
Publications
Directional Field Synthesis, Design, and Processing

Direction fields and vector fields play an increasingly important role in computer graphics and geometry processing. The synthesis of directional fields on surfaces, or other spatial domains, is a fundamental step in numerous applications, such as mesh generation, deformation, texture mapping, and many more. The wide range of applications resulted in definitions for many types of directional fields: from vector and tensor fields, over line and cross fields, to frame and vector-set fields. Depending on the application at hand, researchers have used various notions of objectives and constraints to synthesize such fields. These notions are defined in terms of fairness, feature alignment, symmetry, or field topology, to mention just a few. To facilitate these objectives, various representations, discretizations, and optimization strategies have been developed. These choices come with varying strengths and weaknesses. This course provides a systematic overview of directional field synthesis for graphics applications, the challenges it poses, and the methods developed in recent years to address these challenges.
@inproceedings{Vaxman:2017:DFS:3084873.3084921,
author = {Vaxman, Amir and Campen, Marcel and Diamanti, Olga and Bommes, David and Hildebrandt, Klaus and Technion, Mirela Ben-Chen and Panozzo, Daniele},
title = {Directional Field Synthesis, Design, and Processing},
booktitle = {ACM SIGGRAPH 2017 Courses},
series = {SIGGRAPH '17},
year = {2017},
isbn = {978-1-4503-5014-3},
location = {Los Angeles, California},
pages = {12:1--12:30},
articleno = {12},
numpages = {30},
url = {http://doi.acm.org/10.1145/3084873.3084921},
doi = {10.1145/3084873.3084921},
acmid = {3084921},
publisher = {ACM},
address = {New York, NY, USA},
}
Exploring Spatial Context for 3D Semantic Segmentation of Point Clouds
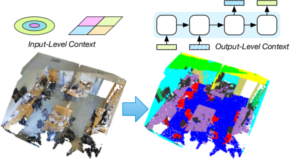
Deep learning approaches have made tremendous progress in the field of semantic segmentation over the past few years. However, most current approaches operate in the 2D image space. Direct semantic segmentation of unstructured 3D point clouds is still an open research problem. The recently proposed PointNet architecture presents an interesting step ahead in that it can operate on unstructured point clouds, achieving decent segmentation results. However, it subdivides the input points into a grid of blocks and processes each such block individually. In this paper, we investigate the question how such an architecture can be extended to incorporate larger-scale spatial context. We build upon PointNet and propose two extensions that enlarge the receptive field over the 3D scene. We evaluate the proposed strategies on challenging indoor and outdoor datasets and show improved results in both scenarios.
@inproceedings{3dsemseg_ICCVW17,
author = {Francis Engelmann and
Theodora Kontogianni and
Alexander Hermans and
Bastian Leibe},
title = {Exploring Spatial Context for 3D Semantic Segmentation of Point Clouds},
booktitle = {{IEEE} International Conference on Computer Vision, 3DRMS Workshop, {ICCV}},
year = {2017}
}
Online Adaptation of Convolutional Neural Networks for Video Object Segmentation

We tackle the task of semi-supervised video object segmentation, i.e. segmenting the pixels belonging to an object in the video using the ground truth pixel mask for the first frame. We build on the recently introduced one-shot video object segmentation (OSVOS) approach which uses a pretrained network and fine-tunes it on the first frame. While achieving impressive performance, at test time OSVOS uses the fine-tuned network in unchanged form and is not able to adapt to large changes in object appearance. To overcome this limitation, we propose Online Adaptive Video Object Segmentation (OnAVOS) which updates the network online using training examples selected based on the confidence of the network and the spatial configuration. Additionally, we add a pretraining step based on objectness, which is learned on PASCAL. Our experiments show that both extensions are highly effective and improve the state of the art on DAVIS to an intersection-over-union score of 85.7%.
@inproceedings{voigtlaender17BMVC,
author = {Paul Voigtlaender and Bastian Leibe},
title = {Online Adaptation of Convolutional Neural Networks for Video Object Segmentation},
booktitle = {BMVC},
year = {2017}
}
Variance-Minimizing Transport Plans for Inter-surface Mapping
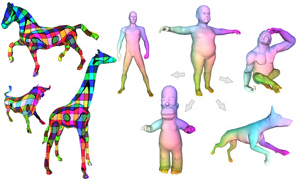
We introduce an efficient computational method for generating dense and low distortion maps between two arbitrary surfaces of same genus. Instead of relying on semantic correspondences or surface parameterization, we directly optimize a variance-minimizing transport plan between two input surfaces that defines an as-conformal-as-possible inter-surface map satisfying a user-prescribed bound on area distortion. The transport plan is computed via two alternating convex optimizations, and is shown to minimize a generalized Dirichlet energy of both the map and its inverse. Computational efficiency is achieved through a coarse-to-fine approach in diffusion geometry, with Sinkhorn iterations modified to enforce bounded area distortion. The resulting inter-surface mapping algorithm applies to arbitrary shapes robustly, with little to no user interaction.
@article{Mandad:2017:Mapping,
author = "Mandad, Manish and Cohen-Steiner, David and Kobbelt, Leif and Alliez, Pierre and Desbrun, Mathieu",
title = "Variance-Minimizing Transport Plans for Inter-surface Mapping",
journal = "ACM Transactions on Graphics",
volume = 36,
number = 4,
year = 2017,
articleno = {39},
}
Robust eXtended Finite Elements for Complex Cutting of Deformables
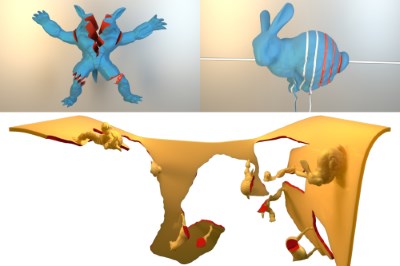
In this paper we present a robust remeshing-free cutting algorithm on the basis of the eXtended Finite Element Method (XFEM) and fully implicit time integration. One of the most crucial points of the XFEM is that integrals over discontinuous polynomials have to be computed on subdomains of the polyhedral elements. Most existing approaches construct a cut-aligned auxiliary mesh for integration. In contrast, we propose a cutting algorithm that includes the construction of specialized quadrature rules for each dissected element without the requirement to explicitly represent the arising subdomains. Moreover, we solve the problem of ill-conditioned or even numerically singular solver matrices during time integration using a novel algorithm that constrains non-contributing degrees of freedom (DOFs) and introduce a preconditioner that efficiently reuses the constructed quadrature weights. Our method is particularly suitable for fine structural cutting as it decouples the added number of DOFs from the cut's geometry and correctly preserves geometry and physical properties by accurate integration. Due to the implicit time integration these fine features can still be simulated robustly using large time steps. As opposed to this, the vast majority of existing approaches either use remeshing or element duplication. Remeshing based methods are able to correctly preserve physical quantities but strongly couple cut geometry and mesh resolution leading to an unnecessary large number of additional DOFs. Element duplication based approaches keep the number of additional DOFs small but fail at correct conservation of mass and stiffness properties. We verify consistency and robustness of our approach on simple and reproducible academic examples while stability and applicability are demonstrated in large scenarios with complex and fine structural cutting.
@ARTICLE{ Koschier2017,
author= {Dan Koschier and Jan Bender and Nils Thuerey},
title= {{Robust eXtended Finite Elements for Complex Cutting of Deformables}},
year= {2017},
journal= {ACM Transactions on Graphics (SIGGRAPH)},
publisher= {ACM},
volume = {36},
number = {4},
pages= {12}
}
Full-Resolution Residual Networks for Semantic Segmentation in Street Scenes
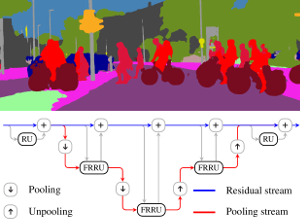
Semantic image segmentation is an essential component of modern autonomous driving systems, as an accurate understanding of the surrounding scene is crucial to navigation and action planning. Current state-of-the-art approaches in semantic image segmentation rely on pre-trained networks that were initially developed for classifying images as a whole. While these networks exhibit outstanding recognition performance (i.e., what is visible?), they lack localization accuracy (i.e., where precisely is something located?). Therefore, additional processing steps have to be performed in order to obtain pixel-accurate segmentation masks at the full image resolution. To alleviate this problem we propose a novel ResNet-like architecture that exhibits strong localization and recognition performance. We combine multi-scale context with pixel-level accuracy by using two processing streams within our network: One stream carries information at the full image resolution, enabling precise adherence to segment boundaries. The other stream undergoes a sequence of pooling operations to obtain robust features for recognition. The two streams are coupled at the full image resolution using residuals. Without additional processing steps and without pre-training, our approach achieves an intersection-over-union score of 71.8% on the Cityscapes dataset.
@inproceedings{Pohlen2017CVPR,
title = {{Full-Resolution Residual Networks for Semantic Segmentation in Street Scenes}},
author = {Pohlen, Tobias and Hermans, Alexander and Mathias, Markus and Leibe, Bastian},
booktitle = {{IEEE Conference on Computer Vision and Pattern Recognition (CVPR'17)}},
year = {2017}
}
Semi-Supervised Deep Learning for Monocular Depth Map Prediction
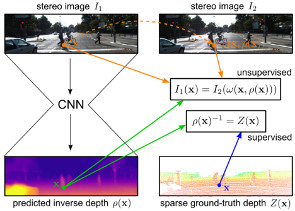
Supervised deep learning often suffers from the lack of sufficient training data. Specifically in the context of monocular depth map prediction, it is barely possible to determine dense ground truth depth images in realistic dynamic outdoor environments. When using LiDAR sensors, for instance, noise is present in the distance measurements, the calibration between sensors cannot be perfect, and the measurements are typically much sparser than the camera images. In this paper, we propose a novel approach to depth map prediction from monocular images that learns in a semi-supervised way. While we use sparse ground-truth depth for supervised learning, we also enforce our deep network to produce photoconsistent dense depth maps in a stereo setup using a direct image alignment loss. In experiments we demonstrate superior performance in depth map prediction from single images compared to the state-of-the-art methods.
@inproceedings{kuznietsov2017_semsupdepth,
title = {Semi-Supervised Deep Learning for Monocular Depth Map Prediction},
author = {Kuznietsov, Yevhen and St\"uckler, J\"org and Leibe, Bastian},
booktitle = {IEEE International Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2017}
}
Combined Image- and World-Space Tracking in Traffic Scenes

Tracking in urban street scenes plays a central role in autonomous systems such as self-driving cars. Most of the current vision-based tracking methods perform tracking in the image domain. Other approaches, e.g. based on LIDAR and radar, track purely in 3D. While some vision-based tracking methods invoke 3D information in parts of their pipeline, and some 3D-based methods utilize image-based information in components of their approach, we propose to use image- and world-space information jointly throughout our method. We present our tracking pipeline as a 3D extension of image-based tracking. From enhancing the detections with 3D measurements to the reported positions of every tracked object, we use world- space 3D information at every stage of processing. We accomplish this by our novel coupled 2D-3D Kalman filter, combined with a conceptually clean and extendable hypothesize-and-select framework. Our approach matches the current state-of-the-art on the official KITTI benchmark, which performs evaluation in the 2D image domain only. Further experiments show significant improvements in 3D localization precision by enabling our coupled 2D-3D tracking.
@inproceedings{Osep17ICRA,
title={Combined Image- and World-Space Tracking in Traffic Scenes},
author={O\v{s}ep, Aljo\v{s}a and Mehner, Wolfgang and Mathias, Markus and Leibe, Bastian},
booktitle={ICRA},
year={2017}
}
Boundary Element Octahedral Fields in Volumes
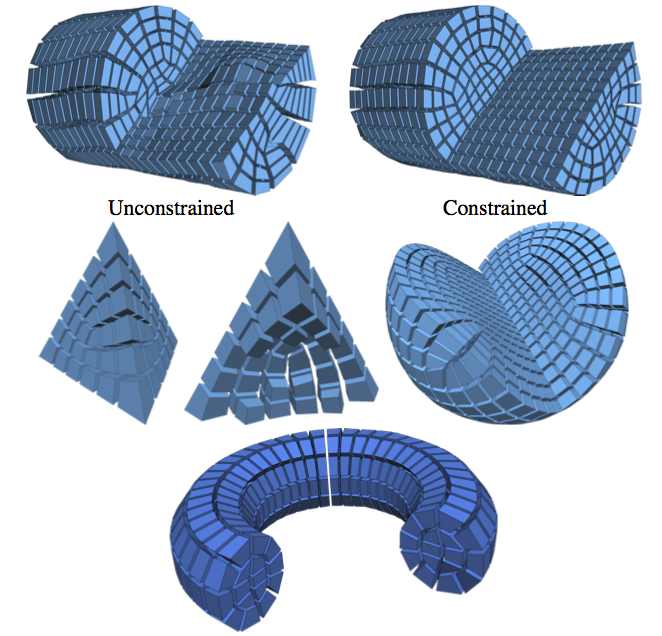
The computation of smooth fields of orthogonal directions within a volume is a critical step in hexahedral mesh generation, used to guide placement of edges and singularities. While this problem shares high-level structure with surface-based frame field problems, critical aspects are lost when extending to volumes, while new structure from the flat Euclidean metric emerges. Taking these considerations into account, this paper presents an algorithm for computing such “octahedral” fields. Unlike existing approaches, our formulation achieves infinite resolution in the interior of the volume via the boundary element method (BEM), continuously assigning frames to points in the interior from only a triangle mesh discretization of the boundary. The end result is an orthogonal direction field that can be sampled anywhere inside the mesh, with smooth variation and singular structure in the interior even with a coarse boundary. We illustrate our computed frames on a number of challenging test geometries. Since the octahedral frame field problem is relatively new, we also contribute a thorough discussion of theoretical and practical challenges unique to this problem.
@article{Solomon:2017:BEO:3087678.3065254,
author = {Solomon, Justin and Vaxman, Amir and Bommes, David},
title = {Boundary Element Octahedral Fields in Volumes},
journal = {ACM Trans. Graph.},
issue_date = {June 2017},
volume = {36},
number = {3},
month = may,
year = {2017},
issn = {0730-0301},
pages = {28:1--28:16},
articleno = {28},
numpages = {16},
url = {http://doi.acm.org/10.1145/3065254},
doi = {10.1145/3065254},
acmid = {3065254},
publisher = {ACM},
address = {New York, NY, USA},
keywords = {Octahedral fields, boundary element method, frames, singularity graph},
}
An hp-Adaptive Discretization Algorithm for Signed Distance Field Generation
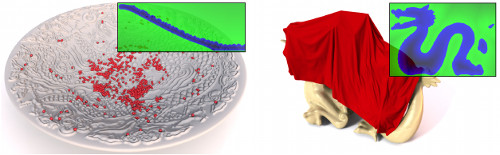
In this paper we present an hp-adaptive algorithm to generate discrete higher-order polynomial Signed Distance Fields (SDFs) on axis-aligned hexahedral grids from manifold polygonal input meshes. Using an orthonormal polynomial basis, we efficiently fit the polynomials to the underlying signed distance function on each cell. The proposed error-driven construction algorithm is globally adaptive and iteratively refines the SDFs using either spatial subdivision (h-refinement) following an octree scheme or by cell-wise adaption of the polynomial approximation's degree (p-refinement). We further introduce a novel decision criterion based on an error-estimator in order to decide whether to apply p- or h-refinement. We demonstrate that our method is able to construct more accurate SDFs at significantly lower memory consumption compared to previous approaches. While the cell-wise polynomial approximation will result in highly accurate SDFs, it can not be guaranteed that the piecewise approximation is continuous over cell interfaces. Therefore, we propose an optimization-based post-processing step in order to weakly enforce continuity. Finally, we apply our generated SDFs as collision detector to the physically-based simulation of geometrically highly complex solid objects in order to demonstrate the practical relevance and applicability of our method.
@Article{KDBB17,
author = {Koschier, Dan and Deul, Crispin and Brand, Magnus and Bender, Jan},
title = {An hp-Adaptive Discretization Algorithm for Signed Distance Field Generation},
journal = {IEEE Transactions on Visualization and Computer Graphics},
year = {2017},
volume = {23},
number = {10},
pages = {1--14},
issn = {1077-2626},
doi = {10.1109/TVCG.2017.2730202}
}
Multi-View Deep Learning for Consistent Semantic Mapping with RGB-D Cameras
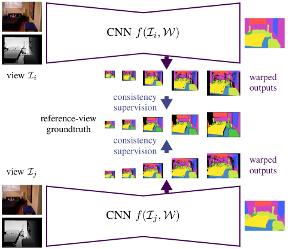
Visual scene understanding is an important capability that enables robots to purposefully act in their environment. In this paper, we propose a novel deep neural network approach to predict semantic segmentation from RGB-D sequences. The key innovation is to train our network to predict multi-view consistent semantics in a self-supervised way. At test time, its semantics predictions can be fused more consistently in semantic keyframe maps than predictions of a network trained on individual views. We base our network architecture on a recent single-view deep learning approach to RGB and depth fusion for semantic object-class segmentation and enhance it with multi-scale loss minimization. We obtain the camera trajectory using RGB-D SLAM and warp the predictions of RGB-D images into ground-truth annotated frames in order to enforce multi-view consistency during training. At test time, predictions from multiple views are fused into keyframes. We propose and analyze several methods for enforcing multi-view consistency during training and testing. We evaluate the benefit of multi-view consistency training and demonstrate that pooling of deep features and fusion over multiple views outperforms single-view baselines on the NYUDv2 benchmark for semantic segmentation. Our end-to-end trained network achieves state-of-the-art performance on the NYUDv2 dataset in single-view segmentation as well as multi-view semantic fusion.
@string{iros="International Conference on Intelligent Robots and Systems (IROS)"}
@InProceedings{lingni17iros,
author = "Lingni Ma and J\"org St\"uckler and Christian Kerl and Daniel Cremers",
title = "Multi-View Deep Learning for Consistent Semantic Mapping with RGB-D Cameras",
booktitle = "IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS)",
year = "2017",
}
Keyframe-Based Visual-Inertial Online SLAM with Relocalization
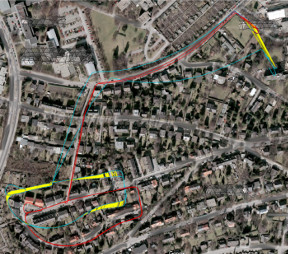
Complementing images with inertial measurements has become one of the most popular approaches to achieve highly accurate and robust real-time camera pose tracking. In this paper, we present a keyframe-based approach to visual-inertial simultaneous localization and mapping (SLAM) for monocular and stereo cameras. Our method is based on a real-time capable visual-inertial odometry method that provides locally consistent trajectory and map estimates. We achieve global consistency in the estimate through online loop-closing and non-linear optimization. Furthermore, our approach supports relocalization in a map that has been previously obtained and allows for continued SLAM operation. We evaluate our approach in terms of accuracy, relocalization capability and run-time efficiency on public benchmark datasets and on newly recorded sequences. We demonstrate state-of-the-art performance of our approach towards a visual-inertial odometry method in recovering the trajectory of the camera.
@article{Kasyanov2017_VISLAM,
title={{Keyframe-Based Visual-Inertial Online SLAM with Relocalization}},
author={Anton Kasyanov and Francis Engelmann and J\"org St\"uckler and Bastian Leibe},
booktitle={{IEEE/RSJ} International Conference on Intelligent Robots and Systems {(IROS)}},
year={2017}
}
SAMP: Shape and Motion Priors for 4D Vehicle Reconstruction

Inferring the pose and shape of vehicles in 3D from a movable platform still remains a challenging task due to the projective sensing principle of cameras, difficult surface properties, e.g. reflections or transparency, and illumination changes between images. In this paper, we propose to use 3D shape and motion priors to regularize the estimation of the trajectory and the shape of vehicles in sequences of stereo images. We represent shapes by 3D signed distance functions and embed them in a low-dimensional manifold. Our optimization method allows for imposing a common shape across all image observations along an object track. We employ a motion model to regularize the trajectory to plausible object motions. We evaluate our method on the KITTI dataset and show state-of-the-art results in terms of shape reconstruction and pose estimation accuracy.
@inproceedings{EngelmannWACV17_samp,
author = {Francis Engelmann and J{\"{o}}rg St{\"{u}}ckler and Bastian Leibe},
title = {{SAMP:} Shape and Motion Priors for 4D Vehicle Reconstruction},
booktitle = {{IEEE} Winter Conference on Applications of Computer Vision,
{WACV}},
year = {2017}
}
Divergence-Free SPH for Incompressible and Viscous Fluids

In this paper we present a novel Smoothed Particle Hydrodynamics (SPH) method for the efficient and stable simulation of incompressible fluids. The most efficient SPH-based approaches enforce incompressibility either on position or velocity level. However, the continuity equation for incompressible flow demands to maintain a constant density and a divergence-free velocity field. We propose a combination of two novel implicit pressure solvers enforcing both a low volume compression as well as a divergence-free velocity field. While a compression-free fluid is essential for realistic physical behavior, a divergence-free velocity field drastically reduces the number of required solver iterations and increases the stability of the simulation significantly. Thanks to the improved stability, our method can handle larger time steps than previous approaches. This results in a substantial performance gain since the computationally expensive neighborhood search has to be performed less frequently. Moreover, we introduce a third optional implicit solver to simulate highly viscous fluids which seamlessly integrates into our solver framework. Our implicit viscosity solver produces realistic results while introducing almost no numerical damping. We demonstrate the efficiency, robustness and scalability of our method in a variety of complex simulations including scenarios with millions of turbulent particles or highly viscous materials.
@article{Bender2017,
author = {Jan Bender and Dan Koschier},
title = {Divergence-Free SPH for Incompressible and Viscous Fluids},
year = {2017},
journal = {IEEE Transactions on Visualization and Computer Graphics},
publisher = {IEEE},
year={2017},
volume={23},
number={3},
pages={1193-1206},
keywords={Smoothed Particle Hydrodynamics;divergence-free fluids;fluid simulation;implicit integration;incompressibility;viscous fluids},
doi={10.1109/TVCG.2016.2578335},
ISSN={1077-2626}
}
Interactive Exploration of Dissipation Element Geometry

Dissipation elements (DE) define a geometrical structure for the analysis of small-scale turbulence. Existing analyses based on DEs focus on a statistical treatment of large populations of DEs. In this paper, we propose a method for the interactive visualization of the geometrical shape of DE populations. We follow a two-step approach: in a pre-processing step, we approximate individual DEs by tube-like, implicit shapes with elliptical cross sections of varying radii; we then render these approximations by direct ray-casting thereby avoiding the need for costly generation of detailed, explicit geometry for rasterization. Our results demonstrate that the approximation gives a reasonable representation of DE geometries and the rendering performance is suitable for interactive use.
@InProceedings{Vierjahn2017,
booktitle = {Eurographics Symposium on Parallel Graphics and Visualization},
author = {Tom Vierjahn and Andrea Schnorr and Benjamin Weyers and Dominik Denker and Ingo Wald and Christoph Garth and Torsten W. Kuhlen and Bernd Hentschel},
title = {Interactive Exploration of Dissipation Element Geometry},
year = {2017},
pages = {53--62},
ISSN = {1727-348X},
ISBN = {978-3-03868-034-5},
doi = {10.2312/pgv.20171093},
}
A Task-Based Parallel Rendering Component For Large-Scale Visualization Applications
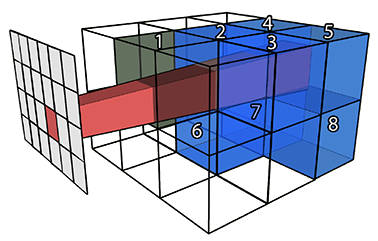
An increasingly heterogeneous system landscape in modern high performance computing requires the efficient and portable adaption of performant algorithms to diverse architectures. However, classic hybrid shared-memory/distributed systems are designed and tuned towards specific platforms, thus impeding development, usage and optimization of these approaches with respect to portability. We demonstrate a flexible parallel rendering framework built upon a task-based dynamic runtime environment enabling adaptable performance-oriented deployment on various platform configurations. Our task definition represents an effective and easy-to-control trade-off between sort-first and sort-last image compositing, enabling good scalability in combination with inherent dynamic load balancing. We conduct comprehensive benchmarks to verify the characteristics and potential of our novel task-based system design for high-performance visualization.
@inproceedings {Biedert2017,
booktitle = {Eurographics Symposium on Parallel Graphics and Visualization},
title = {{A Task-Based Parallel Rendering Component For Large-Scale Visualization Applications}},
author = {Biedert, Tim and Werner, Kilian and Hentschel, Bernd and Garth, Christoph},
year = {2017},
pages = {63--71},
ISSN = {1727-348X},
ISBN = {978-3-03868-034-5},
DOI = {10.2312/pgv.20171094}
}
Measuring Insight into Multi-dimensional Data from a Combination of a Scatterplot Matrix and a HyperSlice Visualization
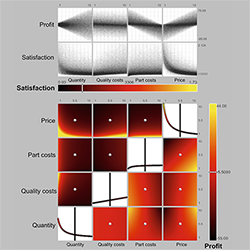
Understanding multi-dimensional data and in particular multi-dimensional dependencies is hard. Information visualization can help to understand this type of data. Still, the problem of how users gain insights from such visualizations is not well understood. Both the visualizations and the users play a role in understanding the data. In a case study, using both, a scatterplot matrix and a HyperSlice with six-dimensional data, we asked 16 participants to think aloud and measured insights during the process of analyzing the data. The amount of insights was strongly correlated with spatial abilities. Interestingly, all users were able to complete an optimization task independently of self-reported understanding of the data.
@Inbook{CaleroValdez2017,
author="Calero Valdez, Andr{\'e}
and Gebhardt, Sascha
and Kuhlen, Torsten W.
and Ziefle, Martina",
editor="Duffy, Vincent G.",
title="Measuring Insight into Multi-dimensional Data from a Combination of a Scatterplot Matrix and a HyperSlice Visualization",
bookTitle="Digital Human Modeling. Applications in Health, Safety, Ergonomics, and Risk Management: Health and Safety: 8th International Conference, DHM 2017, Held as Part of HCI International 2017, Vancouver, BC, Canada, July 9-14, 2017, Proceedings, Part II",
year="2017",
publisher="Springer International Publishing",
address="Cham",
pages="225--236",
isbn="978-3-319-58466-9",
doi="10.1007/978-3-319-58466-9_21",
url="http://dx.doi.org/10.1007/978-3-319-58466-9_21"
}
Interactive Level-of-Detail Visualization of 3D-Polarized Light Imaging Data Using Spherical Harmonics
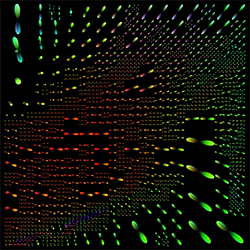
3D-Polarized Light Imaging (3D-PLI) provides data that enables an exploration of brain fibers at very high resolution. However, the visualization poses several challenges. Beside the huge data set sizes, users have to visually perceive the pure amount of information which might be, among other aspects, inhibited for inner structures because of occlusion by outer layers of the brain. We propose a clustering of fiber directions by means of spherical harmonics using a level-of-detail structure by which the user can interactively choose a clustering degree according to the zoom level or details required. Furthermore, the clustering method can be used for the automatic grouping of similar spherical harmonics automatically into one representative. An optional overlay with a direct vector visualization of the 3D-PLI data provides a better anatomical context.
Honorable Mention for Best Short Paper!
@inproceedings {Haenel2017Interactive,
booktitle = {EuroVis 2017 - Short Papers},
editor = {Barbora Kozlikova and Tobias Schreck and Thomas Wischgoll},
title = {{Interactive Level-of-Detail Visualization of 3D-Polarized Light Imaging Data Using Spherical Harmonics}},
author = {H\”anel, Claudia and Demiralp, Ali C. and Axer, Markus and Gr\”assel, David and Hentschel, Bernd and Kuhlen, Torsten W.},
year = {2017},
publisher = {The Eurographics Association},
ISBN = {978-3-03868-043-7},
DOI = {10.2312/eurovisshort.20171145}
}
A Micropolar Material Model for Turbulent SPH Fluids

In this paper we introduce a novel micropolar material model for the simulation of turbulent inviscid fluids. The governing equations are solved by using the concept of Smoothed Particle Hydrodynamics (SPH). As already investigated in previous works, SPH fluid simulations suffer from numerical diffusion which leads to a lower vorticity, a loss in turbulent details and finally in less realistic results. To solve this problem we propose a micropolar fluid model. The micropolar fluid model is a generalization of the classical Navier-Stokes equations, which are typically used in computer graphics to simulate fluids. In contrast to the classical Navier-Stokes model, micropolar fluids have a microstructure and therefore consider the rotational motion of fluid particles. In addition to the linear velocity field these fluids also have a field of microrotation which represents existing vortices and provides a source for new ones. However, classical micropolar materials are viscous and the translational and the rotational motion are coupled in a dissipative way. Since our goal is to simulate turbulent fluids, we introduce a novel modified micropolar material for inviscid fluids with a non-dissipative coupling. Our model can generate realistic turbulences, is linear and angular momentum conserving, can be easily integrated in existing SPH simulation methods and its computational overhead is negligible.
@INPROCEEDINGS{Bender2017,
author = {Jan Bender and Dan Koschier and Tassilo Kugelstadt and Marcel Weiler},
title = {A Micropolar Material Model for Turbulent SPH Fluids},
booktitle = {Proceedings of the 2017 ACM SIGGRAPH/Eurographics Symposium on Computer
Animation},
year = {2017},
publisher = {ACM}
}
Density Maps for Improved SPH Boundary Handling

In this paper, we present the novel concept of density maps for robust handling of static and rigid dynamic boundaries in fluid simulations based on Smoothed Particle Hydrodynamics (SPH). In contrast to the vast majority of existing approaches, we use an implicit discretization for a continuous extension of the density field throughout solid boundaries. Using the novel representation we enhance accuracy and efficiency of density and density gradient evaluations in boundary regions by computationally efficient lookups into our density maps. The map is generated in a preprocessing step and discretizes the density contribution in the boundary's near-field. In consequence of the high regularity of the continuous boundary density field, we use cubic Lagrange polynomials on a narrow-band structure of a regular grid for discretization. This strategy not only removes the necessity to sample boundary surfaces with particles but also decouples the particle size from the number of sample points required to represent the boundary. Moreover, it solves the ever-present problem of particle deficiencies near the boundary. In several comparisons we show that the representation is more accurate than particle samplings, especially for smooth curved boundaries. We further demonstrate that our approach robustly handles scenarios with highly complex boundaries and even outperforms one of the most recent sampling based techniques.
@InProceedings{KB17,
author = {Dan Koschier and Jan Bender},
title = {Density Maps for Improved SPH Boundary Handling},
booktitle = {Proceedings of the 2017 ACM SIGGRAPH/Eurographics Symposium on Computer Animation},
year = {2017},
series = {SCA '17},
pages = {1--10},
publisher = {ACM}
}
A Survey on Position Based Dynamics, 2017

The physically-based simulation of mechanical effects has been an important research topic in computer graphics for more than two decades. Classical methods in this field discretize Newton's second law and determine different forces to simulate various effects like stretching, shearing, and bending of deformable bodies or pressure and viscosity of fluids, to mention just a few. Given these forces, velocities and finally positions are determined by a numerical integration of the resulting accelerations. In the last years position-based simulation methods have become popular in the graphics community. In contrast to classical simulation approaches these methods compute the position changes in each simulation step directly, based on the solution of a quasi-static problem. Therefore, position-based approaches are fast, stable and controllable which make them well-suited for use in interactive environments. However, these methods are generally not as accurate as force-based methods but provide visual plausibility. Hence, the main application areas of position-based simulation are virtual reality, computer games and special effects in movies and commercials. In this tutorial we first introduce the basic concept of position-based dynamics. Then we present different solvers and compare them with the variational formulation of the implicit Euler method in connection with compliant constraints. We discuss approaches to improve the convergence of these solvers. Moreover, we show how position-based methods are applied to simulate elastic rods, cloth, volumetric deformable bodies, rigid body systems and fluids. We also demonstrate how complex effects like anisotropy or plasticity can be simulated and introduce approaches to improve the performance. Finally, we give an outlook and discuss open problems.
@inproceedings {BMM2017,
title = "A Survey on Position Based Dynamics, 2017",
author = "Jan Bender and Matthias M{\"u}ller and Miles Macklin",
year = "2017",
booktitle = "EUROGRAPHICS 2017 Tutorials",
publisher = "Eurographics Association"
}
DROW: Real-Time Deep Learning based Wheelchair Detection in 2D Range Data
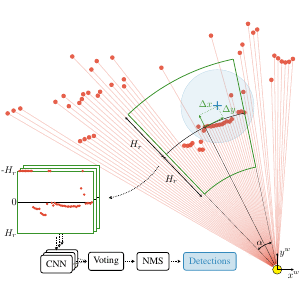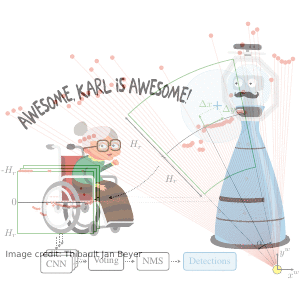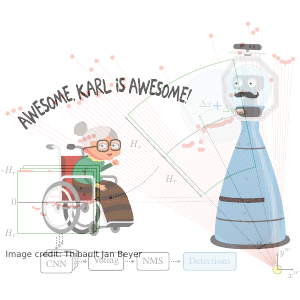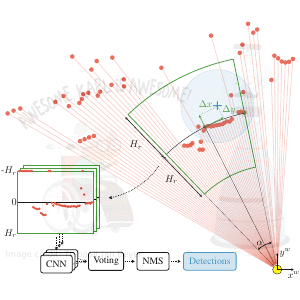
TL;DR: Collected & annotated laser detection dataset. Use window around each point to cast vote on detection center.
We introduce the DROW detector, a deep learning based detector for 2D range data. Laser scanners are lighting invariant, provide accurate range data, and typically cover a large field of view, making them interesting sensors for robotics applications. So far, research on detection in laser range data has been dominated by hand-crafted features and boosted classifiers, potentially losing performance due to suboptimal design choices. We propose a Convolutional Neural Network (CNN) based detector for this task. We show how to effectively apply CNNs for detection in 2D range data, and propose a depth preprocessing step and voting scheme that significantly improve CNN performance. We demonstrate our approach on wheelchairs and walkers, obtaining state of the art detection results. Apart from the training data, none of our design choices limits the detector to these two classes, though. We provide a ROS node for our detector and release our dataset containing 464k laser scans, out of which 24k were annotated.
@article{BeyerHermans2016RAL,
title = {{DROW: Real-Time Deep Learning based Wheelchair Detection in 2D Range Data}},
author = {Beyer*, Lucas and Hermans*, Alexander and Leibe, Bastian},
journal = {{IEEE Robotics and Automation Letters (RA-L)}},
year = {2016}
}
Comparison of a speech-based and a pie-menu-based interaction metaphor for application control
Choosing an adequate system control technique is crucial to support complex interaction scenarios in virtual reality applications. In this work, we compare an existing hierarchical pie-menu-based approach with a speech-recognition-based one in terms of task performance and user experience in a formal user study. As testbed, we use a factory planning application featuring a large set of system control options.
@INPROCEEDINGS{Pick:691795,
author = {Pick, Sebastian and Puika, Andrew S. and Kuhlen, Torsten},
title = {{C}omparison of a speech-based and a pie-menu-based
interaction metaphor for application control},
address = {Piscataway, NJ},
publisher = {IEEE},
reportid = {RWTH-2017-06169},
pages = {381-382},
year = {2017},
comment = {2017 IEEE Virtual Reality (VR) : proceedings : March 18-22,
2017, Los Angeles, CA, USA / Evan Suma Rosenberg, David M.
Krum, Zachary Wartell, Betty Mohler, Sabarish V. Babu, Frank
Steinicke, and Victoria Interrante ; sponsored by IEEE
Computer Society, Visialization and Graphics Technical
Committee},
booktitle = {2017 IEEE Virtual Reality (VR) :
proceedings : March 18-22, 2017, Los
Angeles, CA, USA / Evan Suma Rosenberg,
David M. Krum, Zachary Wartell, Betty
Mohler, Sabarish V. Babu, Frank
Steinicke, and Victoria Interrante ;
sponsored by IEEE Computer Society,
Visialization and Graphics Technical
Committee},
month = {Mar},
date = {2017-03-18},
organization = {2017 IEEE Virtual Reality, Los
Angeles, CA (USA), 18 Mar 2017 - 22 Mar
2017},
cin = {124620 / 120000 / 080025},
cid = {$I:(DE-82)124620_20151124$ / $I:(DE-82)120000_20140620$ /
$I:(DE-82)080025_20140620$},
pnm = {B-1 - Virtual Production Intelligence},
pid = {G:(DE-82)X080025-B-1},
typ = {PUB:(DE-HGF)7 / PUB:(DE-HGF)8},
UT = {WOS:000403149400114},
doi = {10.1109/VR.2017.7892336},
url = {http://publications.rwth-aachen.de/record/691795},
}
buenoSDIAs: Supporting Desktop Immersive Analytics While Actively Preventing Cybersickness

Immersive data analytics as an emerging research topic in scientific and information visualization has recently been brought back into the focus due to the emergence of low-cost consumer virtual reality hardware. Previous research has shown the positive impact of immersive visualization on data analytics workflows, but in most cases, insights were based on large-screen setups. In contrast, less research focuses on a close integration of immersive technology into existing, i.e., desktop-based data analytics workflows. This implies specific requirements regarding the usability of such systems, which include, i.e., the prevention of cybersickness. In this work, we present a prototypical application, which offers a first set of tools and addresses major challenges for a fully immersive data analytics setting in which the user is sitting at a desktop. In particular, we address the problem of cybersickness by integrating prevention strategies combined with individualized user profiles to maximize time of use.
Online Adaptation of Convolutional Neural Networks for the 2017 DAVIS Challenge on Video Object Segmentation
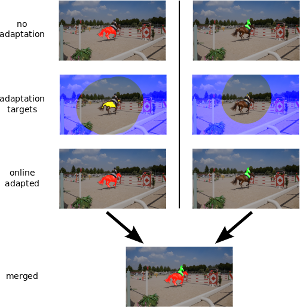
This paper describes our method used for the 2017 DAVIS Challenge on Video Object Segmentation [26]. The challenge’s task is to segment the pixels belonging to multiple objects in a video using the ground truth pixel masks, which are given for the first frame. We build on our recently proposed Online Adaptive Video Object Segmentation (OnAVOS) method which pretrains a convolutional neural network for objectness, fine-tunes it on the first frame, and further updates the network online while processing the video. OnAVOS selects confidently predicted foreground pixels as positive training examples and pixels, which are far away from the last assumed object position as negative examples. While OnAVOS was designed to work with a single object, we extend it to handle multiple objects by combining the predictions of multiple single-object runs. We introduce further extensions including upsampling layers which increase the output resolution. We achieved the fifth place out of 22 submissions to the competition.
@article{voigtlaender17DAVIS,
author = {Paul Voigtlaender and Bastian Leibe},
title = {Online Adaptation of Convolutional Neural Networks for the 2017 DAVIS Challenge on Video Object Segmentation},
journal = {The 2017 DAVIS Challenge on Video Object Segmentation - CVPR Workshops},
year = {2017}
}
Utilizing Immersive Virtual Reality in Everyday Work
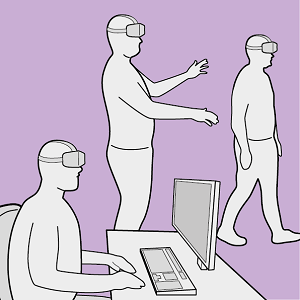
Applications of Virtual Reality (VR) have been repeatedly explored with the goal to improve the data analysis process of users from different application domains, such as architecture and simulation sciences. Unfortunately, making VR available in professional application scenarios or even using it on a regular basis has proven to be challenging. We argue that everyday usage environments, such as office spaces, have introduced constraints that critically affect the design of interaction concepts since well-established techniques might be difficult to use. In our opinion, it is crucial to understand the impact of usage scenarios on interaction design, to successfully develop VR applications for everyday use. To substantiate our claim, we define three distinct usage scenarios in this work that primarily differ in the amount of mobility they allow for. We outline each scenario's inherent constraints but also point out opportunities that may be used to design novel, well-suited interaction techniques for different everyday usage environments. In addition, we link each scenario to a concrete application example to clarify its relevance and show how it affects interaction design.
Efficient Approximate Computation of Scene Visibility Based on Navigation Meshes and Applications for Navigation and Scene Analysis
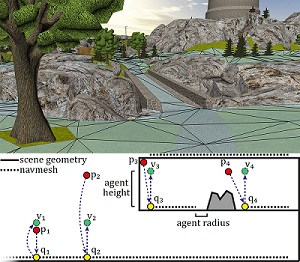
Scene visibility - the information of which parts of the scene are visible from a certain location—can be used to derive various properties of a virtual environment. For example, it enables the computation of viewpoint quality to determine the informativeness of a viewpoint, helps in constructing virtual tours, and allows to keep track of the objects a user may already have seen. However, computing visibility at runtime may be too computationally expensive for many applications, while sampling the entire scene beforehand introduces a costly precomputation step and may include many samples not needed later on.
Therefore, in this paper, we propose a novel approach to precompute visibility information based on navigation meshes, a polygonal representation of a scene’s navigable areas. We show that with only limited precomputation, high accuracy can be achieved in these areas. Furthermore, we demonstrate the usefulness of the approach by means of several applications, including viewpoint quality computation, landmark and room detection, and exploration assistance. In addition, we present a travel interface based on common visibility that we found to result in less cybersickness in a user study.
@INPROCEEDINGS{freitag2017a,
author={Sebastian Freitag and Benjamin Weyers and Torsten W. Kuhlen},
booktitle={2017 IEEE Symposium on 3D User Interfaces (3DUI)},
title={{Efficient Approximate Computation of Scene Visibility Based on Navigation Meshes and Applications for Navigation and Scene Analysis}},
year={2017},
pages={134--143},
}
Approximating Optimal Sets of Views in Virtual Scenes

Viewpoint quality estimation methods allow the determination of the most informative position in a scene. However, a single position usually cannot represent an entire scene, requiring instead a set of several viewpoints. Measuring the quality of such a set of views, however, is not trivial, and the computation of an optimal set of views is an NP-hard problem. Therefore, in this work, we propose three methods to estimate the quality of a set of views. Furthermore, we evaluate three approaches for computing an approximation to the optimal set (two of them new) regarding effectiveness and efficiency.
Assisted Travel Based on Common Visibility and Navigation Meshes

The manual adjustment of travel speed to cover medium or large distances in virtual environments may increase cognitive load, and manual travel at high speeds can lead to cybersickness due to inaccurate steering. In this work, we present an approach to quickly pass regions where the environment does not change much, using automated suggestions based on the computation of common visibility. In a user study, we show that our method can reduce cybersickness when compared with manual speed control.
BlowClick 2.0: A Trigger Based on Non-Verbal Vocal Input
The use of non-verbal vocal input (NVVI) as a hand-free trigger approach has proven to be valuable in previous work [Zielasko2015]. Nevertheless, BlowClick's original detection method is vulnerable to false positives and, thus, is limited in its potential use, e.g., together with acoustic feedback for the trigger. Therefore, we extend the existing approach by adding common machine learning methods. We found that a support vector machine (SVM) with Gaussian kernel performs best for detecting blowing with at least the same latency and more precision as before. Furthermore, we added acoustic feedback to the NVVI trigger, which increases the user's confidence. To evaluate the advanced trigger technique, we conducted a user study (n=33). The results confirm that it is a reliable trigger; alone and as part of a hands-free point-and-click interface.
A Reliable Non-Verbal Vocal Input Metaphor for Clicking

We extended BlowClick, a NVVI metaphor for clicking, by adding machine learning methods to more reliably classify blowing events. We found a support vector machine with Gaussian kernel performing the best with at least the same latency and more precision than before. Furthermore, we added acoustic feedback to the NVVI trigger, which increases the user's confidence. With this extended technique we conducted a user study with 33 participants and could confirm that it is possible to use NVVI as a reliable trigger as part of a hands-free point-and-click interface.
Remain Seated: Towards Fully-Immersive Desktop VR
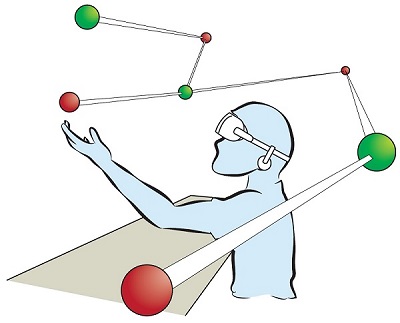
In this work we describe the scenario of fully-immersive desktop VR, which serves the overall goal to seamlessly integrate with existing workflows and workplaces of data analysts and researchers, such that they can benefit from the gain in productivity when immersed in their data-spaces. Furthermore, we provide a literature review showing the status quo of techniques and methods available for realizing this scenario under the raised restrictions. Finally, we propose a concept of an analysis framework and the decisions made and the decisions still to be taken, to outline how the described scenario and the collected methods are feasible in a real use case.
Evaluation of Approaching-Strategies of Temporarily Required Virtual Assistants in Immersive Environments

Embodied, virtual agents provide users assistance in agent-based support systems. To this end, two closely linked factors have to be considered for the agents’ behavioral design: their presence time (PT), i.e., the time in which the agents are visible, and the approaching time (AT), i.e., the time span between the user’s calling for an agent and the agent’s actual availability.
This work focuses on human-like assistants that are embedded in immersive scenes but that are required only temporarily. To the best of our knowledge, guidelines for a suitable trade-off between PT and AT of these assistants do not yet exist. We address this gap by presenting the results of a controlled within-subjects study in a CAVE. While keeping a low PT so that the agent is not perceived as annoying, three strategies affecting the AT, namely fading, walking, and running, are evaluated by 40 subjects. The results indicate no clear preference for either behavior. Instead, the necessity of a better trade-off between a low AT and an agent’s realistic behavior is demonstrated.
@InProceedings{Boensch2017b,
Title = {Evaluation of Approaching-Strategies of Temporarily Required Virtual Assistants in Immersive Environments},
Author = {Andrea B\"{o}nsch and Tom Vierjahn and Torsten W. Kuhlen},
Booktitle = {IEEE Symposium on 3D User Interfaces},
Year = {2017},
Pages = {69-72}
}
From Monocular SLAM to Autonomous Drone Exploration
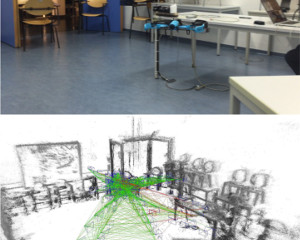
Micro aerial vehicles (MAVs) are strongly limited in their payload and power capacity. In order to implement autonomous navigation, algorithms are therefore desirable that use sensory equipment that is as small, low-weight, and low- power consuming as possible. In this paper, we propose a method for autonomous MAV navigation and exploration using a low-cost consumer-grade quadrocopter equipped with a monocular camera. Our vision-based navigation system builds on LSD-SLAM which estimates the MAV trajectory and a semi-dense reconstruction of the environment in real-time. Since LSD-SLAM only determines depth at high gradient pixels, texture-less areas are not directly observed. We propose an obstacle mapping and exploration approach that takes this property into account. In experiments, we demonstrate our vision-based autonomous navigation and exploration system with a commercially available Parrot Bebop MAV.
@inproceedings{stumberg2017_mavexplore,
author={Lukas von Stumberg and Vladyslav Usenko and Jakob Engel and J\"org St\"uckler and Daniel Cremers},
title={From Monoular {SLAM} to Autonomous Drone Exploration},
booktitle = {Accepted for the European Conference on Mobile Robots (ECMR)},
year = {2017},
}
Gistualizer: An Immersive Glyph for Multidimensional Datapoints

Data from diverse workflows is often too complex for an adequate analysis without visualization. One kind of data are multi-dimensional datasets, which can be visualized via a wide array of techniques. For instance, glyphs can be used to visualize individual datapoints. However, glyphs need to be actively looked at to be comprehended. This work explores a novel approach towards visualizing a single datapoint, with the intention of increasing the user’s awareness of it while they are looking at something else. The basic concept is to represent this point by a scene that surrounds the user in an immersive virtual environment. This idea is based on the observation that humans can extract low-detailed information, the so-called gist, from a scene nearly instantly (equal or less 100ms). We aim at providing a first step towards answering the question whether enough information can be encoded in the gist of a scene to represent a point in multi-dimensional space and if this information is helpful to the user’s understanding of this space.
@inproceedings{Bellgardt2017,
author = {Bellgardt, Martin and Gebhardt, Sascha and Hentschel, Bernd and Kuhlen, Torsten W.},
booktitle = {Workshop on Immersive Analytics},
title = {{Gistualizer: An Immersive Glyph for Multidimensional Datapoints}},
year = {2017}
}
Turning Anonymous Members of a Multiagent System into Individuals
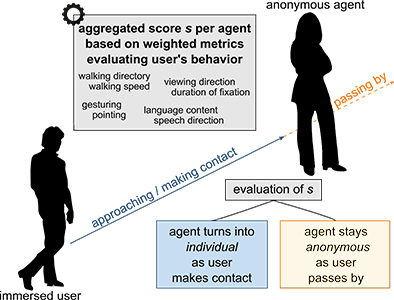
It is increasingly common to embed embodied, human-like, virtual agents into immersive virtual environments for either of the two use cases: (1) populating architectural scenes as anonymous members of a crowd and (2) meeting or supporting users as individual, intelligent and conversational agents. However, the new trend towards intelligent cyber physical systems inherently combines both use cases. Thus, we argue for the necessity of multiagent systems consisting of anonymous and autonomous agents, who temporarily turn into intelligent individuals. Besides purely enlivening the scene, each agent can thus be engaged into a situation-dependent interaction by the user, e.g., into a conversation or a joint task. To this end, we devise components for an agent’s behavioral design modeling the transition between an anonymous and an individual agent when a user approaches.
@InProceedings{Boensch2017c,
Title = {{Turning Anonymous Members of a Multiagent System into Individuals}},
Author = {Andrea B\"{o}nsch, Tom Vierjahn, Ari Shapiro and Torsten W. Kuhlen},
Booktitle = {IEEE Virtual Humans and Crowds for Immersive Environments},
Year = {2017},
Keywords = {Virtual Humans; Virtual Reality; Intelligent Agents; Mutliagent System},
DOI ={ 10.1109/VHCIE.2017.7935620}
Owner = {ab280112},
Timestamp = {2017.02.28}
}
3D Semantic Segmentation of Modular Furniture using rjMCMC
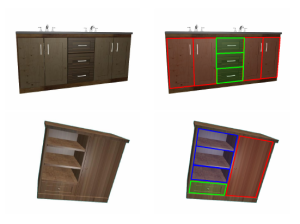
In this paper we propose a novel approach to identify and label the structural elements of furniture e.g. wardrobes, cabinets etc. Given a furniture item, the subdivision into its structural components like doors, drawers and shelves is difficult as the number of components and their spatial arrangements varies severely. Furthermore, structural elements are primarily distinguished by their function rather than by unique color or texture based appearance features. It is therefore difficult to classify them, even if their correct spatial extent were known. In our approach we jointly estimate the number of functional units, their spatial structure, and their corresponding labels by using reversible jump MCMC (rjMCMC), a method well suited for optimization on spaces of varying dimensions (the number of structural elements). Optionally, our system permits to invoke depth information e.g. from RGB-D cameras, which are already frequently mounted on mobile robot platforms. We show a considerable improvement over a baseline method even without using depth data, and an additional performance gain when depth input is enabled.
@inproceedings{badamiWACV17,
title={3D Semantic Segmentation of Modular Furniture using rjMCMC
},
author={Badami, Ishrat and Tom, Manu and Mathias, Markus and Leibe, Bastian},
booktitle={WACV},
year={2017}
}
Poster: Score-Based Recommendation for Efficiently Selecting Individual Virtual Agents in Multi-Agent Systems
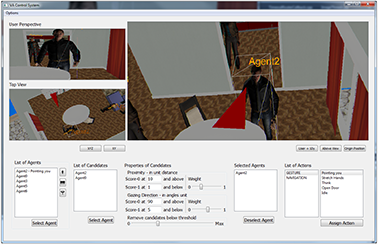
Controlling user-agent-interactions by means of an external operator includes selecting the virtual interaction partners fast and faultlessly. However, especially in immersive scenes with a large number of potential partners, this task is non-trivial.
Thus, we present a score-based recommendation system supporting an operator in the selection task. Agents are recommended as potential partners based on two parameters: the user’s distance to the agents and the user’s gazing direction. An additional graphical user interface (GUI) provides elements for configuring the system and for applying actions to those agents which the operator has confirmed as interaction partners.
@InProceedings{Boensch2017d,
Title = {Score-Based Recommendation for Efficiently Selecting Individual
Virtual Agents in Multi-Agent Systems},
Author = {Andrea Bönsch and Robert Trisnadi and Jonathan Wendt and Tom Vierjahn, and Torsten
W. Kuhlen},
Booktitle = {Proceedings of 23rd ACM
Symposium on Virtual Reality Software and Technology},
Year = {2017},
Pages = {tba},
DOI={10.1145/3139131.3141215}
}
Poster: Towards a Design Space Characterizing Workflows that Take Advantage of Immersive Visualization
Immersive visualization (IV) fosters the creation of mental images of a data set, a scene, a procedure, etc. We devise an initial version of a design space for categorizing workflows that take advantage of IV. From this categorization, specific requirements for seamlessly integrating IV can be derived. We validate the design space with three workflows emerging from our research projects.
@InProceedings{Vierjahn2017,
Title = {Towards a Design Space Characterizing Workflows that Take Advantage of Immersive Visualization},
Author = {Tom Vierjahn and Daniel Zielasko and Kees van Kooten and Peter Messmer and Bernd Hentschel and Torsten W. Kuhlen and Benjamin Weyers},
Booktitle = {IEEE Virtual Reality Conference Poster Proceedings},
Year = {2017},
Pages = {329-330},
DOI={10.1109/VR.2017.7892310}
}
Poster: Peers At Work: Economic Real-Effort Experiments In The Presence of Virtual Co-Workers

Traditionally, experimental economics uses controlled and incentivized field and lab experiments to analyze economic behavior. However, investigating peer effects in the classic settings is challenging due to the reflection problem: Who is influencing whom?
To overcome this, we enlarge the methodological toolbox of these experiments by means of Virtual Reality. After introducing and validating a real-effort sorting task, we embed a virtual agent as peer of a human subject, who independently performs an identical sorting task. We conducted two experiments investigating (a) the subject’s productivity adjustment due to peer effects and (b) the incentive effects on competition. Our results indicate a great potential for Virtual-Reality-based economic experiments.
@InProceedings{Boensch2017a,
Title = {Peers At Work: Economic Real-Effort Experiments In The Presence of Virtual Co-Workers},
Author = {Andrea B\"{o}nsch and Jonathan Wendt and Heiko Overath and Özgür Gürerk and Christine Harbring and Christian Grund and Thomas Kittsteiner and Torsten W. Kuhlen},
Booktitle = {IEEE Virtual Reality Conference Poster Proceedings},
Year = {2017},
Pages = {301-302},
DOI = {10.1109/VR.2017.7892296}
}
A Collaborative Simulation-Analysis Workflow for Computational Neuroscience Using HPC
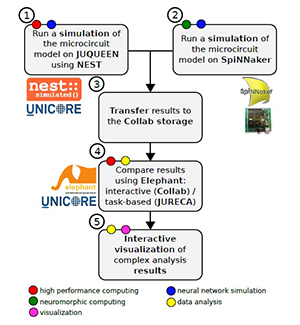
Workflows for the acquisition and analysis of data in the natural sciences exhibit a growing degree of complexity and heterogeneity, are increasingly performed in large collaborative efforts, and often require the use of high-performance computing (HPC). Here, we explore the reasons for these new challenges and demands and discuss their impact, with a focus on the scientific domain of computational neuroscience. We argue for the need for software platforms integrating HPC systems that allow scientists to construct, comprehend and execute workflows composed of diverse processing steps using different tools. As a use case we present a concrete implementation of such a complex workflow, covering diverse topics such as HPC-based simulation using the NEST software, access to the SpiNNaker neuromorphic hardware platform, complex data analysis using the Elephant library, and interactive visualizations. Tools are embedded into a web-based software platform under development by the Human Brain Project, called Collaboratory. On the basis of this implementation, we discuss the state-of-the-art and future challenges in constructing large, collaborative workflows with access to HPC resources.
Virtual Production Intelligence

The research area Virtual Production Intelligence (VPI) focuses on the integrated support of collaborative planning processes for production systems and products. The focus of the research is on processes for information processing in the design domains Factory and Machine. These processes provide the integration and interactive analysis of emerging, mostly heterogeneous planning information. The demonstrators (flapAssist, memoSlice und VPI platform) that are Information systems serve for the validation of the scientific approaches and aim to realize a continuous and consistent information management in terms of the Digital Factory. Central challenges are the semantic information integration (e.g., by means of metamodelling), the subsequent evaluation as well as the visualization of planning information (e.g., by means of Visual Analytics and Virtual Reality). All scientific and technical work is done within an interdisciplinary team composed of engineers, computer scientists and physicists.
@BOOK{Brecher:683508,
key = {683508},
editor = {Brecher, Christian and Özdemir, Denis},
title = {{I}ntegrative {P}roduction {T}echnology : {T}heory and
{A}pplications},
address = {Cham},
publisher = {Springer International Publishing},
reportid = {RWTH-2017-01369},
isbn = {978-3-319-47451-9},
pages = {XXXIX, 1100 Seiten : Illustrationen},
year = {2017},
cin = {417310 / 080025},
cid = {$I:(DE-82)417310_20140620$ / $I:(DE-82)080025_20140620$},
typ = {PUB:(DE-HGF)3},
doi = {10.1007/978-3-319-47452-6},
url = {http://publications.rwth-aachen.de/record/683508},
}
Do Not Invade: A Virtual-Reality-Framework to Study Personal Space
The bachelor thesis’ aim was to develop a framework allowing to design and conduct virtual-reality-based user studies gaining insight into the concept of personal space.
@Article{Schnathmeier2017,
Title = {Do Not Invade: A Virtual-Reality-Framework to Study Personal Space},
Author = {Jan Schnathmeier and Heiko Overath and Sina Radke and Andrea B\"{o}nsch and Ute Habel and Torsten W. Kuhlen},
Journal = {{V}irtuelle und {E}rweiterte {R}ealit\"at, 14. {W}orkshop der {GI}-{F}achgruppe {VR}/{AR}},
Year = {2017},
Pages = {203-204},
ISBN = {978-3-8440-5606-8}
Publisher = {Shaker Verlag}
}
Towards a Principled Integration of Multi-Camera Re-Identification and Tracking through Optimal Bayes Filters
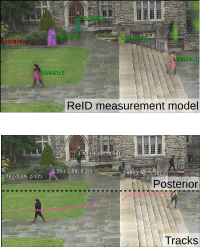
TL;DR: Explorative paper. Learn a Triplet-ReID net, embed the full image. Keep embeddings of known tracks, correlate them with image embeddings and use that as measurement model in a Bayesian filtering tracker. MOT score is mediocre, but framework is theoretically pleasing.
With the rise of end-to-end learning through deep learning, person detectors and re-identification (ReID) models have recently become very strong. Multi-camera multi-target (MCMT) tracking has not fully gone through this transformation yet. We intend to take another step in this direction by presenting a theoretically principled way of integrating ReID with tracking formulated as an optimal Bayes filter. This conveniently side-steps the need for data-association and opens up a direct path from full images to the core of the tracker. While the results are still sub-par, we believe that this new, tight integration opens many interesting research opportunities and leads the way towards full end-to-end tracking from raw pixels.
@article{BeyerBreuers2017Arxiv,
author = {Lucas Beyer and
Stefan Breuers and
Vitaly Kurin and
Bastian Leibe},
title = {{Towards a Principled Integration of Multi-Camera Re-Identification
and Tracking through Optimal Bayes Filters}},
journal = {{2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)}},
year = {2017},
pages ={1444-1453},
}
In Defense of the Triplet Loss for Person Re-Identification

TL;DR: Use triplet loss, hard-mining inside mini-batch performs great, is similar to offline semi-hard mining but much more efficient.
In the past few years, the field of computer vision has gone through a revolution fueled mainly by the advent of large datasets and the adoption of deep convolutional neural networks for end-to-end learning. The person re-identification subfield is no exception to this, thanks to the notable publication of the Market-1501 and MARS datasets and several strong deep learning approaches. Unfortunately, a prevailing belief in the community seems to be that the triplet loss is inferior to using surrogate losses (classification, verification) followed by a separate metric learning step. We show that, for models trained from scratch as well as pretrained ones, using a variant of the triplet loss to perform end-to-end deep metric learning outperforms any other published method by a large margin.
@article{HermansBeyer2017Arxiv,
title = {{In Defense of the Triplet Loss for Person Re-Identification}},
author = {Hermans*, Alexander and Beyer*, Lucas and Leibe, Bastian},
journal = {arXiv preprint arXiv:1703.07737},
year = {2017}
}
Previous Year (2016)
