
Publications
Spectral Quadrangulation with Orientation and Alignment Control
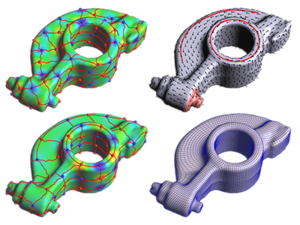
This paper presents a new quadrangulation algorithm, extending the spectral surface quadrangulation approach where the coarse quadrangular structure is derived from the Morse-Smale complex of an eigenfunction of the Laplacian operator on the input mesh. In contrast to the original scheme, we provide flexible explicit controls of the shape, size, orientation and feature alignment of the quadrangular faces. We achieve this by proper selection of the optimal eigenvalue (shape), by adaption of the area term in the Laplacian operator (size), and by adding special constraints to the Laplace eigenproblem (orientation and alignment). By solving a generalized eigenproblem we can generate a scalar field on the mesh whose Morse-Smale complex is of high quality and satisfies all the user requirements. The final quadrilateral mesh is generated from the Morse- Smale complex by computing a globally smooth parametrization. Here we additionally introduce edge constraints to preserve user specified feature lines accurately.
Geometric Modeling Based on Polygonal Meshes

In the last years triangle meshes have become increasingly popular and are nowadays intensively used in many different areas of computer graphics and geometry processing. In classical CAGD irregular triangle meshes developed into a valuable alternative to traditional spline surfaces, since their conceptual simplicity allows for more flexible and highly efficient processing. Moreover, the consequent use of triangle meshes as surface representation avoids error-prone conversions, e.g., from CAD surfaces to mesh-based input data of numerical simulations. Besides classical geometric modeling, other major areas frequently employing triangle meshes are computer games and movie production. In this context geometric models are often acquired by 3D scanning techniques and have to undergo post-processing and shape optimization techniques before being actually used in production.
High-Resolution Volumetric Computation of Offset Surfaces with Feature Preservation
We present a new algorithm for the efficient and reliable generation of offset surfaces for polygonal meshes. The algorithm is robust with respect to degenerate configurations and computes (self-)intersection free offsets that do not miss small and thin components. The results are correct within a prescribed e-tolerance. This is achieved by using a volumetric approach where the offset surface is defined as the union of a set of spheres, cylinders, and prisms instead of surface-based approaches that generally construct an offset surface by shifting the input mesh in normal direction. Since we are using the unsigned distance field, we can handle any type of topological inconsistencies including non-manifold configurations and degenerate triangles. A simple but effective mesh operation allows us to detect and include sharp features (shocks) into the output mesh and to preserve them during post-processing (decimation and smoothing). We discretize the distance function by an efficient multi-level scheme on an adaptive octree data structure. The problem of limited voxel resolutions inherent to every volumetric approach is avoided by breaking the bounding volume into smaller tiles and processing them independently. This allows for almost arbitrarily high voxel resolutions on a commodity PC while keeping the output mesh complexity low. The quality and performance of our algorithm is demonstrated for a number of challenging examples.
Image Selection For Improved Multi-View Stereo

The Middlebury Multi-View Stereo evaluation clearly shows that the quality and speed of most multi-view stereo algorithms depends significantly on the number and selection of input images. In general, not all input images contribute equally to the quality of the output model, since several images may often contain similar and hence overly redundant visual information. This leads to unnecessarily increased processing times. On the other hand, a certain degree of redundancy can help to improve the reconstruction in more ``difficult'' regions of a model. In this paper we propose an image selection scheme for multi-view stereo which results in improved reconstruction quality compared to uniformly distributed views. Our method is tuned towards the typical requirements of current multi-view stereo algorithms, and is based on the idea of incrementally selecting images so that the overall coverage of a simultaneously generated proxy is guaranteed without adding too much redundant information. Critical regions such as cavities are detected by an estimate of the local photo-consistency and are improved by adding additional views. Our method is highly efficient, since most computations can be out-sourced to the GPU. We evaluate our method with four different methods participating in the Middlebury benchmark and show that in each case reconstructions based on our selected images yield an improved output quality while at the same time reducing the processing time considerably.
Beam Tracing for Multipath Propagation in Urban Environments
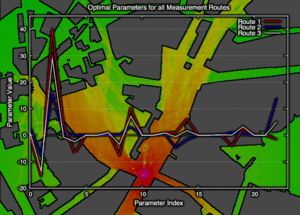
We present a novel method for efficient computation of complex channel characteristics due to multipath effects in urban microcell environments. Significant speedups are obtained compared to state-of-the-art ray-tracing algorithms by tracing continuous beams and by using parallelization techniques. We optimize simulation parameters using on-site measurements from real world networks. We formulate the adaption of model parameters as a constrained least-squares problem where each row of the matrix corresponds to one measurement location, and where the columns are formed by the beams that reach the respective location.
2D Video Editing for 3D Effects

We present a semi-interactive system for advanced video processing and editing. The basic idea is to partially recover planar regions in object space and to exploit this minimal pseudo-3D information in order to make perspectively correct modifications. Typical operations are to increase the quality of a low-resolution video by overlaying high-resolution photos of the same approximately planar object or to add or remove objects by copying them from other video streams and distorting them perspectively according to some planar reference geometry. The necessary user interaction is entirely in 2D and easy to perform even for untrained users. The key to our video processing functionality is a very robust and mostly automatic algorithm for the perspective registration of video frames and photos, which can be used as a very effective video stabilization tool even in the presence of fast and blurred motion. Explicit 3D reconstruction is thus avoided and replaced by image and video rectification. The technique is based on state-of-the-art feature tracking and homography matching. In complicated and ambiguous scenes, user interaction as simple as 2D brush strokes can be used to support the registration. In the stabilized video, he reference plane appears frozen which simplifies segmentation and matte extraction. We demonstrate our system for a number of quite challenging application scenarios such as video enhancement, background replacement, foreground removal and perspectively correct video cut and paste.
Interactive Global Illumination for Deformable Geometry in CUDA

Interactive global illumination for fully deformable scenes with dynamic relighting is currently a very elusive goal in the area of realistic rendering. In this work we propose a highly efficient and scalable system that is based on explicit visibility calculations. The rendering equation defines the light exchange between surfaces, which we approximate by subsampling. By utilizing the power of modern parallel GPUs using the CUDA framework we achieve interactive frame rates. Since we update the global illumination continuously in an asynchronous fashion, we maintain interactivity at all times for moderately complex scenes. We show that we can achieve higher frame rates for scenes with moving light sources, diffuse indirect illumination and dynamic geometry than other current methods, while maintaining a high image quality.
Updated paper: Small technical fix.
Parallel simulation of inextensible cloth

This paper presents an efficient simulation method for parallel cloth simulation. The presented method uses an impulse-based approach for the simulation. Cloth simulation has many application areas like computer animation, computer games or virtual reality. Simulation methods often make the assumption that cloth is an elastic material. In this way the simulation can be performed very efficiently by using spring forces. These methods disregard the fact that many textiles cannot be stretched significantly. The simulation of inextensible textiles with methods based on spring forces leads to stiff differential equations which cause a loss of performance. In contrast to that, in this paper a method is presented that simulates cloth by using impulses. The mesh of a cloth model is subdivided into strips of constraints. The impulses for each strip can be computed in linear time. The strips that have no common particle are independent from each other and can be solved in parallel. The impulse-based method allows the realistic simulation of inextensible textiles in real-time.
@inproceedings{Bender08,
author = {Jan Bender and Daniel Bayer},
title = {Parallel simulation of inextensible cloth},
booktitle = {Virtual Reality Interactions and Physical Simulations (VRIPhys)},
year = {2008},
month = nov,
address = {Grenoble (France)},
pages = {47-56}
}
Robust Object Detection with Interleaved Categorization and Segmentation
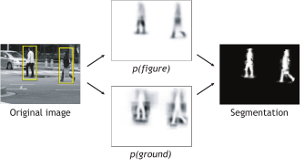
This paper presents a novel method for detecting and localizing objects of a visual category in cluttered real-world scenes. Our approach considers object categorization and figure-ground segmentation as two interleaved processes that closely collaborate towards a common goal. As shown in our work, the tight coupling between those two processes allows them to benefit from each other and improve the combined performance. The core part of our approach is a highly flexible learned representation for object shape that can combine the information observed on different training examples in a probabilistic extension of the Generalized Hough Transform. The resulting approach can detect categorical objects in novel images and automatically infer a probabilistic segmentation from the recognition result. This segmentation is then in turn used to again improve recognition by allowing the system to focus its efforts on object pixels and to discard misleading influences from the background. Moreover, the information from where in the image a hypothesis draws its support is employed in an MDL based hypothesis verification stage to resolve ambiguities between overlapping hypotheses and factor out the effects of partial occlusion. An extensive evaluation on several large data sets shows that the proposed system is applicable to a range of different object categories, including both rigid and articulated objects. In addition, its flexible representation allows it to achieve competitive object detection performance already from training sets that are between one and two orders of magnitude smaller than those used in comparable systems.
3D Urban Scene Modeling Integrating Recognition and Reconstruction

Supplying realistically textured 3D city models at ground level promises to be useful for pre-visualizing upcoming traffic situations in car navigation systems. Because this previsualization can be rendered from the expected future viewpoints of the driver, the required maneuver will be more easily understandable. 3D city models can be reconstructed from the imagery recorded by surveying vehicles. The vastness of image material gathered by these vehicles, however, puts extreme demands on vision algorithms to ensure their practical usability. Algorithms need to be as fast as possible and should result in compact, memory efficient 3D city models for future ease of distribution and visualization. For the considered application, these are not contradictory demands. Simplified geometry assumptions can speed up vision algorithms while automatically guaranteeing compact geometry models. In this paper, we present a novel city modeling framework which builds upon this philosophy to create 3D content at high speed. Objects in the environment, such as cars and pedestrians, may however disturb the reconstruction, as they violate the simplified geometry assumptions, leading to visually unpleasant artifacts and degrading the visual realism of the resulting 3D city model. Unfortunately, such objects are prevalent in urban scenes. We therefore extend the reconstruction framework by integrating it with an object recognition module that automatically detects cars in the input video streams and localizes them in 3D. The two components of our system are tightly integrated and benefit from each other’s continuous input. 3D reconstruction delivers geometric scene context, which greatly helps improve detection precision. The detected car locations, on the other hand, are used to instantiate virtual placeholder models which augment the visual realism of the reconstructed city model.
Using Recognition to Guide a Robot’s Attention

In the transition from industrial to service robotics, robots will have to deal with increasingly unpredictable and variable environments. We present a system that is able to recognize objects of a certain class in an image and to identify their parts for potential interactions. This is demonstrated for object instances that have never been observed during training, and under partial occlusion and against cluttered backgrounds. Our approach builds on the Implicit Shape Model of Leibe and Schiele, and extends it to couple recognition to the provision of meta-data useful for a task. Meta-data can for example consist of part labels or depth estimates. We present experimental results on wheelchairs and cars.
Measuring camera translation by the dominant apical angle

This paper provides a technique for measuring camera translation relatively w.r.t. the scene from two images. We demonstrate that the amount of the translation can be reliably measured for general as well as planar scenes by the most frequent apical angle, the angle under which the camera centers are seen from the perspective of the reconstructed scene points. Simulated experiments show that the dominant apical angle is a linear function of the length of the true camera translation. In a real experiment, we demonstrate that by skipping image pairs with too small motion, we can reliably initialize structure from motion, compute accurate camera trajectory in order to rectify images and use the ground plane constraint in recognition of pedestrians in a hand-held video sequence.
Accurate and Robust Registration for In-hand Modeling

We present fast 3D surface registration methods for inhand modeling. This allows users to scan complete objects swiftly by simply turning them around in front of the scanner. The paper makes two main contributions. First, we propose an efficient method for detecting registration failures, which is a vital property of any automatic modeling system. Our method is based on two different consistency tests, one based on geometry and one based on texture. Second, we extend ICP by three additional fast registration methods for both coarse and fine alignment based on both texture and geometry. Each of those methods brings in additional information that can compensate for ambiguities in the other cues. Together, they allow for the robust reconstruction of a large variety of objects with different geometric and photometric properties. Finally, we show how both failure detection and fast registration can be combined in a practical and robust in-hand modeling system that operates at interactive frame rates.
A Mobile Vision System for Robust Multi-Person Tracking

We present a mobile vision system for multi-person tracking in busy environments. Specifically, the system integrates continuous visual odometry computation with tracking-by-detection in order to track pedestrians in spite of frequent occlusions and egomotion of the camera rig. To achieve reliable performance under real-world conditions, it has long been advocated to extract and combine as much visual information as possible. We propose a way to closely integrate the vision modules for visual odometry, pedestrian detection, depth estimation, and tracking. The integration naturally leads to several cognitive feedback loops between the modules. Among others, we propose a novel feedback connection from the object detector to visual odometry which utilizes the semantic knowledge of detection to stabilize localization. Feedback loops always carry the danger that erroneous feedback from one module is amplified and causes the entire system to become instable. We therefore incorporate automatic failure detection and recovery, allowing the system to continue when a module becomes unreliable. The approach is experimentally evaluated on several long and difficult video sequences from busy inner-city locations. Our results show that the proposed integration makes it possible to deliver stable tracking performance in scenes of previously infeasible complexity.
World-scale Mining of Objects and Events from Community Photo Collections

In this paper, we describe an approach for mining images of objects (such as touristic sights) from community photo col- lections in an unsupervised fashion. Our approach relies on retrieving geotagged photos from those web-sites using a grid of geospatial tiles. The downloaded photos are clustered into potentially interesting entities through a processing pipeline of several modalities, including visual, textual and spatial proximity. The resulting clusters are analyzed and are automatically classified into objects and events. Using mining techniques, we then find text labels for these clusters, which are used to again assign each cluster to a corresponding Wikipedia article in a fully unsupervised manner. A final ver- ification step uses the contents (including images) from the selected Wikipedia article to verify the cluster-article assignment. We demonstrate this approach on several urban areas, densely covering an area of over 700 square kilometers and mining over 200,000 photos, making it probably the largest experiment of its kind to date.
Probabilistic Parameter Selection for Learning Scene Structure from Video
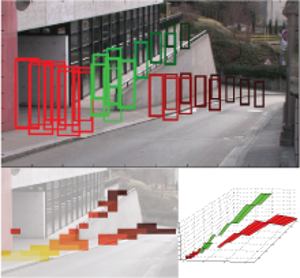
We present an online learning approach for robustly combining unreliable observations from a pedestrian detector to estimate the rough 3D scene geometry from video sequences of a static camera. Our approach is based on an entropy modelling framework, which allows to simultaneously adapt the detector parameters, such that the expected information gain about the scene structure is maximised. As a result, our approach automatically restricts the detector scale range for each image region as the estimation results become more confident, thus improving detector run-time and limiting false positives.
Coupled Object Detection and Tracking from Static Cameras and Moving Vehicles

We present a novel approach for multi-object tracking which considers object detection and spacetime trajectory estimation as a coupled optimization problem. Our approach is formulated in a Minimum Description Length hypothesis selection framework, which allows our system to recover from mismatches and temporarily lost tracks. Building upon a state-of-the-art object detector, it performs multi-view/multi-category object recognition to detect cars and pedestrians in the input images. The 2D object detections are checked for their consistency with (automatically estimated) scene geometry and are converted to 3D observations, which are accumulated in a world coordinate frame. A subsequent trajectory estimation module analyzes the resulting 3D observations to find physically plausible spacetime trajectories. Tracking is achieved by performing model selection after every frame. At each time instant, our approach searches for the globally optimal set of spacetime trajectories which provides the best explanation for the current image and for all evidence collected so far, while satisfying the constraints that no two objects may occupy the same physical space, nor explain the same image pixels at any point in time. Successful trajectory hypotheses are then fed back to guide object detection in future frames. The optimization procedure is kept efficient through incremental computation and conservative hypothesis pruning. We evaluate our approach on several challenging video sequences and demonstrate its performance on both a surveillance-type scenario and a scenario where the input videos are taken from inside a moving vehicle passing through crowded city areas.
Articulated Multi-Body Tracking Under Egomotion

In this paper, we address the problem of 3D articulated multi-person tracking in busy street scenes from a moving, human-level observer. In order to handle the complexity of multi-person interactions, we propose to pursue a two-stage strategy. A multi-body detection-based tracker first analyzes the scene and recovers individual pedestrian trajectories, bridging sensor gaps and resolving temporary occlusions. A specialized articulated tracker is then applied to each recovered pedestrian trajectory in parallel to estimate the tracked person's precise body pose over time. This articulated tracker is implemented in a Gaussian Process framework and operates on global pedestrian silhouettes using a learned statistical representation of human body dynamics. We interface the two tracking levels through a guided segmentation stage, which combines traditional bottom-up cues with top-down information from a human detector and the articulated tracker's shape prediction. We show the proposed approach's viability and demonstrate its performance for articulated multi-person tracking on several challenging video sequences of a busy inner-city scenario.
LaserBrush: A Flexible Device for 3D Reconstruction of Indoor Scenes

While many techniques for the 3D reconstruction of small to medium sized objects have been proposed in recent years, the reconstruction of entire scenes is still a challenging task. This is especially true for indoor environments where existing active reconstruction techniques are usually quite expensive and passive, image-based techniques tend to fail due to high scene complexities, difficult lighting situations, or shiny surface materials. To fill this gap we present a novel low-cost method for the reconstruction of depth maps using a video camera and an array of laser pointers mounted on a hand-held rig. Similar to existing laser-based active reconstruction techniques, our method is based on a fixed camera, moving laser rays and depth computation by triangulation. However, unlike traditional methods, the position and orientation of the laser rig does not need to be calibrated a-priori and no precise control is necessary during image capture. The user rather moves the laser rig freely through the scene in a brush-like manner, letting the laser points sweep over the scene's surface. We do not impose any constraints on the distribution of the laser rays, the motion of the laser rig, or the scene geometry except that in each frame at least six laser points have to be visible. Our main contributions are two-fold. The first is the depth map reconstruction technique based on irregularly oriented laser rays that, by exploiting robust sampling techniques, is able to cope with missing and even wrongly detected laser points. The second is a smoothing operator for the reconstructed geometry specifically tailored to our setting that removes most of the inevitable noise introduced by calibration and detection errors without damaging important surface features like sharp edges.
An Incremental Approach to Feature Aligned Quad Dominant Remeshing

In this paper we present a new algorithm which turns an unstructured triangle mesh into a quad-dominant mesh with edges aligned to the principal directions of the underlying geometry. Instead of computing a globally smooth parameterization or integrating curvature lines along a tangent vector field, we simply apply an iterative relaxation scheme which incrementally aligns the mesh edges to the principal directions. The quad-dominant mesh is eventually obtained by dropping the not-aligned diagonals from the triangle mesh. A post-processing stage is introduced to further improve the results. The major advantage of our algorithm is its conceptual simplicity since it is merely based on elementary mesh operations such as edge collapse, flip, and split. The resulting meshes exhibit a very good alignment to surface features and rather uniform distribution of mesh vertices. This makes them very well-suited, e.g., as Catmull-Clark Subdivision control meshes.
Semantic representation of complex building structures

In this paper we present an abstract semantic representation that is suitable for complex buildings. Facades with high-level detail are required in several domains, e.g. visualization of architectural settings and archaeological sites as well as computer animations. In order to support the user’s modeling task, besides geometrical data structural information like spatial relations is required. This supplementary information represents the semantics of the model. Therefore the model description must incorporate the geometry and the semantics. Such a description allows a partial automation of the modeling process, e.g. adjacent and nested elements are adjusted automatically. An abstract model representation with integrated semantics is presented in this paper and it is shown that it facilitates the modeling task significantly.
@inproceedings{Finkenzeller08,
author = {Dieter Finkenzeller and Jan Bender},
title = {Semantic representation of complex building structures},
booktitle = {Computer Graphics and Visualization (CGV 2008) - IADIS Multi Conference on Computer Science and Information Systems},
year = {2008},
month = jul,
address = {Amsterdam (Netherlands)}
}
Impulse-based simulation of inextensible cloth

In this paper an impulse-based method for cloth simulation is presented. The simulation of cloth is required in different application areas like computer animation, virtual reality or computer games. Simulation methods often assume that cloth is an elastic material. With this assumption the simulation can be performed very efficiently using spring forces. The problem is that many textiles cannot be stretched significantly. A realistic simulation of these textiles with spring forces leads to stiff differential equations which cause a deterioration of performance. The impulse-based method described in this paper solves this problem and allows the realistic simulation of inelastic textiles.
@inproceedings{Bender08,
author = {Jan Bender and Daniel Bayer},
title = {Impulse-based simulation of inextensible cloth},
booktitle = {Computer Graphics and Visualization (CGV 2008) - IADIS Multi Conference on Computer Science and Information Systems},
year = {2008},
month = jul,
address = {Amsterdam (Netherlands)}
}
City Virtualization

Virtual city models become more and more important in applications like virtual city guides, geographic information systems or large scale visualizations, and also play an important role during the design of wireless networks and the simulation of noise distribution or environmental phenomena. However, generating city models of sufficient quality with respect to different target applications is still an extremely challenging, time consuming and costly process. To improve this situation, we present a novel system for the rapid and easy creation of 3D city models from 2D map data and terrain information, which is available for many cities in digital form. Our system allows to continuously vary the resulting level of correctness, ranging from models with high-quality geometry and plausible appearance which are generated almost completely automatic to models with correctly textured facades and highly detailed representations of important, well known buildings which can be generated with reasonable additional effort. While our main target application is the high-quality, real-time visualization of complex, detailed city models, the models generated with our approach have successfully been used for radio wave simulations as well. To demonstrate the validity of our approach, we show an exemplary reconstruction of the city of Aachen.
Quadrangular Parameterization for Reverse Engineering
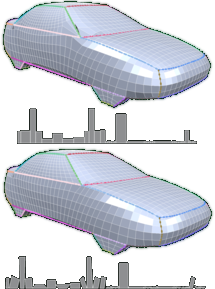
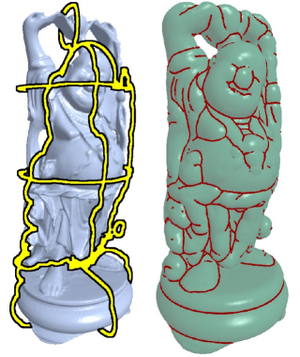
The aim of Reverse Engineering is to convert an unstructured representation of a geometric object, emerging e.g. from laser scanners, into a natural, structured representation in the spirit of CAD models, which is suitable for numerical computations. Therefore we present a user-controlled, as isometric as possible parameterization technique which is able to prescribe geometric features of the input and produces high-quality quadmeshes with low distortion. Starting with a coarse, user-prescribed layout this is achieved by using affine functions for the transition between non-orthogonal quadrangular charts of a global parameterization. The shape of each chart is optimized non-linearly for isometry of the underlying parameterization to produce meshes with low edge-length distortion. To provide full control over the meshing alignment the user can additionally tag an arbitrary subset of the layout edges which are guaranteed to be represented by enforcing them to lie on iso-lines of the parameterization but still allowing the global parameterization to relax in the direction of the iso-lines.
Impulsbasierte Dynamiksimulation von Mehrkörpersystemen in der virtuellen Realität

Die dynamische Simulation gewinnt im Bereich der virtuellen Realität immer mehr an Bedeutung. Sie ist ein wichtiges Hilfsmittel, um den Grad der Immersion des Benutzers in eine virtuelle Welt zu erhöhen. In diesem Anwendungsbereich ist die Geschwindigkeit des verwendeten Simulationsverfahrens entscheidend. Weitere Anforderungen an das Verfahren sind unter anderem Genauigkeit, Stabilität und eine einfache Implementierung. In dieser Arbeit wird ein neues impulsbasiertes Verfahren für die dynamische Simulation von Mehrkörpersystemen vorgestellt. Dieses erfüllt, im Gegensatz zu klassischen Verfahren, alle Anforderungen der virtuellen Realität. Das vorgestellte Verfahren arbeitet ausschließlich mit Impulsen, um mechanische Gelenke, Kollisionen und bleibende Kontakte mit Reibung zu simulieren.
@inproceedings{Bender08,
author = {Jan Bender},
title = {Impulsbasierte Dynamiksimulation von Mehrkörpersystemen in der virtuellen Realität},
booktitle = {GI-Edition Lecture Notes in Informatics (LNI) - Ausgezeichnete Informatikdissertationen 2007},
year = {2008},
pages = {21-30}
}
Vergleich der impulsbasierten Dynamiksimulation mit der Lagrange-Faktoren-Methode

Eine der am weitesten verbreiteten Methoden zur Simulation von mechanischen Starrkörpersystemen ist die Lagrange-Faktoren-Methode (LFM). Die impulsbasierte Dynamiksimulation ist ein neuer alternativer Ansatz zur Simulation solcher Systeme. Durch den direkten Vergleich werden in dieser Arbeit die Vor- und Nachteile der beiden Methoden aufgezeigt. Dazu wird neben einer Laufzeit- und Genauigkeitsmessung zusätzlich ein informeller Vergleich durchgeführt und die Ergebnisse diskutiert.
@inproceedings{Bayer08,
author = {Daniel Bayer and Jan Bender},
title = {Vergleich der impulsbasierten Dynamiksimulation mit der Lagrange-Faktoren-Methode},
booktitle = {5. Workshop "Virtuelle und Erweiterte Realität der Fachgruppe VR/AR"},
year = {2008},
month = sep,
address = {Magdeburg (Germany)},
pages = {185-196}
}
Design of a dynamic simulation system for VR applications
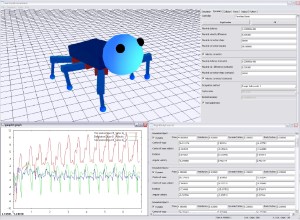
A dynamic simulation system for VR applications consists of multiple parts. The first task that must be accomplished is the generation of complex dynamic models. A 3D modelling tool is required that supports the definition of joint constraints and dynamic parameters. For the dynamic simulation of the generated models a modular simulator is required. This simulator must handle constrained models, detect and resolve collisions regarding dynamic and static friction, manage user interactions and provide the possibility of extensions. It also requires an interface for the output of the simulation data. There exist several different methods for the dynamic simulation of joint constraints, for collision detection and for the handling of collisions and resting contacts with friction. The simulation system should support multiple of these methods and provide the possibility to exchange them at runtime.
@TechReport{Bender08_13,
author = "Jan Bender",
title = "Design of a dynamic simulation system for VR applications",
institution = "University of Karlsruhe",
year = "2008",
type = "Technical Report",
number = "13"
}
A Sketch-Based Interface for Architectural Modification in Virtual Environments

This paper presents a sketch-based interface for interactive modification of architectural design prototypes inside a virtual environment. The user can move around in the scenery and create line drawings to add annotations. In order to modify or extend the scenery, she can sketch command symbols, which are then recognized by the application to trigger the application defined commands. This allows the user to modify existing objects in the scene as well as to create new ones. This sketch based interface is supposed to act as a front-end application for architects in order to have a tool for the interactive reconfiguration of rooms and interior in a visual-acoustic virtual environment.
@inproceedings{rausch2008sketch,
title={ A Sketch-Based Interface for Architectural Modification in Virtual Environments},
author={Rausch, Dominik and Assenmacher, Ingo},
booktitle={5. Workshop der GI-Fachgruppe VR/AR },
year={2008}
}
Previous Year (2007)
