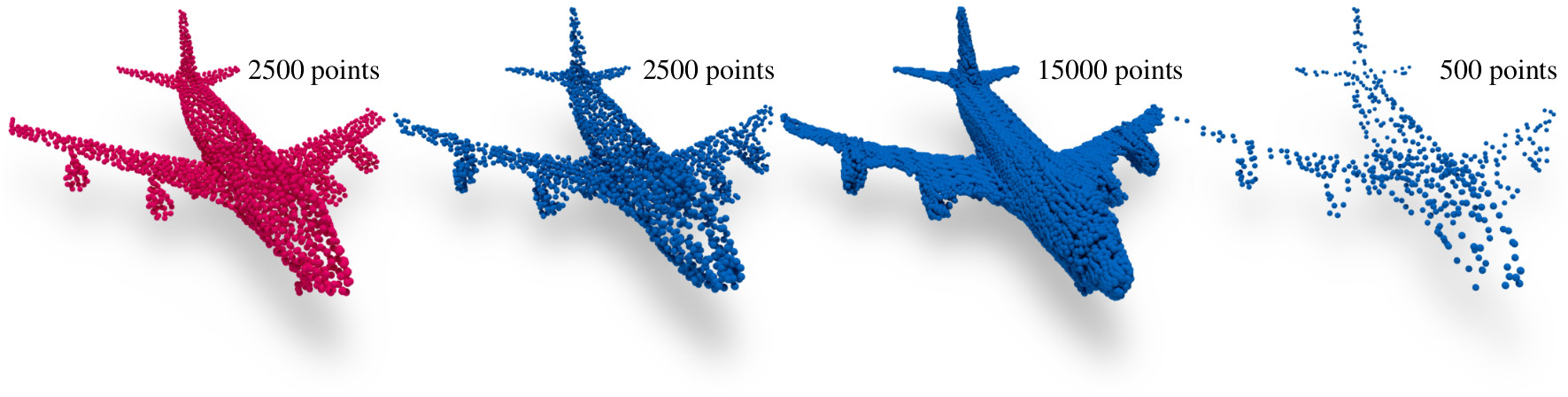
Automatic synthesis of high quality 3D shapes is an ongoing and challenging area of research. While several data-driven methods have been proposed that make use of neural networks to generate 3D shapes, none of them reach the level of quality that deep learning synthesis approaches for images provide. In this work we present a method for a convolutional point cloud decoder/generator that makes use of recent advances in the domain of image synthesis. Namely, we use Adaptive Instance Normalization and offer an intuition on why it can improve training. Furthermore, we propose extensions to the minimization of the commonly used Chamfer distance for auto-encoding point clouds. In addition, we show that careful sampling is important both for the input geometry and in our point cloud generation process to improve results. The results are evaluated in an auto-encoding setup to offer both qualitative and quantitative analysis. The proposed decoder is validated by an extensive ablation study and is able to outperform current state of the art results in a number of experiments. We show the applicability of our method in the fields of point cloud upsampling, single view reconstruction, and shape synthesis.
@article{Lim:2019:ConvolutionalDecoder,
author = "Lim, Isaak and Ibing, Moritz and Kobbelt, Leif",
title = "A Convolutional Decoder for Point Clouds using Adaptive Instance Normalization",
journal = "Computer Graphics Forum",
volume = 38,
number = 5,
year = 2019
}
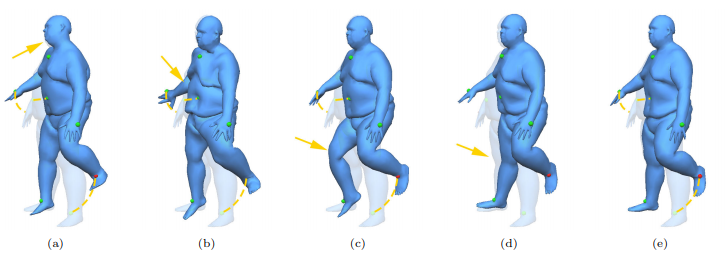
Visual Person Understanding through Multi-Task and Multi-Dataset Learning
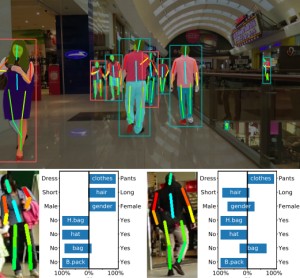
We address the problem of learning a single model for person re-identification, attribute classification, body part segmentation, and pose estimation. With predictions for these tasks we gain a more holistic understanding of persons, which is valuable for many applications. This is a classical multi-task learning problem. However, no dataset exists that these tasks could be jointly learned from. Hence several datasets need to be combined during training, which in other contexts has often led to reduced performance in the past. We extensively evaluate how the different task and datasets influence each other and how different degrees of parameter sharing between the tasks affect performance. Our final model matches or outperforms its single-task counterparts without creating significant computational overhead, rendering it highly interesting for resource-constrained scenarios such as mobile robotics.
@inproceedings{Pfeiffer19GCPR,
title = {Visual Person Understanding Through Multi-task and Multi-dataset Learning},
author = {Kilian Pfeiffer and Alexander Hermans and Istv\'{a}n S\'{a}r\'{a}ndi and Mark Weber and Bastian Leibe},
booktitle = {German Conference on Pattern Recognition (GCPR)},
date = {2019}
}
Smoothed Particle Hydrodynamics for Physically-Based Simulation of Fluids and Solids

Graphics research on Smoothed Particle Hydrodynamics (SPH) has produced fantastic visual results that are unique across the board of research communities concerned with SPH simulations. Generally, the SPH formalism serves as a spatial discretization technique, commonly used for the numerical simulation of continuum mechanical problems such as the simulation of fluids, highly viscous materials, and deformable solids. Recent advances in the field have made it possible to efficiently simulate massive scenes with highly complex boundary geometries on a single PC. Moreover, novel techniques allow to robustly handle interactions among various materials. As of today, graphics-inspired pressure solvers, neighborhood search algorithms, boundary formulations, and other contributions often serve as core components in commercial software for animation purposes as well as in computer-aided engineering software.
This tutorial covers various aspects of SPH simulations. Governing equations for mechanical phenomena and their SPH discretizations are discussed. Concepts and implementations of core components such as neighborhood search algorithms, pressure solvers, and boundary handling techniques are presented. Implementation hints for the realization of SPH solvers for fluids, elastic solids, and rigid bodies are given. The tutorial combines the introduction of theoretical concepts with the presentation of actual implementations.
@inproceedings {KBST19,
title = "Smoothed Particle Hydrodynamics for Physically-Based Simulation of Fluids and Solids",
author = "Dan Koschier and Jan Bender and Barbara Solenthaler and Matthias Teschner",
year = "2019",
booktitle = "EUROGRAPHICS 2019 Tutorials",
publisher = "Eurographics Association"
}
ACAP: Sparse Data Driven Mesh Deformation
Example-based mesh deformation methods are powerful tools for realistic shape editing. However, existing techniques typically combine all the example deformation modes, which can lead to overfitting, i.e. using an overly complicated model to explain the user-specified deformation. This leads to implausible or unstable deformation results, including unexpected global changes outside the region of interest. To address this fundamental limitation, we propose a sparse blending method that automatically selects a smaller number of deformation modes to compactly describe the desired deformation. This along with a suitably chosen deformation basis including spatially localized deformation modes leads to significant advantages, including more meaningful, reliable, and efficient deformations because fewer and localized deformation modes are applied. To cope with large rotations, we develop a simple but effective representation based on polar decomposition of deformation gradients, which resolves the ambiguity of large global rotations using an as-consistent-as-possible global optimization. This simple representation has a closed form solution for derivatives, making it efficient for our sparse localized representation and thus ensuring interactive performance. Experimental results show that our method outperforms state-of-the-art data-driven mesh deformation methods, for both quality of results and efficiency.
@article{gao2019sparse,
title={Sparse data driven mesh deformation},
author={Gao, Lin and Lai, Yu-Kun and Yang, Jie and Ling-Xiao, Zhang and Xia, Shihong and Kobbelt, Leif},
journal={IEEE transactions on visualization and computer graphics},
year={2019},
publisher={IEEE}
}
Feature Tracking Utilizing a Maximum-Weight Independent Set Problem
Tracking the temporal evolution of features in time-varying data remains a combinatorially challenging problem. A recent method models event detection as a maximum-weight independent set problem on a graph representation of all possible explanations [35]. However, optimally solving this problem is NP-hard in the general case. Following the approach by Schnorr et al., we propose a new algorithm for event detection. Our algorithm exploits the modelspecific structure of the independent set problem. Specifically, we show how to traverse potential explanations in such a way that a greedy assignment provides reliably good results. We demonstrate the effectiveness of our approach on synthetic and simulation data sets, the former of which include ground-truth tracking information which enable a quantitative evaluation. Our results are within 1% of the theoretical optimum and comparable to an approximate solution provided by a state-of-the-art optimization package. At the same time, our algorithm is significantly faster.
@InProceedings{Schnorr2019,
author = {Andrea Schnorr, Dirk Norbert Helmrich, Hank Childs, Torsten Wolfgang Kuhlen, Bernd Hentschel},
title = {{Feature Tracking Utilizing a Maximum-Weight Independent Set Problem}},
booktitle = {9th IEEE Symposium on Large Data Analysis and Visualization},
year = {2019}
}
Volume Maps: An Implicit Boundary Representation for SPH

In this paper, we present a novel method for the robust handling of static and dynamic rigid boundaries in Smoothed Particle Hydrodynamics (SPH) simulations. We build upon the ideas of the density maps approach which has been introduced recently by Koschier and Bender. They precompute the density contributions of solid boundaries and store them on a spatial grid which can be efficiently queried during runtime. This alleviates the problems of commonly used boundary particles, like bumpy surfaces and inaccurate pressure forces near boundaries. Our method is based on a similar concept but we precompute the volume contribution of the boundary geometry and store it on a grid. This maintains all benefits of density maps but offers a variety of advantages which are demonstrated in several experiments. Firstly, in contrast to the density maps method we can compute derivatives in the standard SPH manner by differentiating the kernel function. This results in smooth pressure forces, even for lower map resolutions, such that precomputation times and memory requirements are reduced by more than two orders of magnitude compared to density maps. Furthermore, this directly fits into the SPH concept so that volume maps can be seamlessly combined with existing SPH methods. Finally, the kernel function is not baked into the map such that the same volume map can be used with different kernels. This is especially useful when we want to incorporate common surface tension or viscosity methods that use different kernels than the fluid simulation.
@inproceedings{Bender2019,
author = {Jan Bender and Tassilo Kugelstadt and Marcel Weiler and Dan Koschier},
title = {Volume Maps: An Implicit Boundary Representation for SPH},
booktitle = {Proceedings of ACM SIGGRAPH Conference on Motion, Interaction and Games},
series = {MIG '19},
year = {2019},
publisher = {ACM}
}
Video Instance Segmentation 2019: A winning approach for combined Detection, Segmentation, Classification and Tracking.
Video Instance Segmentation (VIS) is the task of localizing all objects in a video, segmenting them, tracking them throughout the video and classifying them into a set of predefined classes. In this work, divide VIS into these four parts: detection, segmentation, tracking and classification. We then develop algorithms for performing each of these four sub tasks individually, and combine these into a complete solution for VIS. Our solution is an adaptation of UnOVOST, the current best performing algorithm for Unsupervised Video Object Segmentation, to this VIS task. We benchmark our algorithm on the 2019 YouTube-VIS Challenge, where we obtain first place with an mAP score of 46.7%.
@inproceedings{Luiten19ICCVW_Video,
author = {Jonathon Luiten and Philip Torr and Bastian Leibe},
title = {{Video Instance Segmentation 2019: A winning approach for combined Detection, Segmentation, Classification and Tracking.}},
booktitle = {The 2nd Large-scale Video Object Segmentation Challenge: International Conference on Computer Vision Workshop (ICCVW)},
year = {2019},
}
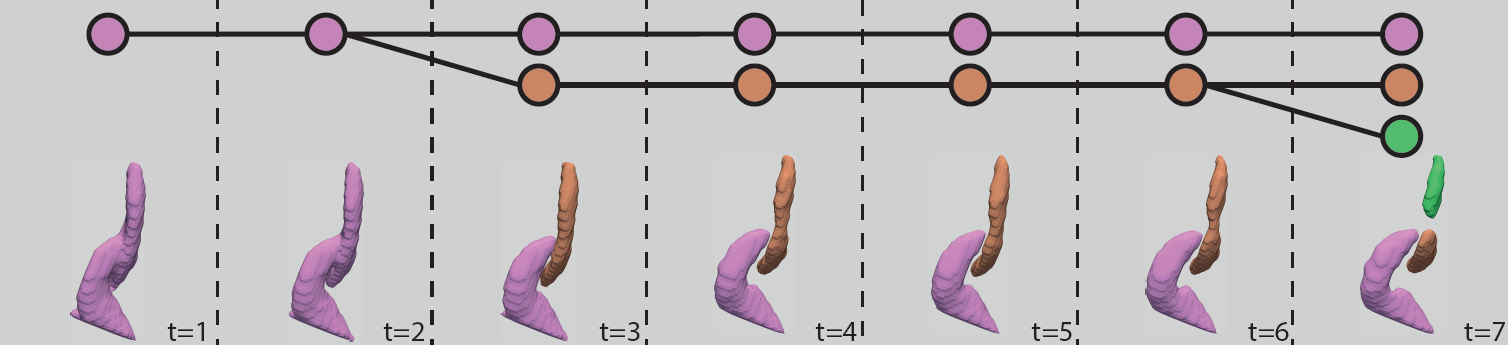
UnOVOST: Unsupervised Offline Video Object Segmentation and Tracking for the 2019 Unsupervised DAVIS Challenge

We address Unsupervised Video Object Segmentation (UVOS), the task of automatically generating accurate pixelmasks for salient objects in a video sequence and of track-ing these objects consistently through time, without any in-formation about which objects should be tracked. Towardssolving this task, we present UnOVOST (Unsupervised Of-fline Video Object Segmentation and Tracking) as a simpleand generic algorithm which is able to track a large varietyof objects. This algorithm hierarchically builds up tracksin five stages. First, object proposal masks are generatedusing Mask R-CNN. Second, masks are sub-selected andclipped so that they do not overlap in the image domain.Third, tracklets are generated by grouping object propos-als that are strongly temporally consistent with each otherunder optical flow warping. Fourth, tracklets are mergedinto long-term consistent object tracks using their temporalconsistency and an appearance similarity metric calculatedusing an object re-identification network. Finally, the mostsalient object tracks are selected based on temporal tracklength and detection confidence scores. We evaluate ourapproach on the DAVIS 2017 Unsupervised dataset and ob-tain state-of-the-art performance with a meanJ&Fscoreof 58% on the test-dev benchmark. Our approach furtherachieves first place in the DAVIS 2019 Unsupervised VideoObject Segmentation Challenge with a mean ofJ&Fscoreof 56.4% on the test-challenge benchmark.
@article{ZulfikarLuitenUnOVOST,
title={UnOVOST: Unsupervised Offline Video Object Segmentation and Tracking for the 2019 Unsupervised DAVIS Challenge},
author={Zulfikar, Idil Esen and Luiten, Jonathon and Leibe, Bastian}
booktitle = {The 2019 DAVIS Challenge on Video Object Segmentation - CVPR Workshops},
year = {2019}
}
An Optimized Source Term Formulation for Incompressible SPH

Incompressible SPH (ISPH) is a promising concept for the pressure computation in SPH. It works with large timesteps and the underlying pressure Poisson equation (PPE) can be solved very efficiently. Still, various aspects of current ISPH formulations can be optimized.
This paper discusses issues of the two standard source terms that are typically employed in PPEs, i.e. density invariance (DI) and velocity divergence (VD). We show that the DI source term suffers from significant artificial viscosity, while the VD source term suffers from particle disorder and volume loss.
As a conclusion of these findings, we propose a novel source term handling. A first PPE is solved with the VD source term to compute a divergence-free velocity field with minimized artificial viscosity. To address the resulting volume error and particle disorder, a second PPE is solved to improve the sampling quality. The result of the second PPE is used for a particle shift (PS) only. The divergence-free velocity field - computed from the first PPE - is not changed, but only resampled at the updated particle positions. Thus, the proposed source term handling incorporates velocity divergence and particle shift (VD+PS).
@Article{Cornelis2019,
author = {Cornelis, Jens and Bender, Jan and Gissler, Christoph and Ihmsen, Markus and Teschner, Matthias},
title = {An optimized source term formulation for incompressible SPH},
journal = {The Visual Computer},
year = {2019},
month = {Apr},
volume={35},
number={4},
pages={579--590},
issn = {1432-2315},
day = {20},
doi = {10.1007/s00371-018-1488-8},
url = {https://doi.org/10.1007/s00371-018-1488-8},
}
Form Finding of Stress Adapted Folding as a Lightweight Structure Under Different Load Cases
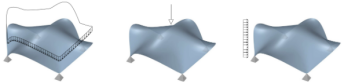
In steel construction, the use of folds is limited to longitudinal folds (e.g. trapezoidal sheets). The efficiency of creases can be increased by aligning the folding pattern to the principal stresses or to their directions. This paper presents a form-finding approach to use the material as homogeneously as possible. In addition to the purely geometric alignment according to the stress directions, it also allows the stress intensity to be taken into account during form-finding. A trajectory mesh of the principle stresses is generated on the basis of which the structure is derived. The relationships between the stress lines distance, progression and stress intensity are discussed and implemented in the approaches of form-finding. Building on this, this paper additionally deals with the question of which load case is the most effective basis for designing the crease pattern when several load cases can act simultaneously.
@article {Musto:2019:2518-6582:1,
title = "Form finding of stress adapted folding as a lightweight structure under different load cases",
journal = "Proceedings of IASS Annual Symposia",
parent_itemid = "infobike://iass/piass",
publishercode ="iass",
year = "2019",
volume = "2019",
number = "13",
publication date ="2019-10-07T00:00:00",
pages = "1-8",
itemtype = "ARTICLE",
issn = "2518-6582",
eissn = "2518-6582",
url = "https://www.ingentaconnect.com/content/iass/piass/2019/00002019/00000013/art00006",
keyword = "lightweight-construction, folding, Mixed-Integer Quadrangulation, principle stress lines",
author = "Musto, Juan and Lyon, Max and Trautz, Martin and Kobbelt, Leif",
abstract = "In steel construction, the use of folds is limited to longitudinal folds (e.g. trapezoidal sheets). The efficiency of creases can be increased by aligning the folding pattern to the principal stresses or to their directions. This paper presents a form-finding approach to use the material
as homogeneously as possible. In addition to the purely geometric alignment according to the stress directions, it also allows the stress intensity to be taken into account during form-finding. A trajectory mesh of the principle stresses is generated on the basis of which the structure is
derived. The relationships between the stress lines distance, progression and stress intensity are discussed and implemented in the approaches of form-finding. Building on this, this paper additionally deals with the question of which load case is the most effective basis for designing
the crease pattern when several load cases can act simultaneously.",
}
Exploring the Combination of PReMVOS, BoLTVOS and UnOVOST for the 2019 YouTube-VOS Challenge
Video Object Segmentation is the task of tracking and segmenting objects in a video given the first-frame mask of objects to be tracked. There have been a number of different successful paradigms for tackling this task, from creating object proposals and linking them in time as in PReMVOS, to detecting objects to be tracked conditioned on the given first-frame as in BoLTVOS, and creating tracklets based on motion consistency before merging these into long-term tracks as in UnOVOST. In this paper we explore how these three different approaches can be combined into a novel Video Object Segmentation algorithm. We evaluate our approach on the 2019 Youtube-VOS challenge where we obtain 6th place with an overall score of 71.5%.
@inproceedings{Luiten19ICCVW_Video,
author = {Jonathon Luiten and Paul Voigtlaender and Bastian Leibe},
title = {{Exploring the Combination of PReMVOS, BoLTVOS and UnOVOST for the 2019 YouTube-VOS Challenge}},
booktitle = {The 2nd Large-scale Video Object Segmentation Challenge: International Conference on Computer Vision Workshop (ICCVW)},
year = {2019},
}
Influence of Directivity on the Perception of Embodied Conversational Agents' Speech

Embodied conversational agents become more and more important in various virtual reality applications, e.g., as peers, trainers or therapists. Besides their appearance and behavior, appropriate speech is required for them to be perceived as human-like and realistic. Additionally to the used voice signal, also its auralization in the immersive virtual environment has to be believable. Therefore, we investigated the effect of adding directivity to the speech sound source. Directivity simulates the orientation dependent auralization with regard to the agent's head orientation. We performed a one-factorial user study with two levels (n=35) to investigate the effect directivity has on the perceived social presence and realism of the agent's voice. Our results do not indicate any significant effects regarding directivity on both variables covered. We account this partly to an overall too low realism of the virtual agent, a not overly social utilized scenario and generally high variance of the examined measures. These results are critically discussed and potential further research questions and study designs are identified.
@inproceedings{Wendt2019,
author = {Wendt, Jonathan and Weyers, Benjamin and Stienen, Jonas and B\"{o}nsch, Andrea and Vorl\"{a}nder, Michael and Kuhlen, Torsten W.},
title = {Influence of Directivity on the Perception of Embodied Conversational Agents' Speech},
booktitle = {Proceedings of the 19th ACM International Conference on Intelligent Virtual Agents},
series = {IVA '19},
year = {2019},
isbn = {978-1-4503-6672-4},
location = {Paris, France},
pages = {130--132},
numpages = {3},
url = {http://doi.acm.org/10.1145/3308532.3329434},
doi = {10.1145/3308532.3329434},
acmid = {3329434},
publisher = {ACM},
address = {New York, NY, USA},
keywords = {directional 3d sound, social presence, virtual acoustics, virtual agents},
}
Passive Haptic Menus for Desk-Based and HMD-Projected Virtual Reality

In this work we evaluate the impact of passive haptic feedback on touch-based menus, given the constraints and possibilities of a seated, desk-based scenario in VR. Therefore, we compare a menu that once is placed on the surface of a desk and once mid-air on a surface in front of the user. The study design is completed by two conditions without passive haptic feedback. In the conducted user study (n = 33) we found effects of passive haptics (present vs- non-present) and menu alignment (desk vs. mid-air) on the task performance and subjective look & feel, however the race between the conditions was close. An overall winner was the mid-air menu with passive haptic feedback, which however raises hardware requirements.
@inproceedings{zielasko2019menu,
title={{Passive Haptic Menus for Desk-Based and HMD-Projected Virtual Reality}},
author={Zielasko, Daniel and Kr{\"u}ger Marcel and Weyers, Benjamin and Kuhlen, Torsten W},
booktitle={Proc. of IEEE VR Workshop on Everyday Virtual Reality},
year={2019}
}
A Non-Stationary Office Desk Substitution for Desk-Based and HMD-Projected Virtual Reality
The ongoing migration of HMDs to the consumer market also allows the integration of immersive environments into analysis workflows that are often bound to an (office) desk. However, a critical factor when considering VR solutions for professional applications is the prevention of cybersickness. In the given scenario the user is usually seated and the surrounding real world environment is very dominant, where the most dominant part is maybe the desk itself. Including this desk in the virtual environment could serve as a resting frame and thus reduce cybersickness next to a lot of further possibilities. In this work, we evaluate the feasibility of a substitution like this in the context of a visual data analysis task involving travel, and measure the impact on cybersickness as well as the general task performance and presence. In the conducted user study (n=52), surprisingly, and partially in contradiction to existing work, we found no significant differences for those core measures between the control condition without a virtual table and the condition containing a virtual table. However, the results also support the inclusion of a virtual table in desk-based use cases.
@inproceedings{zielasko2019travel,
title={{A Non-Stationary Office Desk Substitution for Desk-Based and HMD-Projected Virtual Reality}},
author={Zielasko, Daniel and Weyers, Benjamin and Kuhlen, Torsten W},
booktitle ={Proc. of IEEE VR Workshop on Immersive Sickness Prevention},
year={2019}
}
Evaluation of Omnipresent Virtual Agents Embedded as Temporarily Required Assistants in Immersive Environments

When designing the behavior of embodied, computer-controlled, human-like virtual agents (VA) serving as temporarily required assistants in virtual reality applications, two linked factors have to be considered: the time the VA is visible in the scene, defined as presence time (PT), and the time till the VA is actually available for support on a user’s calling, defined as approaching time (AT).
Complementing a previous research on behaviors with a low VA’s PT, we present the results of a controlled within-subjects study investigating behaviors by which the VA is always visible, i.e., behaviors with a high PT. The two behaviors affecting the AT tested are: following, a design in which the VA is omnipresent and constantly follows the users, and busy, a design in which theVAis self-reliantly spending time nearby the users and approaches them only if explicitly asked for. The results indicate that subjects prefer the following VA, a behavior which also leads to slightly lower execution times compared to busy.
@InProceedings{Boensch2019c,
author = {Andrea B\"{o}nsch and Jan Hoffmann and Jonathan Wendt and Torsten W. Kuhlen},
title = {{Evaluation of Omnipresent Virtual Agents Embedded as Temporarily Required Assistants in Immersive Environments}},
booktitle = {IEEE Virtual Humans and Crowds for Immersive Environments (VHCIE)},
year = {2019},
doi={10.1109/VHCIE.2019.8714726},
month={March}
}
An Empirical Lab Study Investigating If Higher Levels of Immersion Increase the Willingness to Donate

Technological innovations have a growing relevance for charitable donations, as new technologies shape the way we perceive and approach digital media. In a between-subjects study with sixty-one volunteers, we investigated whether a higher degree of immersion for the potential donor can yield more donations for non-governmental organizations. Therefore, we compared the donations given after experiencing a video-based, an augmented-reality-based, or a virtual-reality-based scenery with a virtual agent, representing a war victimized Syrian boy talking about his losses. Our initial results indicate that the immersion has no impact. However, the donor’s perceived innovativeness of the used technology might be an influencing factor.
@InProceedings{Boensch2019b,
author = {Andrea B\"{o}nsch and Alexander Kies and Moritz Jörling and Stefanie Paluch and Torsten W. Kuhlen},
title = {{An Empirical Lab Study Investigating If Higher Levels of Immersion Increase the Willingness to Donatee}},
booktitle = {IEEE Virtual Humans and Crowds for Immersive Environments (VHCIE)},
year = {2019}
pages={1-4},
doi={10.1109/VHCIE.2019.8714622},
month={March}
}
Volumetric Video Capture Using Unsynchronized, Low-Cost Cameras

Volumetric video can be used in virtual and augmented reality applications to show detailed animated performances by human actors. In this paper, we describe a volumetric capture system based on a photogrammetry cage with unsynchronized, low-cost cameras which is able to generate high-quality geometric data for animated avatars. This approach requires, inter alia, a subsequent synchronization of the captured videos.
@Article{Boensch2019a,
author = {Andrea Bönsch, Andrew Feng, Parth Patel and Ari Shapiro},
title = {{Volumetric Video Capture using Unsynchronized, Low-cost Cameras}},
booktitle= {Proceedings of the 14th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2019)},
year = {2019},
volume = {1},
pages = {255--261}
publisher={SciTePress},
organization={INSTICC},
doi={10.5220/0007373202550261},
isbn={978-989-758-354-4}
}
Joint Locomotion with Virtual Agents in Immersive Environments

Many applications in the realm of social virtual reality require reasonable locomotion patterns for their embedded, intelligent virtual agents (VAs). The two main research areas covered in the literature are pure inter-agent-dynamics for crowd simulations and user-agent-dynamics in, e.g., pedestrian scenarios. However, social locomotion, defined as a joint locomotion of a social group consisting of a human user and one to several VAs in the role of accompanying interaction partners, has not been carefully investigated yet. I intend to close this gap by contributing locomotion models for the social group’s VAs. Thereby, I plan to evaluate the effects of the VAs’ locomotion patterns on a user’s perceived degree of immersion, comfort, and social presence.
@InProceedings{Boensch2019d,
author = {Andrea B\"{o}nsch},
title = {Locomotion with Virtual Agents in the Realm of Social Virtual Reality},
booktitle = {Doctoral Consortium at IEEE Virtual Reality Conference 2018},
year = {2019}
}
Beanspruchungsoptimierte Faltungen aus Stahl für selbsttragende Raumfaltwerke
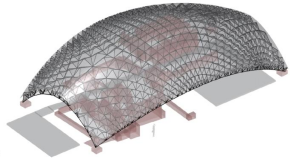
Der Einsatz von Faltungen beschränkt sich im Bauwesen auf Longitudinalfaltungen (Trapezbleche) und regelmäßige Faltungen. Raumfaltwerke und Faltleichtbauplatten, räumlich gekrümmte und dreidimensionale Flächentragwerke sind Desiderate eines Leichtbaus mit Stahlblechen. Raumfaltwerke bestehen vorwiegend aus regelmäßigen Faltmuster, die auf Tesselierung mit Primitivflächen (Drei-und Vierecke) basieren. Um die Effizienz dieser Leichtbaustrukturen zu verbessern, liegt es nahe, statt regelmäßige und auf geometrischen Prinzipien basierende Faltmuster umzusetzen, Faltmuster nach Maßgabe nach Maßgabe der der Beanspruchungen bzw. der Beanspruchungsverteilung anzuwenden. Hierzu ist ein Formfindungsprozess zu entwickeln, der auf der Generierung eines Trajektoriennetzes basiert, das aus dem maßgeblichen Lastfall (formgebenden Lastfall) abgeleitet wird. Der Vergleich des Masseneinsatzes und der Traglast der Faltungen, die auf geometrischer Basis erzeugt wurden mit einer auf Basis des Trajektoriennetzes entwickelten Faltung zeigt die Veränderung der Effizienz .
@article{https://doi.org/10.1002/bate.201900024,
author = {Musto, Juan and Lyon, Max and Trautz, Martin and Kobbelt, Leif},
title = {Beanspruchungsoptimierte Faltungen aus Stahl für selbsttragende Raumfaltwerke},
journal = {Bautechnik},
volume = {96},
number = {12},
pages = {902-911},
keywords = {Leichtbau, Faltungen, Hauptspannungstrajektorien, Mixed-Integer Quadrangulation, lightweight-construction, folgings, principle stress trajectories, mixed-integer quadrangulation, Stahlbau, Leichtbau, Steel construction, lightweight construction},
doi = {https://doi.org/10.1002/bate.201900024},
url = {https://onlinelibrary.wiley.com/doi/abs/10.1002/bate.201900024},
eprint = {https://onlinelibrary.wiley.com/doi/pdf/10.1002/bate.201900024},
abstract = {Abstract Der Einsatz von Faltungen beschränkt sich im Bauwesen auf Longitudinalfaltungen (Trapezbleche) und regelmäßige Faltungen. Raumfaltwerke und Faltleichtbauplatten, räumlich gekrümmte und dreidimensionale Flächentragwerke sind Desiderate eines Leichtbaus mit Stahlblechen. Raumfaltwerke bestehen vorwiegend aus regelmäßigen Faltmustern, die auf Tesselierung mit Primitivflächen (Drei- und Vierecke) basieren. Um die Effizienz dieser Leichtbaustrukturen zu verbessern, liegt es nahe, statt regelmäßige und auf geometrischen Prinzipien basierende Faltmuster umzusetzen, Faltmuster nach Maßgabe der Beanspruchungen bzw. der Beanspruchungsverteilung anzuwenden. Hierzu ist ein Formfindungsprozess zu entwickeln, der auf der Generierung eines Trajektoriennetzes basiert, das aus dem maßgeblichen Lastfall (formgebenden Lastfall) abgeleitet wird. Der Vergleich des Masseneinsatzes und der Traglast der Faltungen, die auf geometrischer Basis erzeugt wurden, mit einer auf Basis des Trajektoriennetzes entwickelten Faltung zeigt die Veränderung der Effizienz.},
year = {2019}
}
Structured Discrete Shape Approximation: Theoretical Complexity and Practical Algorithm
We consider the problem of approximating a two-dimensional shape contour (or curve segment) using discrete assembly systems, which allow to build geometric structures based on limited sets of node and edge types subject to edge length and orientation restrictions. We show that already deciding feasibility of such approximation problems is NP-hard, and remains intractable even for very simple setups. We then devise an algorithmic framework that combines shape sampling with exact cardinality-minimization to obtain good approximations using few components. As a particular application and showcase example, we discuss approximating shape contours using the classical Zometool construction kit and provide promising computational results, demonstrating that our algorithm is capable of obtaining good shape representations within reasonable time, in spite of the problem's general intractability. We conclude the paper with an outlook on possible extensions of the developed methodology, in particular regarding 3D shape approximation tasks.
Code available per request.
@article{TILLMANN2021101795,
title = {Structured discrete shape approximation: Theoretical complexity and practical algorithm},
journal = {Computational Geometry},
volume = {99},
pages = {101795},
year = {2021},
issn = {0925-7721},
doi = {https://doi.org/10.1016/j.comgeo.2021.101795},
url = {https://www.sciencedirect.com/science/article/pii/S0925772121000511},
author = {Andreas M. Tillmann and Leif Kobbelt},
keywords = {Shape approximation, Discrete assembly systems, Computational complexity, Mixed-integer programming, Zometool},
abstract = {We consider the problem of approximating a two-dimensional shape contour (or curve segment) using discrete assembly systems, which allow to build geometric structures based on limited sets of node and edge types subject to edge length and orientation restrictions. We show that already deciding feasibility of such approximation problems is NP-hard, and remains intractable even for very simple setups. We then devise an algorithmic framework that combines shape sampling with exact cardinality minimization to obtain good approximations using few components. As a particular application and showcase example, we discuss approximating shape contours using the classical Zometool construction kit and provide promising computational results, demonstrating that our algorithm is capable of obtaining good shape representations within reasonable time, in spite of the problem's general intractability. We conclude the paper with an outlook on possible extensions of the developed methodology, in particular regarding 3D shape approximation tasks.}
}
BoLTVOS: Box-Level Tracking for Video Object Segmentation

We approach video object segmentation (VOS) by splitting the task into two sub-tasks: bounding box level tracking, followed by bounding box segmentation. Following this paradigm, we present BoLTVOS (Box Level Tracking for VOS), which consists of an R-CNN detector conditioned on the first-frame bounding box to detect the object of interest, a temporal consistency rescoring algorithm, and a Box2Seg network that converts bounding boxes to segmentation masks. BoLTVOS performs VOS using only the first-frame bounding box without the mask. We evaluate our approach on DAVIS 2017 and YouTube-VOS, and show that it outperforms all methods that do not perform first-frame fine-tuning. We further present BoLTVOS-ft, which learns to segment the object in question using the first-frame mask while it is being tracked, without increasing the runtime. BoLTVOS-ft outperforms PReMVOS, the previously best performing VOS method on DAVIS 2016 and YouTube-VOS, while running up to 45 times faster. Our bounding box tracker also outperforms all previous short-term and longterm trackers on the bounding box level tracking datasets OTB 2015 and LTB35.
@article{VoigtlaenderLuiten19arxiv,
author = {Paul Voigtlaender and Jonathon Luiten and Bastian Leibe},
title = {{BoLTVOS: Box-Level Tracking for Video Object Segmentation}},
journal = {arXiv:1904.04552},
year = {2019}
}
3D-BEVIS: Birds-Eye-View Instance Segmentation
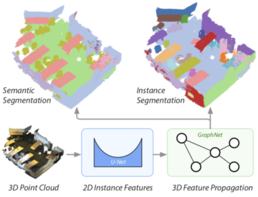
Recent deep learning models achieve impressive results on 3D scene analysis tasks by operating directly on unstructured point clouds. A lot of progress was made in the field of object classification and semantic segmentation. However, the task of instance segmentation is less explored. In this work, we present 3D-BEVIS, a deep learning framework for 3D semantic instance segmentation on point clouds. Following the idea of previous proposal-free instance segmentation approaches, our model learns a feature embedding and groups the obtained feature space into semantic instances. Current point-based methods scale linearly with the number of points by processing local sub-parts of a scene individually. However, to perform instance segmentation by clustering, globally consistent features are required. Therefore, we propose to combine local point geometry with global context information from an intermediate bird's-eye view representation.
@inproceedings{ElichGCPR19,
title = {{3D-BEVIS: Birds-Eye-View Instance Segmentation}},
author = {Elich, Cathrin and Engelmann, Francis and Schult, Jonas and Kontogianni, Theodora and Leibe, Bastian},
booktitle = {{German Conference on Pattern Recognition (GCPR)}},
year = {2019}
}
Computing the Spark: Mixed-Integer Programming for the (Vector) Matroid Girth Problem
We investigate the NP-hard problem of computing the spark of a matrix (i.e., the smallest number of linearly dependent columns), a key parameter in compressed sensing and sparse signal recovery. To that end, we identify polynomially solvable special cases, gather upper and lower bounding procedures, and propose several exact (mixed-)integer programming models and linear programming heuristics. In particular, we develop a branch-and-cut scheme to determine the girth of a matroid, focussing on the vector matroid case, for which the girth is precisely the spark of the representation matrix. Extensive numerical experiments demonstrate the effectiveness of our specialized algorithms compared to general-purpose black-box solvers applied to several mixed-integer programming models.
Code and test instances available per request; will become directly available on this page in the near future.
@article{Tillmann2019,
author = {Andreas M. Tillmann},
title = {{Computing the Spark: Mixed-Integer Programming\\for the (Vector) Matroid Girth Problem}},
journal = {{Computational Optimization and Applications}},
volume = {to appear},
year = {2019}
}
Previous Year (2018)
